Data Augmentation Techniques for Process Extraction from Scientific Publications
2405.14594
0
0
📊
Abstract
We present data augmentation techniques for process extraction tasks in scientific publications. We cast the process extraction task as a sequence labeling task where we identify all the entities in a sentence and label them according to their process-specific roles. The proposed method attempts to create meaningful augmented sentences by utilizing (1) process-specific information from the original sentence, (2) role label similarity, and (3) sentence similarity. We demonstrate that the proposed methods substantially improve the performance of the process extraction model trained on chemistry domain datasets, up to 12.3 points improvement in performance accuracy (F-score). The proposed methods could potentially reduce overfitting as well, especially when training on small datasets or in a low-resource setting such as in chemistry and other scientific domains.
Create account to get full access
Overview
- The paper presents data augmentation techniques for improving process extraction tasks in scientific publications.
- The process extraction task is framed as a sequence labeling problem, where entities in a sentence are identified and labeled based on their process-specific roles.
- The proposed methods aim to create meaningful augmented sentences by leveraging process-specific information, role label similarity, and sentence similarity.
- The techniques are evaluated on chemistry domain datasets and demonstrate significant performance improvements, up to 12.3 points in F-score.
- The methods could potentially reduce overfitting, especially when training on small datasets or in low-resource settings, such as in chemistry and other scientific domains.
Plain English Explanation
The paper focuses on improving a specific task in natural language processing called "process extraction." This task involves identifying and categorizing all the different steps or actions described in a scientific publication, such as a chemistry paper. The researchers developed new techniques to generate additional training data, a process called "data augmentation," to help a machine learning model learn this task more effectively.
The key idea is to take the original sentences from the scientific papers and make small, meaningful changes to create new, synthetic sentences that still represent the same underlying processes. This is done by leveraging information about the specific roles of words in the process (e.g., the "reagent" or the "product"), as well as considering how similar the new sentences are to the original ones.
The researchers tested these data augmentation methods on chemistry datasets and found that they could significantly improve the performance of the process extraction model, increasing the accuracy by up to 12.3%. This is especially important when working with smaller datasets or in fields where data is scarce, as the augmentation techniques can help the model generalize better and avoid overfitting to the limited training data.
Technical Explanation
The paper frames the process extraction task as a sequence labeling problem, where the goal is to identify all the relevant entities in a sentence (e.g., reagents, products, conditions) and label them according to their specific process-related roles. To improve the performance of this task, the researchers developed several data augmentation techniques:
-
Process-specific information augmentation: This method generates new sentences by replacing words or phrases in the original sentence with semantically similar alternatives that maintain the underlying process information.
-
Role label similarity augmentation: Here, the researchers swap entities with others that have similar process-specific roles, preserving the overall structure of the sentence.
-
Sentence similarity augmentation: This approach creates new sentences by paraphrasing the original, using techniques like word substitution and reordering to generate similar sentences that convey the same process-related information.
The researchers evaluated these augmentation methods on chemistry domain datasets and found that they could significantly improve the performance of the process extraction model, with gains of up to 12.3 percentage points in F-score. They also suggest that these techniques could help reduce overfitting, especially when working with small datasets or in low-resource settings, such as in chemistry and other scientific fields.
Critical Analysis
The paper presents a thorough and well-designed study, with a clear focus on addressing the challenge of process extraction in scientific publications. The proposed data augmentation techniques seem well-grounded in linguistic principles and are thoughtfully designed to preserve the underlying process-related information.
One potential limitation of the study is the specific focus on the chemistry domain. While the researchers demonstrate the effectiveness of their methods on chemistry datasets, it would be valuable to see how the techniques perform on other scientific domains, such as biology or physics, to assess their broader applicability.
Additionally, the paper does not provide a comprehensive survey of data augmentation techniques in natural language processing. It would be interesting to see how the proposed methods compare to other augmentation strategies, such as those based on text clustering or reinforcement learning.
Overall, the paper makes a valuable contribution to the field of process extraction and demonstrates the potential of data augmentation techniques to improve performance, especially in low-resource settings. Further research on the generalizability of the methods and comparisons to other augmentation approaches would be welcome.
