A Comparative Study on Enhancing Prediction in Social Network Advertisement through Data Augmentation
2404.13812
0
0
Abstract
In the ever-evolving landscape of social network advertising, the volume and accuracy of data play a critical role in the performance of predictive models. However, the development of robust predictive algorithms is often hampered by the limited size and potential bias present in real-world datasets. This study presents and explores a generative augmentation framework of social network advertising data. Our framework explores three generative models for data augmentation - Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Gaussian Mixture Models (GMMs) - to enrich data availability and diversity in the context of social network advertising analytics effectiveness. By performing synthetic extensions of the feature space, we find that through data augmentation, the performance of various classifiers has been quantitatively improved. Furthermore, we compare the relative performance gains brought by each data augmentation technique, providing insights for practitioners to select appropriate techniques to enhance model performance. This paper contributes to the literature by showing that synthetic data augmentation alleviates the limitations imposed by small or imbalanced datasets in the field of social network advertising. At the same time, this article also provides a comparative perspective on the practicality of different data augmentation methods, thereby guiding practitioners to choose appropriate techniques to enhance model performance.
Create account to get full access
Overview
- This paper explores techniques to improve prediction performance in social network advertising using data augmentation.
- The researchers compare the effectiveness of various data augmentation methods, including Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and Gaussian Mixture Models (GMMs).
- The goal is to enhance the predictive power of machine learning models by generating synthetic data to supplement limited real-world datasets.
Plain English Explanation
Social networks have become a powerful platform for advertising, allowing businesses to target specific audiences with personalized content. However, the success of these advertising campaigns often depends on the ability to accurately predict user engagement and behavior. Unfortunately, the data available to train predictive models can be scarce or imbalanced, limiting their performance.
The researchers in this paper explored ways to address this challenge through data augmentation - a technique that involves generating synthetic data to supplement the original dataset. By creating realistic artificial data, the models can "learn" from a larger and more diverse set of examples, potentially improving their predictive accuracy.
The paper compares three different data augmentation methods: Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and Gaussian Mixture Models (GMMs). Each of these techniques has its own strengths and weaknesses, and the researchers aimed to determine which one would work best for enhancing social network advertising predictions.
Technical Explanation
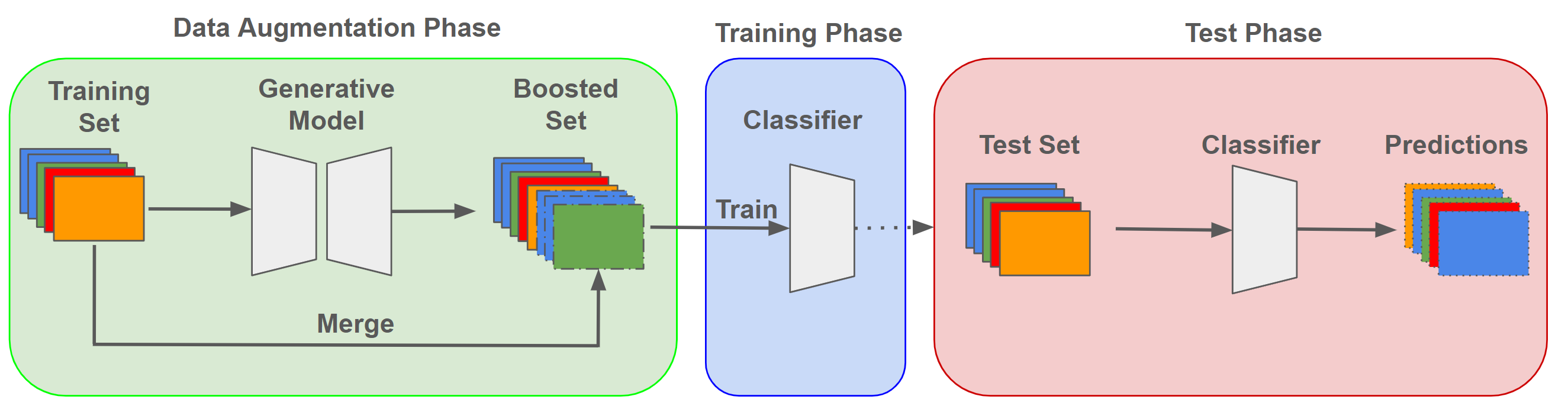
The paper begins by outlining the challenges of working with limited social network data, including issues of sparsity, class imbalance, and the need for personalized prediction models. To address these problems, the researchers evaluate three data augmentation approaches:
-
Variational Autoencoders (VAEs): VAEs are a type of generative model that can learn the underlying distribution of the input data and generate new, synthetic samples. The researchers trained VAE models on the social network data and used the generated samples to augment the original dataset.
