LLM-dCache: Improving Tool-Augmented LLMs with GPT-Driven Localized Data Caching

0
📊
Sign in to get full access
Overview
- Introduces a novel technique called LLM-dCache to improve the performance of tool-augmented large language models (LLMs)
- Leverages GPT-driven localized data caching to enhance the efficiency of LLM-based systems
- Aims to address challenges in managing and accessing large knowledge bases that LLMs rely on
Plain English Explanation
LLM-dCache is a new approach to make large language models (LLMs) more efficient when used in combination with external tools or knowledge sources. LLMs are powerful AI systems that can understand and generate human-like text, but they often need to access large amounts of data to provide accurate and relevant responses.
The paper introduces LLM-dCache, which uses a technique called "GPT-driven localized data caching" to address this challenge. The key idea is to create a cache of relevant information that the LLM can quickly access, instead of having to search through the entire knowledge base every time. This cache is "localized" because it is tailored to the specific context and task at hand, and it is "GPT-driven" because the LLM itself is used to identify the most relevant information to include in the cache.
By using this LLM-dCache approach, the researchers aim to improve the overall performance and efficiency of tool-augmented LLM systems, making them more practical and user-friendly for a wide range of applications. This could have implications for enhancing general agent capabilities with low-parameter LLMs or enabling more efficient and interactive data exploration with large language models.
Technical Explanation
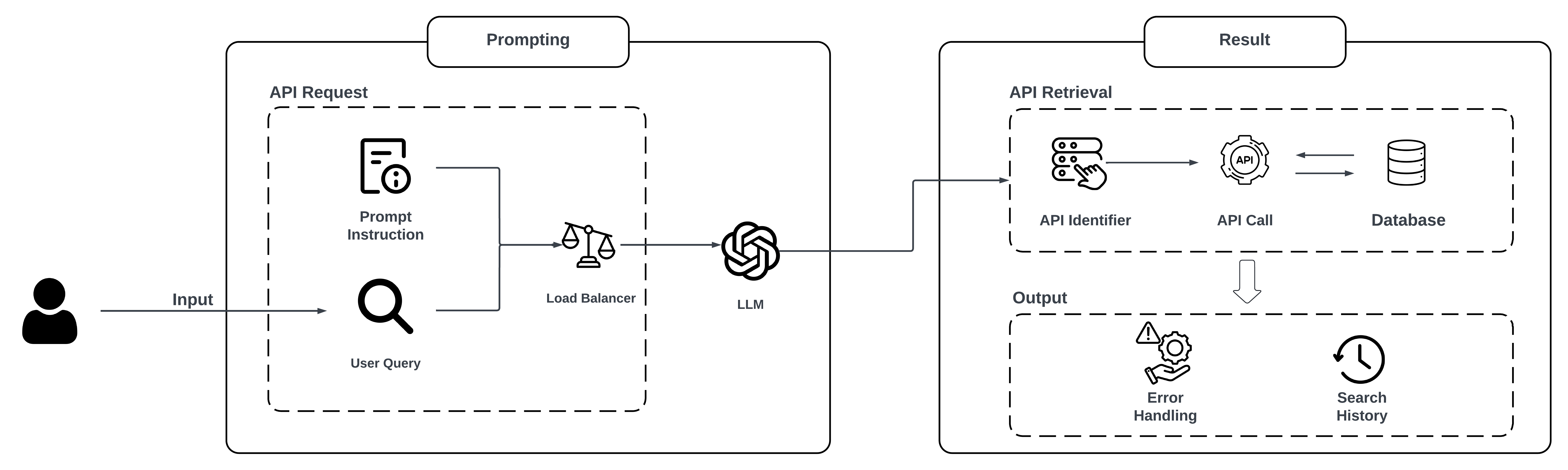
The paper proposes a novel technique called LLM-dCache, which leverages GPT-driven localized data caching to improve the performance of tool-augmented large language models (LLMs). The key idea is to create a cache of relevant information that the LLM can quickly access, instead of having to search through the entire knowledge base every time.
The LLM-dCache system works as follows:
- Data Gathering: The system collects relevant data from various sources, such as documents, databases, or external APIs, based on the specific task or context at hand.
- Cache Initialization: The gathered data is then processed and organized into a localized cache, with the help of the LLM itself. The LLM is used to identify the most relevant information to include in the cache.
- Cache-Augmented Inference: When the LLM needs to generate a response, it first checks the localized cache for relevant information, before falling back to the full knowledge base if necessary. This can significantly improve the speed and efficiency of the LLM's inference process.
The researchers evaluate the LLM-dCache approach through a series of experiments, demonstrating its effectiveness in improving the performance of tool-augmented LLM systems. The results show that LLM-dCache can lead to significant reductions in inference time and memory usage, while maintaining the accuracy of the LLM's responses.
Critical Analysis
The LLM-dCache approach proposed in the paper addresses an important challenge in the field of tool-augmented LLMs. By leveraging localized data caching, the system can improve the efficiency and practicality of these systems, which is crucial for real-world applications.
However, the paper does not provide a detailed discussion of the potential limitations or caveats of the LLM-dCache approach. For example, it's unclear how the system would perform in scenarios where the task or context changes rapidly, or how it would handle dynamic or rapidly evolving knowledge bases. Additionally, the paper does not explore the potential trade-offs between the benefits of LLM-dCache and the computational overhead of maintaining the cache.
Further research could also investigate the generalizability of the LLM-dCache approach to different types of LLMs and tool-augmented systems. Exploring the use of LLM-dCache in the context of LLM-tool compiler-fused parallel function calling or investigating the integration of LLM-dCache with privacy-aware semantic caching techniques for LLMs could provide valuable insights into the broader applicability of this technique.
