Data Augmentation for Image Classification using Generative AI

0

Sign in to get full access
Overview
- This paper explores using generative AI models for data augmentation to improve image classification performance.
- The researchers propose a novel approach that leverages generative adversarial networks (GANs) to create diverse, semantically meaningful augmented images.
- Experiments on benchmark datasets show the proposed method outperforms traditional data augmentation techniques and other generative data augmentation approaches.
Plain English Explanation
Image classification is a fundamental task in computer vision, where the goal is to identify the objects or contents of an image. However, deep learning models for image classification often require large, diverse datasets to perform well. Data augmentation techniques are commonly used to artificially expand the training dataset by applying transformations like rotation, flipping, or scaling to existing images.
This paper explores using generative AI models, specifically generative adversarial networks (GANs), as a more advanced data augmentation approach. The key idea is that the GAN can learn the underlying data distribution and generate new, realistic-looking images that preserve the semantic content of the original images. This can help the classification model see a greater diversity of examples during training, potentially leading to better performance.
The researchers propose a novel GAN-based data augmentation method and evaluate it on popular image classification benchmarks. Their results show the proposed approach outperforms traditional data augmentation techniques as well as other state-of-the-art generative data augmentation methods. This suggests that leveraging generative AI models can be a powerful way to enhance image classification models by synthesizing high-quality, semantically relevant augmented data.
Technical Explanation
The paper introduces a novel GAN-based data augmentation framework for image classification. The core components are:
-
Generator Network: This is the generative part of the GAN that learns to produce new, realistic-looking images based on the training data. The generator takes in a random noise vector and outputs an augmented image.
-
Discriminator Network: This is the adversarial part of the GAN that tries to distinguish between real images from the training set and fake images generated by the generator.
-
Classification Network: This is the image classification model that the researchers want to improve through data augmentation. During training, the generator is optimized to produce images that can fool the discriminator while also improving the performance of the classification network.
The key technical contributions include:
- A novel GAN architecture and training objective that encourages the generator to produce diverse, semantically meaningful augmented images.
- Extensive experiments on benchmark image classification datasets (CIFAR-10, CIFAR-100, ImageNet) showing the proposed method outperforms traditional data augmentation and other GAN-based approaches.
- Ablation studies and qualitative analysis to better understand the strengths and limitations of the proposed approach.
Critical Analysis
The paper provides a compelling demonstration of how generative AI models can be leveraged for effective data augmentation in image classification. The researchers' proposed GAN-based framework shows strong empirical performance, outperforming simpler data augmentation techniques as well as other generative approaches.
However, the paper does not deeply explore the limitations or potential downsides of this approach. For example, it is unclear how the method would scale to large, high-resolution image datasets or how sensitive the performance is to hyperparameter tuning. Additionally, the paper does not address potential ethical concerns around the use of generative models to create synthetic training data.
Further research could also investigate the generalizability of this approach to other computer vision tasks beyond image classification, such as object detection or semantic segmentation. Exploring ways to make the data augmentation process more controllable or interpretable could also be a fruitful direction.
Overall, this paper makes a compelling case for the value of generative AI in boosting the performance of image classification models through data augmentation. But there remain open questions and avenues for improvement that future work could explore.
Conclusion
This paper presents a novel GAN-based data augmentation framework that leverages generative AI to create diverse, semantically meaningful augmented images for improving image classification performance. The empirical results demonstrate the proposed approach outperforms traditional data augmentation techniques as well as other state-of-the-art generative data augmentation methods.
The key innovation is the use of a GAN architecture that is jointly optimized to generate high-quality augmented images while also directly improving the target classification model. This allows the generative model to learn to produce augmented data that is tailored to the needs of the downstream classification task.
The findings in this paper suggest that generative AI can be a powerful tool for enhancing computer vision models by synthesizing high-quality, semantically relevant training data. As datasets and computational resources continue to grow, leveraging such generative approaches may become an increasingly important strategy for pushing the boundaries of image classification and other visual understanding capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data Augmentation for Image Classification using Generative AI
Fazle Rahat, M Shifat Hossain, Md Rubel Ahmed, Sumit Kumar Jha, Rickard Ewetz
Scaling laws dictate that the performance of AI models is proportional to the amount of available data. Data augmentation is a promising solution to expanding the dataset size. Traditional approaches focused on augmentation using rotation, translation, and resizing. Recent approaches use generative AI models to improve dataset diversity. However, the generative methods struggle with issues such as subject corruption and the introduction of irrelevant artifacts. In this paper, we propose the Automated Generative Data Augmentation (AGA). The framework combines the utility of large language models (LLMs), diffusion models, and segmentation models to augment data. AGA preserves foreground authenticity while ensuring background diversity. Specific contributions include: i) segment and superclass based object extraction, ii) prompt diversity with combinatorial complexity using prompt decomposition, and iii) affine subject manipulation. We evaluate AGA against state-of-the-art (SOTA) techniques on three representative datasets, ImageNet, CUB, and iWildCam. The experimental evaluation demonstrates an accuracy improvement of 15.6% and 23.5% for in and out-of-distribution data compared to baseline models, respectively. There is also a 64.3% improvement in SIC score compared to the baselines.
Read more9/4/2024