-
Generative Adversarial Networks (GANs): GANs pit two neural networks against each other - a generator that creates synthetic data and a discriminator that tries to distinguish real from fake data. The researchers implemented a GAN-based data augmentation approach and compared its performance to the VAE method.
-
Gaussian Mixture Models (GMMs): GMMs are a statistical technique that models the data as a mixture of Gaussian distributions. The researchers used GMMs to generate synthetic samples and evaluated their impact on predictive performance.
The researchers conducted experiments on real-world social network datasets, comparing the performance of machine learning models trained on the original data versus the augmented datasets generated by the VAE, GAN, and GMM approaches. They evaluated metrics such as accuracy, F1-score, and area under the receiver operating characteristic (ROC) curve to assess the effectiveness of each data augmentation method.
Critical Analysis
The paper provides a comprehensive comparison of several data augmentation techniques and their impact on social network advertising prediction models. However, the researchers acknowledge some limitations of their work:
-
Dataset Specificity: The experiments were conducted on a limited number of social network datasets, and the results may not generalize to other domains or datasets with different characteristics.
-
Hyperparameter Tuning: The performance of the data augmentation methods could be sensitive to the choice of hyperparameters, and the researchers may not have explored the entire parameter space.
-
Computational Complexity: Implementing and training the VAE, GAN, and GMM models can be computationally expensive, which may limit their practical applicability in real-world scenarios.
Additionally, the paper does not address potential issues related to the quality and realism of the synthetic data generated by the different augmentation methods. It would be valuable to further investigate the characteristics of the generated samples and their impact on the predictive models.
Conclusion
This paper presents a comparative study on the use of data augmentation techniques to enhance the performance of social network advertising prediction models. The researchers explored three different approaches - VAEs, GANs, and GMMs - and found that each method has its own strengths and weaknesses in terms of improving predictive accuracy.
The results of this study suggest that data augmentation can be a valuable tool for addressing the challenges of working with limited social network data. By generating synthetic samples to supplement the original dataset, machine learning models can potentially learn more robust and generalized patterns, leading to better predictions of user engagement and behavior.
While the paper provides a solid foundation for further research in this area, additional work is needed to address the limitations and explore the practical implications of these data augmentation techniques in real-world social network advertising scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
A Unified Framework for Generative Data Augmentation: A Comprehensive Survey
Yunhao Chen, Zihui Yan, Yunjie Zhu
0
0
Generative data augmentation (GDA) has emerged as a promising technique to alleviate data scarcity in machine learning applications. This thesis presents a comprehensive survey and unified framework of the GDA landscape. We first provide an overview of GDA, discussing its motivation, taxonomy, and key distinctions from synthetic data generation. We then systematically analyze the critical aspects of GDA - selection of generative models, techniques to utilize them, data selection methodologies, validation approaches, and diverse applications. Our proposed unified framework categorizes the extensive GDA literature, revealing gaps such as the lack of universal benchmarks. The thesis summarises promising research directions, including , effective data selection, theoretical development for large-scale models' application in GDA and establishing a benchmark for GDA. By laying a structured foundation, this thesis aims to nurture more cohesive development and accelerate progress in the vital arena of generative data augmentation.
