Text clustering applied to data augmentation in legal contexts
2404.08683
0
0

Abstract
Data analysis and machine learning are of preeminent importance in the legal domain, especially in tasks like clustering and text classification. In this study, we harnessed the power of natural language processing tools to enhance datasets meticulously curated by experts. This process significantly improved the classification workflow for legal texts using machine learning techniques. We considered the Sustainable Development Goals (SDGs) data from the United Nations 2030 Agenda as a practical case study. Data augmentation clustering-based strategy led to remarkable enhancements in the accuracy and sensitivity metrics of classification models. For certain SDGs within the 2030 Agenda, we observed performance gains of over 15%. In some cases, the example base expanded by a noteworthy factor of 5. When dealing with unclassified legal texts, data augmentation strategies centered around clustering prove to be highly effective. They provide a valuable means to expand the existing knowledge base without the need for labor-intensive manual classification efforts.
Create account to get full access
Overview
- This paper explores the use of text clustering techniques for data augmentation in legal contexts.
- The researchers investigate how clustering can generate synthetic data to improve the performance of natural language processing models on legal tasks.
- The study is motivated by the UN's 2030 Agenda for Sustainable Development, which highlights the need for more accessible and inclusive legal systems.
Plain English Explanation
The researchers in this paper looked at a way to help improve AI systems that work with legal documents and texts. They used a technique called text clustering to group similar legal documents together. Then, they used this to generate new, synthetic legal documents that could be used to train the AI models and make them better at understanding and processing legal information.
The motivation for this work comes from the UN 2030 Agenda for Sustainable Development, which calls for making legal systems more accessible and inclusive for everyone. By improving the AI models used in legal contexts, the researchers hope to contribute to this goal and make legal information and services more widely available.
Technical Explanation
The paper begins by providing background on the challenges of working with legal data, including the diversity of legal terminology, the complexity of legal reasoning, and the limited availability of annotated datasets. The researchers then describe their approach of using text clustering to group similar legal documents together.
The key steps of their method are:
- Preprocessing: Cleaning and tokenizing the legal documents.
- Embedding: Representing the documents as numerical vectors using a language model like BERT.
- Clustering: Grouping the document vectors into clusters using k-means clustering.
- Augmentation: Generating new, synthetic legal documents by sampling from the clusters.
The researchers evaluate their approach on a legal text classification task, comparing models trained on the original dataset to those trained on the augmented dataset. Their results show that the augmented dataset leads to significant improvements in the model's performance, indicating the potential of this text clustering-based data augmentation technique for legal AI applications.
Critical Analysis
The paper provides a well-designed and thorough exploration of using text clustering for data augmentation in legal contexts. The researchers acknowledge several limitations, such as the potential for the synthetic documents to diverge from the true distribution of legal texts, and the need for further research to optimize the clustering and document generation process.
One area that could be further investigated is the degree to which the generated documents capture the nuanced reasoning and logical structures that are crucial in legal decision-making. While the performance improvements on the text classification task are promising, the ability of the augmented data to support more complex legal reasoning tasks remains an open question.
Additionally, the paper does not discuss potential ethical considerations around the use of synthetic legal data, such as concerns about fairness, transparency, or the risk of perpetuating biases. As this technology matures, it will be important for researchers to carefully consider these issues and develop guidelines for the responsible use of data augmentation in legal AI systems.
Conclusion
Overall, this paper presents a novel and promising approach to using text clustering for data augmentation in legal contexts. By generating synthetic legal documents, the researchers have demonstrated the potential to improve the performance of natural language processing models on a range of legal tasks, which could ultimately contribute to more accessible and inclusive legal systems as envisioned by the UN 2030 Agenda. As the research in this area continues to evolve, it will be important to carefully consider the ethical implications and ensure that the technology is developed and deployed in a responsible manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Leveraging Data Augmentation for Process Information Extraction
Julian Neuberger, Leonie Doll, Benedict Engelmann, Lars Ackermann, Stefan Jablonski
0
0
Business Process Modeling projects often require formal process models as a central component. High costs associated with the creation of such formal process models motivated many different fields of research aimed at automated generation of process models from readily available data. These include process mining on event logs, and generating business process models from natural language texts. Research in the latter field is regularly faced with the problem of limited data availability, hindering both evaluation and development of new techniques, especially learning-based ones. To overcome this data scarcity issue, in this paper we investigate the application of data augmentation for natural language text data. Data augmentation methods are well established in machine learning for creating new, synthetic data without human assistance. We find that many of these methods are applicable to the task of business process information extraction, improving the accuracy of extraction. Our study shows, that data augmentation is an important component in enabling machine learning methods for the task of business process model generation from natural language text, where currently mostly rule-based systems are still state of the art. Simple data augmentation techniques improved the $F_1$ score of mention extraction by 2.9 percentage points, and the $F_1$ of relation extraction by $4.5$. To better understand how data augmentation alters human annotated texts, we analyze the resulting text, visualizing and discussing the properties of augmented textual data. We make all code and experiments results publicly available.