0
Enhanced Generative Data Augmentation for Semantic Segmentation via Stronger Guidance
Quang-Huy Che, Duc-Tri Le, Vinh-Tiep Nguyen
Data augmentation is a widely used technique for creating training data for tasks that require labeled data, such as semantic segmentation. This method benefits pixel-wise annotation tasks requiring much effort and intensive labor. Traditional data augmentation methods involve simple transformations like rotations and flips to create new images from existing ones. However, these new images may lack diversity along the main semantic axes in the data and not change high-level semantic properties. To address this issue, generative models have emerged as an effective solution for augmenting data by generating synthetic images. Controllable generative models offer a way to augment data for semantic segmentation tasks using a prompt and visual reference from the original image. However, using these models directly presents challenges, such as creating an effective prompt and visual reference to generate a synthetic image that accurately reflects the content and structure of the original. In this work, we introduce an effective data augmentation method for semantic segmentation using the Controllable Diffusion Model. Our proposed method includes efficient prompt generation using Class-Prompt Appending and Visual Prior Combination to enhance attention to labeled classes in real images. These techniques allow us to generate images that accurately depict segmented classes in the real image. In addition, we employ the class balancing algorithm to ensure efficiency when merging the synthetic and original images to generate balanced data for the training dataset. We evaluated our method on the PASCAL VOC datasets and found it highly effective for synthesizing images in semantic segmentation.
Read more9/14/2024

0
A Comprehensive Survey on Data Augmentation
Zaitian Wang, Pengfei Wang, Kunpeng Liu, Pengyang Wang, Yanjie Fu, Chang-Tien Lu, Charu C. Aggarwal, Jian Pei, Yuanchun Zhou
Data augmentation is a series of techniques that generate high-quality artificial data by manipulating existing data samples. By leveraging data augmentation techniques, AI models can achieve significantly improved applicability in tasks involving scarce or imbalanced datasets, thereby substantially enhancing AI models' generalization capabilities. Existing literature surveys only focus on a certain type of specific modality data, and categorize these methods from modality-specific and operation-centric perspectives, which lacks a consistent summary of data augmentation methods across multiple modalities and limits the comprehension of how existing data samples serve the data augmentation process. To bridge this gap, we propose a more enlightening taxonomy that encompasses data augmentation techniques for different common data modalities. Specifically, from a data-centric perspective, this survey proposes a modality-independent taxonomy by investigating how to take advantage of the intrinsic relationship between data samples, including single-wise, pair-wise, and population-wise sample data augmentation methods. Additionally, we categorize data augmentation methods across five data modalities through a unified inductive approach.
Read more5/20/2024
0
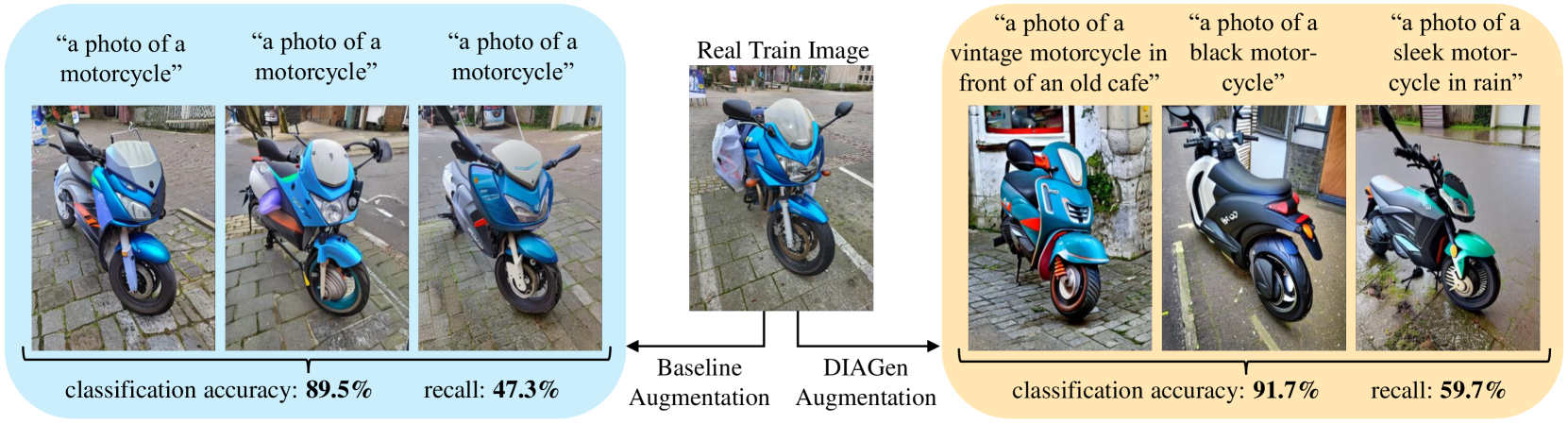
DIAGen: Diverse Image Augmentation with Generative Models
Tobias Lingenberg, Markus Reuter, Gopika Sudhakaran, Dominik Gojny, Stefan Roth, Simone Schaub-Meyer
Simple data augmentation techniques, such as rotations and flips, are widely used to enhance the generalization power of computer vision models. However, these techniques often fail to modify high-level semantic attributes of a class. To address this limitation, researchers have explored generative augmentation methods like the recently proposed DA-Fusion. Despite some progress, the variations are still largely limited to textural changes, thus falling short on aspects like varied viewpoints, environment, weather conditions, or even class-level semantic attributes (eg, variations in a dog's breed). To overcome this challenge, we propose DIAGen, building upon DA-Fusion. First, we apply Gaussian noise to the embeddings of an object learned with Textual Inversion to diversify generations using a pre-trained diffusion model's knowledge. Second, we exploit the general knowledge of a text-to-text generative model to guide the image generation of the diffusion model with varied class-specific prompts. Finally, we introduce a weighting mechanism to mitigate the impact of poorly generated samples. Experimental results across various datasets show that DIAGen not only enhances semantic diversity but also improves the performance of subsequent classifiers. The advantages of DIAGen over standard augmentations and the DA-Fusion baseline are particularly pronounced with out-of-distribution samples.
Read more8/28/2024