Data Caching for Enterprise-Grade Petabyte-Scale OLAP

0
Sign in to get full access
Overview
• This paper presents a data caching system designed for enterprise-level online analytical processing (OLAP) workloads that can handle petabyte-scale data. • The system aims to provide low-latency access to large datasets by leveraging a novel caching approach and efficient data structures. • Key innovations include a disaggregated caching architecture, support for multidimensional range queries, and techniques for managing the cache lifecycle.
Plain English Explanation
Businesses today often need to analyze huge amounts of data, sometimes reaching the petabyte scale (millions of gigabytes). This data is used for various analytical tasks, such as understanding customer behavior or optimizing operations. However, accessing and analyzing data of this magnitude can be very slow, which limits its usefulness.
The researchers in this paper have developed a new caching system to help speed up these big data analytics workloads. Caching involves storing frequently accessed data in a high-speed memory area, so it can be retrieved quickly without having to read it from the slower main storage.
Their system has a few key advantages:
-
Disaggregated Architecture: The caching components are separate from the main data storage, allowing the caching to be scaled independently as needed.
-
Multidimensional Queries: The cache can efficiently handle complex analytical queries that involve searching across multiple data dimensions (e.g., customer, product, time).
-
Intelligent Cache Management: The system dynamically manages the cache contents to ensure the most important data is kept in fast memory.
By addressing the challenges of scale, query complexity, and cache optimization, this new caching approach can significantly improve the performance of big data analytics systems used in large enterprises. This can lead to faster business insights and better decision-making.
Technical Explanation
The researchers' data caching system is designed to support petabyte-scale OLAP workloads by leveraging a disaggregated architecture and efficient data structures.
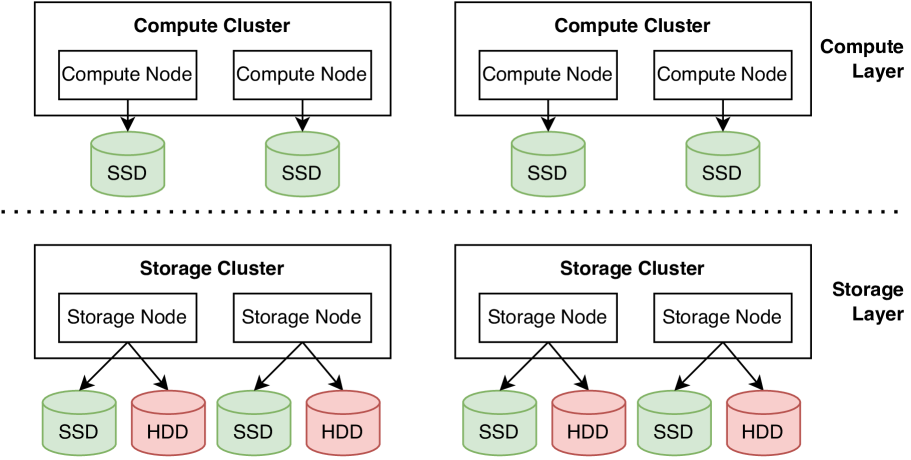
The core innovation is a disaggregated caching approach, where the caching components are separate from the main data storage. This allows the caching layer to be scaled independently to meet the demands of large datasets and complex analytical queries. The cache stores data in a multidimensional index structure that supports efficient range queries across multiple attributes.
To manage the cache lifecycle, the system employs several techniques:
- Predictive Caching: The cache proactively loads data that is likely to be accessed in the future based on access patterns.
- Adaptive Eviction: An intelligent eviction policy determines which data to remove from the cache when space is needed, prioritizing the least valuable data.
- Tiered Storage: The cache uses a hierarchy of storage tiers with different performance and capacity characteristics to optimize cost and efficiency.
The authors evaluate their system's performance using large-scale OLAP benchmarks and show significant improvements in query latency and throughput compared to traditional caching approaches. Key benefits include the ability to handle complex multidimensional queries and the efficient management of the cache contents.
Critical Analysis
The research presented in this paper addresses an important challenge in enterprise-scale data analytics - providing fast, efficient access to massive datasets. The authors' disaggregated caching approach and supporting techniques appear well-designed to tackle the complexities of petabyte-scale OLAP workloads.
One potential limitation is the reliance on specific hardware or infrastructure configurations, which could limit the system's broader applicability. The authors mention the use of a tiered storage hierarchy, but do not provide extensive details on the hardware requirements or costs involved.
Additionally, while the paper demonstrates strong performance improvements, it would be valuable to understand the system's behavior under more diverse workloads and access patterns. Further research could explore the cache's resilience to changes in data distribution, query complexity, and other operational factors.
Nonetheless, this work represents an important advance in data caching for large-scale analytics. The disaggregated architecture and support for multidimensional queries are particularly noteworthy contributions that could significantly benefit enterprises struggling with the challenges of big data analytics.