4/12/2024
Empowering Large Language Models for Textual Data Augmentation
Yichuan Li, Kaize Ding, Jianling Wang, Kyumin Lee
0
0
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
4/30/2024
📊
Data Augmentation Techniques for Process Extraction from Scientific Publications
Yuni Susanti
0
0
We present data augmentation techniques for process extraction tasks in scientific publications. We cast the process extraction task as a sequence labeling task where we identify all the entities in a sentence and label them according to their process-specific roles. The proposed method attempts to create meaningful augmented sentences by utilizing (1) process-specific information from the original sentence, (2) role label similarity, and (3) sentence similarity. We demonstrate that the proposed methods substantially improve the performance of the process extraction model trained on chemistry domain datasets, up to 12.3 points improvement in performance accuracy (F-score). The proposed methods could potentially reduce overfitting as well, especially when training on small datasets or in a low-resource setting such as in chemistry and other scientific domains.
5/24/2024
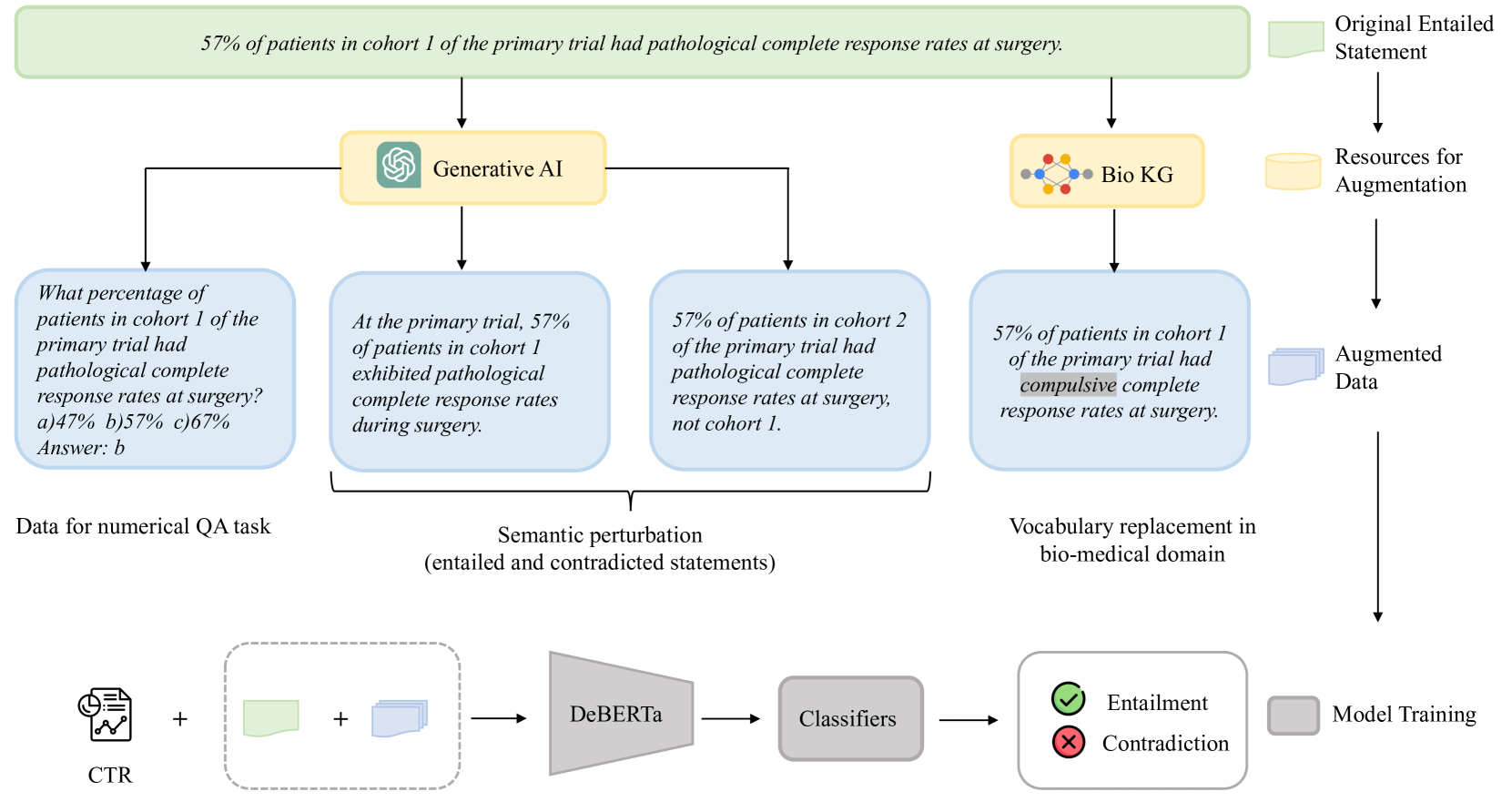
DKE-Research at SemEval-2024 Task 2: Incorporating Data Augmentation with Generative Models and Biomedical Knowledge to Enhance Inference Robustness
Yuqi Wang, Zeqiang Wang, Wei Wang, Qi Chen, Kaizhu Huang, Anh Nguyen, Suparna De
0
0
Safe and reliable natural language inference is critical for extracting insights from clinical trial reports but poses challenges due to biases in large pre-trained language models. This paper presents a novel data augmentation technique to improve model robustness for biomedical natural language inference in clinical trials. By generating synthetic examples through semantic perturbations and domain-specific vocabulary replacement and adding a new task for numerical and quantitative reasoning, we introduce greater diversity and reduce shortcut learning. Our approach, combined with multi-task learning and the DeBERTa architecture, achieved significant performance gains on the NLI4CT 2024 benchmark compared to the original language models. Ablation studies validate the contribution of each augmentation method in improving robustness. Our best-performing model ranked 12th in terms of faithfulness and 8th in terms of consistency, respectively, out of the 32 participants.
4/16/2024