Data-Augmentation-Based Dialectal Adaptation for LLMs
2404.08092
0
0
👨🏫
Abstract
This report presents GMUNLP's participation to the Dialect-Copa shared task at VarDial 2024, which focuses on evaluating the commonsense reasoning capabilities of large language models (LLMs) on South Slavic micro-dialects. The task aims to assess how well LLMs can handle non-standard dialectal varieties, as their performance on standard languages is already well-established. We propose an approach that combines the strengths of different types of language models and leverages data augmentation techniques to improve task performance on three South Slavic dialects: Chakavian, Cherkano, and Torlak. We conduct experiments using a language-family-focused encoder-based model (BERTi'c) and a domain-agnostic multilingual model (AYA-101). Our results demonstrate that the proposed data augmentation techniques lead to substantial performance gains across all three test datasets in the open-source model category. This work highlights the practical utility of data augmentation and the potential of LLMs in handling non-standard dialectal varieties, contributing to the broader goal of advancing natural language understanding in low-resource and dialectal settings. Code:https://github.com/ffaisal93/dialect_copa
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper presents a data-augmentation-based approach to adapt large language models (LLMs) for dialectal language processing.
- It focuses on the DIALECT-COPA shared task, which involves classifying code-switched utterances into different dialects.
- The proposed method leverages data augmentation techniques to generate diverse dialectal training examples, which are then used to fine-tune an LLM for the task.
Plain English Explanation
The paper discusses a way to improve how large language models (LLMs) - powerful AI systems that can understand and generate human-like text - can work with different dialects of a language. Dialects are variations of a language that can differ in things like pronunciation, vocabulary, and grammar.
The researchers looked at a specific task called the DIALECT-COPA shared task, where the goal is to take a sentence that mixes two different dialects (called "code-switching") and classify which dialects are present. To help the LLM perform this task better, the researchers used a technique called "data augmentation."
Data augmentation involves taking the existing training data and making small, artificial changes to it to create new, diverse examples. In this case, the researchers generated new training examples that sounded more like different dialects. This allowed them to fine-tune the LLM, or further train it, on this more diverse data.
The key idea is that by giving the LLM more exposure to different dialectal variations during training, it can learn to better recognize and classify those dialects when it encounters them later. This can help make LLMs more robust and adaptable when working with diverse language use, which is an important capability as these models become more widely deployed.
Technical Explanation
The paper focuses on the DIALECT-COPA shared task, where the goal is to classify code-switched utterances into different dialects. To address this challenge, the authors propose a data-augmentation-based approach to adapt large language models (LLMs) for dialectal language processing.
The key idea is to leverage data augmentation techniques to generate diverse dialectal training examples, which are then used to fine-tune an LLM for the DIALECT-COPA task. The authors experiment with various data augmentation methods, such as lexical substitution and sentence paraphrasing, to create synthetic training instances that capture different dialectal variations.
The authors then fine-tune a pre-trained LLM, such as BERT or RoBERTa, on the augmented training data and evaluate its performance on the DIALECT-COPA test set. The results show that the data-augmentation-based approach can significantly improve the LLM's dialectal adaptation capabilities, outperforming baseline models that do not use data augmentation.
Critical Analysis
The paper presents a promising approach to address the challenge of dialectal adaptation for LLMs, which is an important issue as these models become more widely deployed. The use of data augmentation to generate diverse dialectal training examples is a clever strategy, as it allows the model to learn from a richer set of linguistic variations without the need for additional data collection.
However, the paper does not provide a thorough analysis of the limitations of the proposed approach. For instance, it would be valuable to understand how the data augmentation techniques perform across different dialects or language pairs, and whether certain augmentation methods are more effective than others. Additionally, the paper does not explore the potential trade-offs between the quality of the generated dialectal examples and the model's performance on the target task.
Furthermore, the paper does not discuss the broader implications of this research, such as how it might inform the development of more inclusive and equitable language models that can better serve diverse user communities. Addressing these aspects in future work could further strengthen the impact of this research.
Conclusion
This paper presents a data-augmentation-based approach to adapt large language models for dialectal language processing, focusing on the DIALECT-COPA shared task. By leveraging data augmentation techniques to generate diverse dialectal training examples, the authors demonstrate that it is possible to fine-tune LLMs to better recognize and classify code-switched utterances.
The findings of this research have the potential to contribute to the development of more robust and adaptable language models that can handle the linguistic diversity present in real-world applications. As LLMs continue to be widely deployed, addressing dialectal adaptation will be crucial to ensure these technologies are inclusive and accessible to users from different linguistic backgrounds.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating Dialect Robustness of Language Models via Conversation Understanding
Dipankar Srirag, Aditya Joshi
0
0
With an evergrowing number of LLMs reporting superlative performance for English, their ability to perform equitably for different dialects of English (i.e., dialect robustness) needs to be ascertained. Specifically, we use English language (US English or Indian English) conversations between humans who play the word-guessing game of `taboo'. We formulate two evaluative tasks: target word prediction (TWP) (i.e.predict the masked target word in a conversation) and target word selection (TWS) (i.e., select the most likely masked target word in a conversation, from among a set of candidate words). Extending MD3, an existing dialectic dataset of taboo-playing conversations, we introduce M-MD3, a target-word-masked version of MD3 with the USEng and IndEng subsets. We add two subsets: AITrans (where dialectic information is removed from IndEng) and AIGen (where LLMs are prompted to generate conversations). Our evaluation uses pre-trained and fine-tuned versions of two closed-source (GPT-4/3.5) and two open-source LLMs (Mistral and Gemma). LLMs perform significantly better for US English than Indian English for both TWP and TWS, for all settings. While GPT-based models perform the best, the comparatively smaller models work more equitably for short conversations (<8 turns). Our results on AIGen and AITrans (the best and worst-performing subset) respectively show that LLMs may learn a dialect of their own based on the composition of the training data, and that dialect robustness is indeed a challenging task. Our evaluation methodology exhibits a novel way to examine attributes of language models using pre-existing dialogue datasets.