Conclusion
This paper presents novel data augmentation techniques for improving process extraction tasks in scientific publications, with a focus on the chemistry domain. The proposed methods leverage process-specific information, role label similarity, and sentence similarity to generate meaningful augmented sentences that can significantly boost the performance of process extraction models.
The key contribution of this work is the demonstration that carefully crafted data augmentation strategies can lead to substantial gains in model accuracy, up to 12.3 percentage points in F-score. This is particularly important in scientific domains where data is often scarce, as the augmentation techniques can help mitigate overfitting and improve the model's ability to generalize.
The findings of this paper have broader implications for natural language processing tasks that involve extracting structured information from complex, domain-specific texts. The insights and techniques presented here could potentially be adapted to other scientific fields or even extended to more general language understanding problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Leveraging Data Augmentation for Process Information Extraction
Julian Neuberger, Leonie Doll, Benedict Engelmann, Lars Ackermann, Stefan Jablonski
0
0
Business Process Modeling projects often require formal process models as a central component. High costs associated with the creation of such formal process models motivated many different fields of research aimed at automated generation of process models from readily available data. These include process mining on event logs, and generating business process models from natural language texts. Research in the latter field is regularly faced with the problem of limited data availability, hindering both evaluation and development of new techniques, especially learning-based ones. To overcome this data scarcity issue, in this paper we investigate the application of data augmentation for natural language text data. Data augmentation methods are well established in machine learning for creating new, synthetic data without human assistance. We find that many of these methods are applicable to the task of business process information extraction, improving the accuracy of extraction. Our study shows, that data augmentation is an important component in enabling machine learning methods for the task of business process model generation from natural language text, where currently mostly rule-based systems are still state of the art. Simple data augmentation techniques improved the $F_1$ score of mention extraction by 2.9 percentage points, and the $F_1$ of relation extraction by $4.5$. To better understand how data augmentation alters human annotated texts, we analyze the resulting text, visualizing and discussing the properties of augmented textual data. We make all code and experiments results publicly available.
4/12/2024
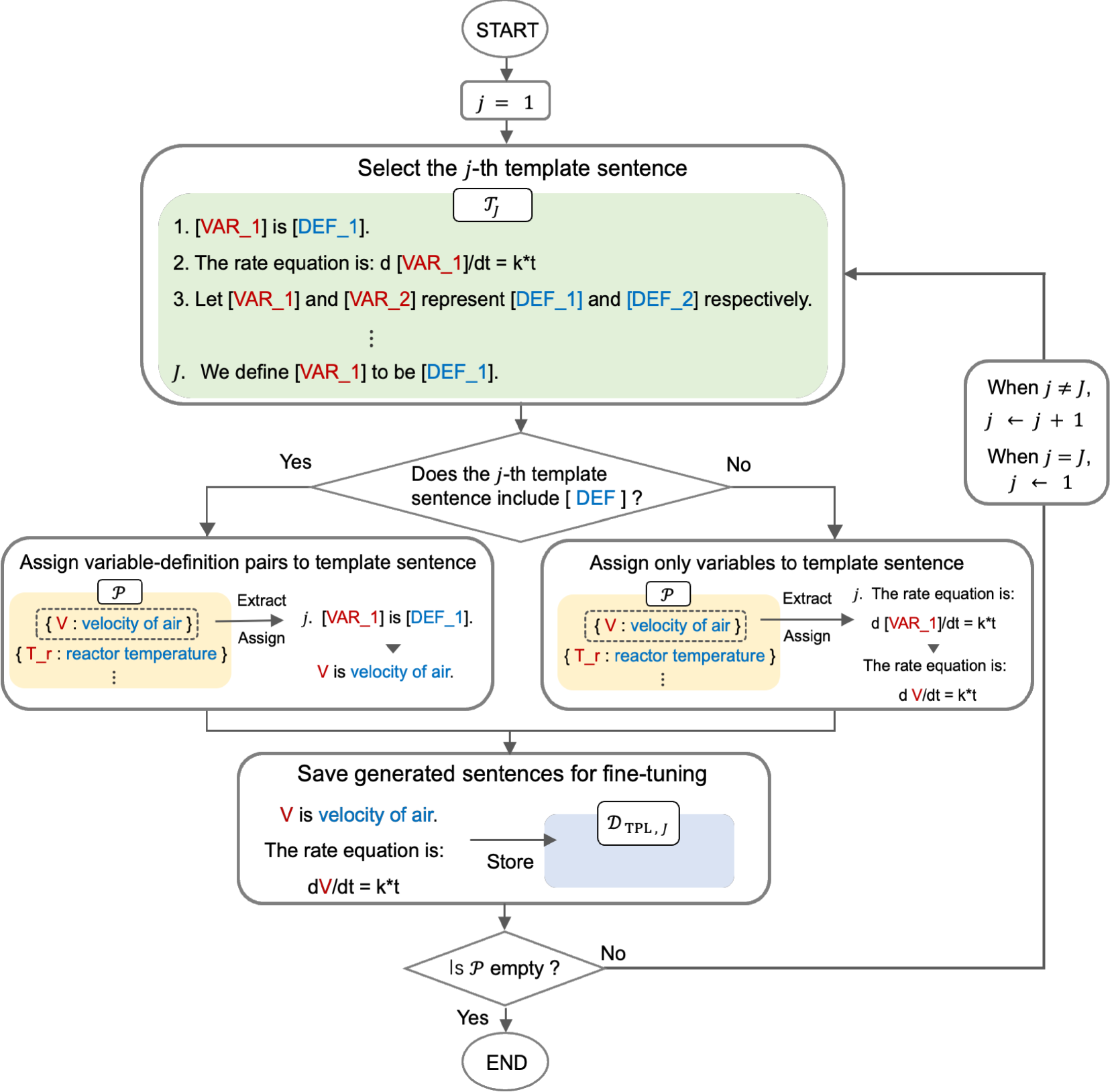
Data Augmentation Method Utilizing Template Sentences for Variable Definition Extraction