Conclusion
The LLM-dCache approach introduced in this paper represents an important step forward in improving the performance and efficiency of tool-augmented large language models. By leveraging GPT-driven localized data caching, the system can significantly reduce the time and memory required for LLM inference, while maintaining the accuracy of the model's responses.
This work has the potential to contribute to the development of more practical and user-friendly LLM-based systems, with applications in a wide range of domains, from enhancing general agent capabilities with low-parameter LLMs to enabling more efficient and interactive data exploration with large language models. Further research is needed to fully understand the limitations and broader implications of the LLM-dCache approach, but this paper represents an important step forward in the field of tool-augmented LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
LLM-dCache: Improving Tool-Augmented LLMs with GPT-Driven Localized Data Caching
Simranjit Singh, Michael Fore, Andreas Karatzas, Chaehong Lee, Yanan Jian, Longfei Shangguan, Fuxun Yu, Iraklis Anagnostopoulos, Dimitrios Stamoulis
As Large Language Models (LLMs) broaden their capabilities to manage thousands of API calls, they are confronted with complex data operations across vast datasets with significant overhead to the underlying system. In this work, we introduce LLM-dCache to optimize data accesses by treating cache operations as callable API functions exposed to the tool-augmented agent. We grant LLMs the autonomy to manage cache decisions via prompting, seamlessly integrating with existing function-calling mechanisms. Tested on an industry-scale massively parallel platform that spans hundreds of GPT endpoints and terabytes of imagery, our method improves Copilot times by an average of 1.24x across various LLMs and prompting techniques.
Read more9/24/2024
💬
0
Privacy-Aware Semantic Cache for Large Language Models
Waris Gill (Virginia Tech, USA), Mohamed Elidrisi (Cisco, USA), Pallavi Kalapatapu (Cisco, USA), Ammar Ahmed (University of Minnesota, Minneapolis, USA), Ali Anwar (University of Minnesota, Minneapolis, USA), Muhammad Ali Gulzar (Virginia Tech, USA)
Large Language Models (LLMs) like ChatGPT and Llama have revolutionized natural language processing and search engine dynamics. However, these models incur exceptionally high computational costs. For instance, GPT-3 consists of 175 billion parameters, where inference demands billions of floating-point operations. Caching is a natural solution to reduce LLM inference costs on repeated queries, which constitute about 31% of the total queries. However, existing caching methods are incapable of finding semantic similarities among LLM queries nor do they operate on contextual queries, leading to unacceptable false hit-and-miss rates. This paper introduces MeanCache, a user-centric semantic cache for LLM-based services that identifies semantically similar queries to determine cache hit or miss. Using MeanCache, the response to a user's semantically similar query can be retrieved from a local cache rather than re-querying the LLM, thus reducing costs, service provider load, and environmental impact. MeanCache leverages Federated Learning (FL) to collaboratively train a query similarity model without violating user privacy. By placing a local cache in each user's device and using FL, MeanCache reduces the latency and costs and enhances model performance, resulting in lower false hit rates. MeanCache also encodes context chains for every cached query, offering a simple yet highly effective mechanism to discern contextual query responses from standalone. Our experiments benchmarked against the state-of-the-art caching method, reveal that MeanCache attains an approximately 17% higher F-score and a 20% increase in precision during semantic cache hit-and-miss decisions while performing even better on contextual queries. It also reduces the storage requirement by 83% and accelerates semantic cache hit-and-miss decisions by 11%.
Read more7/17/2024
0
Harnessing LLMs for API Interactions: A Framework for Classification and Synthetic Data Generation
Chunliang Tao, Xiaojing Fan, Yahe Yang
As Large Language Models (LLMs) advance in natural language processing, there is growing interest in leveraging their capabilities to simplify software interactions. In this paper, we propose a novel system that integrates LLMs for both classifying natural language inputs into corresponding API calls and automating the creation of sample datasets tailored to specific API functions. By classifying natural language commands, our system allows users to invoke complex software functionalities through simple inputs, improving interaction efficiency and lowering the barrier to software utilization. Our dataset generation approach also enables the efficient and systematic evaluation of different LLMs in classifying API calls, offering a practical tool for developers or business owners to assess the suitability of LLMs for customized API management. We conduct experiments on several prominent LLMs using generated sample datasets for various API functions. The results show that GPT-4 achieves a high classification accuracy of 0.996, while LLaMA-3-8B performs much worse at 0.759. These findings highlight the potential of LLMs to transform API management and validate the effectiveness of our system in guiding model testing and selection across diverse applications.
Read more9/19/2024

0
An LLM-Tool Compiler for Fused Parallel Function Calling
Simranjit Singh, Andreas Karatzas, Michael Fore, Iraklis Anagnostopoulos, Dimitrios Stamoulis
State-of-the-art sequential reasoning in Large Language Models (LLMs) has expanded the capabilities of Copilots beyond conversational tasks to complex function calling, managing thousands of API calls. However, the tendency of compositional prompting to segment tasks into multiple steps, each requiring a round-trip to the GPT APIs, leads to increased system latency and costs. Although recent advancements in parallel function calling have improved tool execution per API call, they may necessitate more detailed in-context instructions and task breakdown at the prompt level, resulting in higher engineering and production costs. Inspired by the hardware design principles of multiply-add (MAD) operations, which fuse multiple arithmetic operations into a single task from the compiler's perspective, we propose LLM-Tool Compiler, which selectively fuses similar types of tool operations under a single function at runtime, presenting them as a unified task to the LLM. This selective fusion inherently enhances parallelization and efficiency. Benchmarked on a large-scale Copilot platform, LLM-Tool Compiler achieves up to four times more parallel calls than existing methods, reducing token costs and latency by up to 40% and 12%, respectively.
Read more5/29/2024