5/10/2024
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024
🌿
Natural Language Processing for Dialects of a Language: A Survey
Aditya Joshi, Raj Dabre, Diptesh Kanojia, Zhuang Li, Haolan Zhan, Gholamreza Haffari, Doris Dippold
0
0
State-of-the-art natural language processing (NLP) models are trained on massive training corpora, and report a superlative performance on evaluation datasets. This survey delves into an important attribute of these datasets: the dialect of a language. Motivated by the performance degradation of NLP models for dialectic datasets and its implications for the equity of language technologies, we survey past research in NLP for dialects in terms of datasets, and approaches. We describe a wide range of NLP tasks in terms of two categories: natural language understanding (NLU) (for tasks such as dialect classification, sentiment analysis, parsing, and NLU benchmarks) and natural language generation (NLG) (for summarisation, machine translation, and dialogue systems). The survey is also broad in its coverage of languages which include English, Arabic, German among others. We observe that past work in NLP concerning dialects goes deeper than mere dialect classification, and . This includes early approaches that used sentence transduction that lead to the recent approaches that integrate hypernetworks into LoRA. We expect that this survey will be useful to NLP researchers interested in building equitable language technologies by rethinking LLM benchmarks and model architectures.
4/1/2024
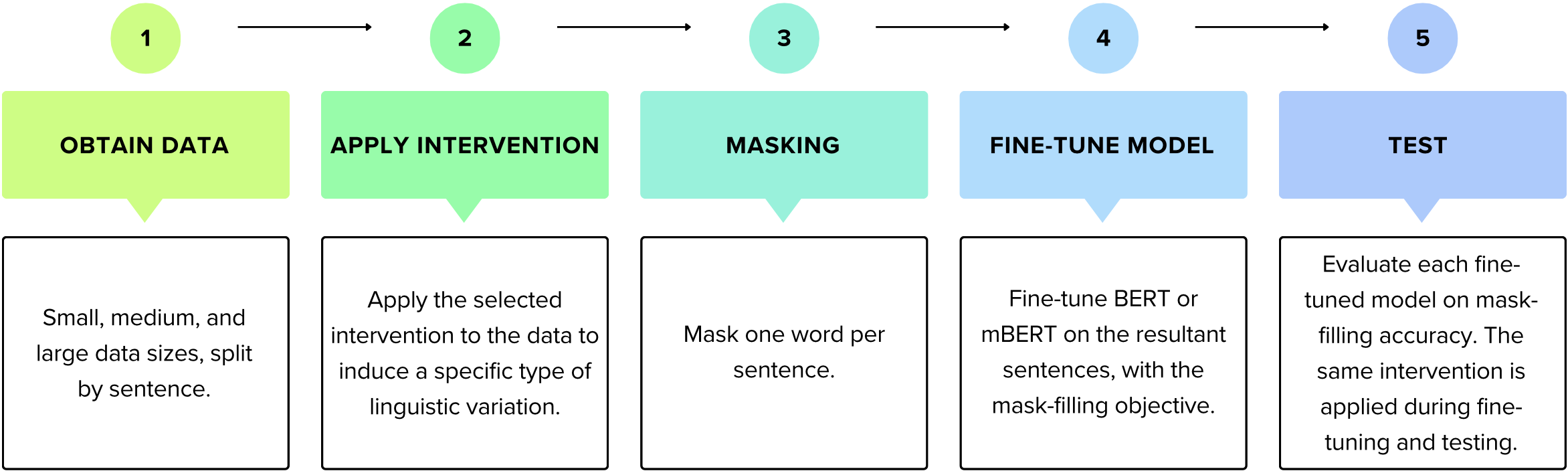
We're Calling an Intervention: Taking a Closer Look at Language Model Adaptation to Different Types of Linguistic Variation
Aarohi Srivastava, David Chiang
0
0
We present a suite of interventions and experiments that allow us to understand language model adaptation to text with linguistic variation (e.g., nonstandard or dialectal text). Our interventions address several features of linguistic variation, resulting in character, subword, and word-level changes. Applying our interventions during language model adaptation with varying size and nature of training data, we gain important insights into what makes linguistic variation particularly difficult for language models to deal with. For instance, on text with character-level variation, performance improves with even a few training examples but approaches a plateau, suggesting that more data is not the solution. In contrast, on text with variation involving new words or meanings, far more data is needed, but it leads to a massive breakthrough in performance. Our findings inform future work on dialectal NLP and making language models more robust to linguistic variation overall. We make the code for our interventions, which can be applied to any English text data, publicly available.
4/12/2024