Kotaro Nagayama, Shota Kato, Manabu Kano
0
0
The extraction of variable definitions from scientific and technical papers is essential for understanding these documents. However, the characteristics of variable definitions, such as the length and the words that make up the definition, differ among fields, which leads to differences in the performance of existing extraction methods across fields. Although preparing training data specific to each field can improve the performance of the methods, it is costly to create high-quality training data. To address this challenge, this study proposes a new method that generates new definition sentences from template sentences and variable-definition pairs in the training data. The proposed method has been tested on papers about chemical processes, and the results show that the model trained with the definition sentences generated by the proposed method achieved a higher accuracy of 89.6%, surpassing existing models.
5/27/2024
⛏️
Targeted Augmentation for Low-Resource Event Extraction
Sijia Wang, Lifu Huang
0
0
Addressing the challenge of low-resource information extraction remains an ongoing issue due to the inherent information scarcity within limited training examples. Existing data augmentation methods, considered potential solutions, struggle to strike a balance between weak augmentation (e.g., synonym augmentation) and drastic augmentation (e.g., conditional generation without proper guidance). This paper introduces a novel paradigm that employs targeted augmentation and back validation to produce augmented examples with enhanced diversity, polarity, accuracy, and coherence. Extensive experimental results demonstrate the effectiveness of the proposed paradigm. Furthermore, identified limitations are discussed, shedding light on areas for future improvement.
5/15/2024

Text clustering applied to data augmentation in legal contexts
Lucas Jos'e Gonc{c}alves Freitas, Tha'is Rodrigues, Guilherme Rodrigues, Pamella Edokawa, Ariane Farias
0
0
Data analysis and machine learning are of preeminent importance in the legal domain, especially in tasks like clustering and text classification. In this study, we harnessed the power of natural language processing tools to enhance datasets meticulously curated by experts. This process significantly improved the classification workflow for legal texts using machine learning techniques. We considered the Sustainable Development Goals (SDGs) data from the United Nations 2030 Agenda as a practical case study. Data augmentation clustering-based strategy led to remarkable enhancements in the accuracy and sensitivity metrics of classification models. For certain SDGs within the 2030 Agenda, we observed performance gains of over 15%. In some cases, the example base expanded by a noteworthy factor of 5. When dealing with unclassified legal texts, data augmentation strategies centered around clustering prove to be highly effective. They provide a valuable means to expand the existing knowledge base without the need for labor-intensive manual classification efforts.
4/16/2024