4/23/2024

Boosting Model Resilience via Implicit Adversarial Data Augmentation
Xiaoling Zhou, Wei Ye, Zhemg Lee, Rui Xie, Shikun Zhang
0
0
Data augmentation plays a pivotal role in enhancing and diversifying training data. Nonetheless, consistently improving model performance in varied learning scenarios, especially those with inherent data biases, remains challenging. To address this, we propose to augment the deep features of samples by incorporating their adversarial and anti-adversarial perturbation distributions, enabling adaptive adjustment in the learning difficulty tailored to each sample's specific characteristics. We then theoretically reveal that our augmentation process approximates the optimization of a surrogate loss function as the number of augmented copies increases indefinitely. This insight leads us to develop a meta-learning-based framework for optimizing classifiers with this novel loss, introducing the effects of augmentation while bypassing the explicit augmentation process. We conduct extensive experiments across four common biased learning scenarios: long-tail learning, generalized long-tail learning, noisy label learning, and subpopulation shift learning. The empirical results demonstrate that our method consistently achieves state-of-the-art performance, highlighting its broad adaptability.
6/4/2024

A Comprehensive Survey on Data Augmentation
Zaitian Wang, Pengfei Wang, Kunpeng Liu, Pengyang Wang, Yanjie Fu, Chang-Tien Lu, Charu C. Aggarwal, Jian Pei, Yuanchun Zhou
0
0
Data augmentation is a series of techniques that generate high-quality artificial data by manipulating existing data samples. By leveraging data augmentation techniques, AI models can achieve significantly improved applicability in tasks involving scarce or imbalanced datasets, thereby substantially enhancing AI models' generalization capabilities. Existing literature surveys only focus on a certain type of specific modality data, and categorize these methods from modality-specific and operation-centric perspectives, which lacks a consistent summary of data augmentation methods across multiple modalities and limits the comprehension of how existing data samples serve the data augmentation process. To bridge this gap, we propose a more enlightening taxonomy that encompasses data augmentation techniques for different common data modalities. Specifically, from a data-centric perspective, this survey proposes a modality-independent taxonomy by investigating how to take advantage of the intrinsic relationship between data samples, including single-wise, pair-wise, and population-wise sample data augmentation methods. Additionally, we categorize data augmentation methods across five data modalities through a unified inductive approach.
5/20/2024

Expansive Synthesis: Generating Large-Scale Datasets from Minimal Samples
Vahid Jebraeeli, Bo Jiang, Hamid Krim, Derya Cansever
0
0
The challenge of limited availability of data for training in machine learning arises in many applications and the impact on performance and generalization is serious. Traditional data augmentation methods aim to enhance training with a moderately sufficient data set. Generative models like Generative Adversarial Networks (GANs) often face problematic convergence when generating significant and diverse data samples. Diffusion models, though effective, still struggle with high computational cost and long training times. This paper introduces an innovative Expansive Synthesis model that generates large-scale, high-fidelity datasets from minimal samples. The proposed approach exploits expander graph mappings and feature interpolation to synthesize expanded datasets while preserving the intrinsic data distribution and feature structural relationships. The rationale of the model is rooted in the non-linear property of neural networks' latent space and in its capture by a Koopman operator to yield a linear space of features to facilitate the construction of larger and enriched consistent datasets starting with a much smaller dataset. This process is optimized by an autoencoder architecture enhanced with self-attention layers and further refined for distributional consistency by optimal transport. We validate our Expansive Synthesis by training classifiers on the generated datasets and comparing their performance to classifiers trained on larger, original datasets. Experimental results demonstrate that classifiers trained on synthesized data achieve performance metrics on par with those trained on full-scale datasets, showcasing the model's potential to effectively augment training data. This work represents a significant advancement in data generation, offering a robust solution to data scarcity and paving the way for enhanced data availability in machine learning applications.
6/26/2024