Conclusion
This paper presents a novel data caching system designed to address the performance challenges of enterprise-grade, petabyte-scale OLAP workloads. By leveraging a disaggregated caching architecture, efficient data structures, and intelligent cache management techniques, the system can deliver low-latency access to massive datasets and support complex analytical queries.
The key innovations - including the disaggregated design, multidimensional indexing, and adaptive caching policies - demonstrate a thoughtful approach to optimizing data access and cache utilization for big data analytics. While some implementation details and limitations warrant further exploration, this research represents an important step forward in enabling faster, more effective data-driven decision-making at scale.
As enterprises continue to grapple with the growth of big data, solutions like the one described in this paper will become increasingly crucial for unlocking the full potential of their data assets. By bridging the gap between data volume and analytical performance, this caching system can empower organizations to extract deeper insights and make more informed strategic decisions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data Caching for Enterprise-Grade Petabyte-Scale OLAP
Chunxu Tang (James), Bin Fan (James), Jing Zhao (James), Chen Liang (James), Yi Wang (James), Beinan Wang (James), Ziyue Qiu (James), Lu Qiu (James), Bowen Ding (James), Shouzhuo Sun (James), Saiguang Che (James), Jiaming Mai (James), Shouwei Chen (James), Yu Zhu (James), Jianjian Xie (James), Yutian (James), Sun, Yao Li, Yangjun Zhang, Ke Wang, Mingmin Chen
With the exponential growth of data and evolving use cases, petabyte-scale OLAP data platforms are increasingly adopting a model that decouples compute from storage. This shift, evident in organizations like Uber and Meta, introduces operational challenges including massive, read-heavy I/O traffic with potential throttling, as well as skewed and fragmented data access patterns. Addressing these challenges, this paper introduces the Alluxio local (edge) cache, a highly effective architectural optimization tailored for such environments. This embeddable cache, optimized for petabyte-scale data analytics, leverages local SSD resources to alleviate network I/O and API call pressures, significantly improving data transfer efficiency. Integrated with OLAP systems like Presto and storage services like HDFS, the Alluxio local cache has demonstrated its effectiveness in handling large-scale, enterprise-grade workloads over three years of deployment at Uber and Meta. We share insights and operational experiences in implementing these optimizations, providing valuable perspectives on managing modern, massive-scale OLAP workloads.
Read more6/11/2024
📊
0
LLM-dCache: Improving Tool-Augmented LLMs with GPT-Driven Localized Data Caching
Simranjit Singh, Michael Fore, Andreas Karatzas, Chaehong Lee, Yanan Jian, Longfei Shangguan, Fuxun Yu, Iraklis Anagnostopoulos, Dimitrios Stamoulis
As Large Language Models (LLMs) broaden their capabilities to manage thousands of API calls, they are confronted with complex data operations across vast datasets with significant overhead to the underlying system. In this work, we introduce LLM-dCache to optimize data accesses by treating cache operations as callable API functions exposed to the tool-augmented agent. We grant LLMs the autonomy to manage cache decisions via prompting, seamlessly integrating with existing function-calling mechanisms. Tested on an industry-scale massively parallel platform that spans hundreds of GPT endpoints and terabytes of imagery, our method improves Copilot times by an average of 1.24x across various LLMs and prompting techniques.
Read more9/24/2024
🚀
0
DDS: DPU-optimized Disaggregated Storage
Qizhen Zhang, Philip Bernstein, Badrish Chandramouli, Jiasheng Hu, Yiming Zheng
This extended report presents DDS, a novel disaggregated storage architecture enabled by emerging networking hardware, namely DPUs (Data Processing Units). DPUs can optimize the latency and CPU consumption of disaggregated storage servers. However, utilizing DPUs for DBMSs requires careful design of the network and storage paths and the interface exposed to the DBMS. To fully benefit from DPUs, DDS heavily uses DMA, zero-copy, and userspace I/O to minimize overhead when improving throughput. It also introduces an offload engine that eliminates host CPUs by executing client requests directly on the DPU. Adopting DDS' API requires minimal DBMS modification. Our experimental study and production system integration show promising results -- DDS achieves higher disaggregated storage throughput with an order of magnitude lower latency, and saves up to tens of CPU cores per storage server.
Read more8/29/2024
🏷️
0
DEX: Scalable Range Indexing on Disaggregated Memory [Extended Version]
Baotong Lu, Kaisong Huang, Chieh-Jan Mike Liang, Tianzheng Wang, Eric Lo
Memory disaggregation can potentially allow memory-optimized range indexes such as B+-trees to scale beyond one machine while attaining high hardware utilization and low cost. Designing scalable indexes on disaggregated memory, however, is challenging due to rudimentary caching, unprincipled offloading and excessive inconsistency among servers. This paper proposes DEX, a new scalable B+-tree for memory disaggregation. DEX includes a set of techniques to reduce remote accesses, including logical partitioning, lightweight caching and cost-aware offloading. Our evaluation shows that DEX can outperform the state-of-the-art by 1.7--56.3X, and the advantage remains under various setups, such as cache size and skewness.
Read more5/24/2024