Data-Driven Analysis to Understand GPU Hardware Resource Usage of Optimizations

0

Sign in to get full access
Overview
- This paper presents a data-driven analysis to understand how GPU hardware resource usage is impacted by different optimization techniques.
- The researchers used a combination of machine learning and performance characterization to study the tradeoffs between various optimization objectives and hardware resource usage.
- The insights from this work can inform the design of multi-objective performance optimization metrics and guide the development of more efficient GPU-accelerated applications.
Plain English Explanation
The researchers in this paper wanted to understand how different optimization techniques affect the way a GPU (graphics processing unit) uses its internal hardware resources. GPUs are specialized chips that are really good at certain types of computations, like the ones needed for video games or machine learning. When you run a program on a GPU, it has to manage things like memory, processing power, and other resources to do its job efficiently.
The researchers used a combination of machine learning and performance testing to study this. They ran a bunch of different optimization techniques on GPU programs and measured how the GPU's hardware resources were used in each case. This allowed them to see the tradeoffs between different optimization goals, like making the program run faster or using less power.
The insights from this work can help researchers and engineers design better ways to optimize GPU-powered applications. They can create "multi-objective" optimization metrics that balance things like speed, efficiency, and resource usage. This can lead to more powerful and energy-efficient GPU-accelerated software, which is important as GPUs become more widely used in areas like [link to "preliminary-study-accelerating-simulation-optimization-gpu-implementation"](artificial intelligence) and [link to "orchestrated-co-scheduling-resource-partitioning-power-capping"](high-performance computing).
Technical Explanation
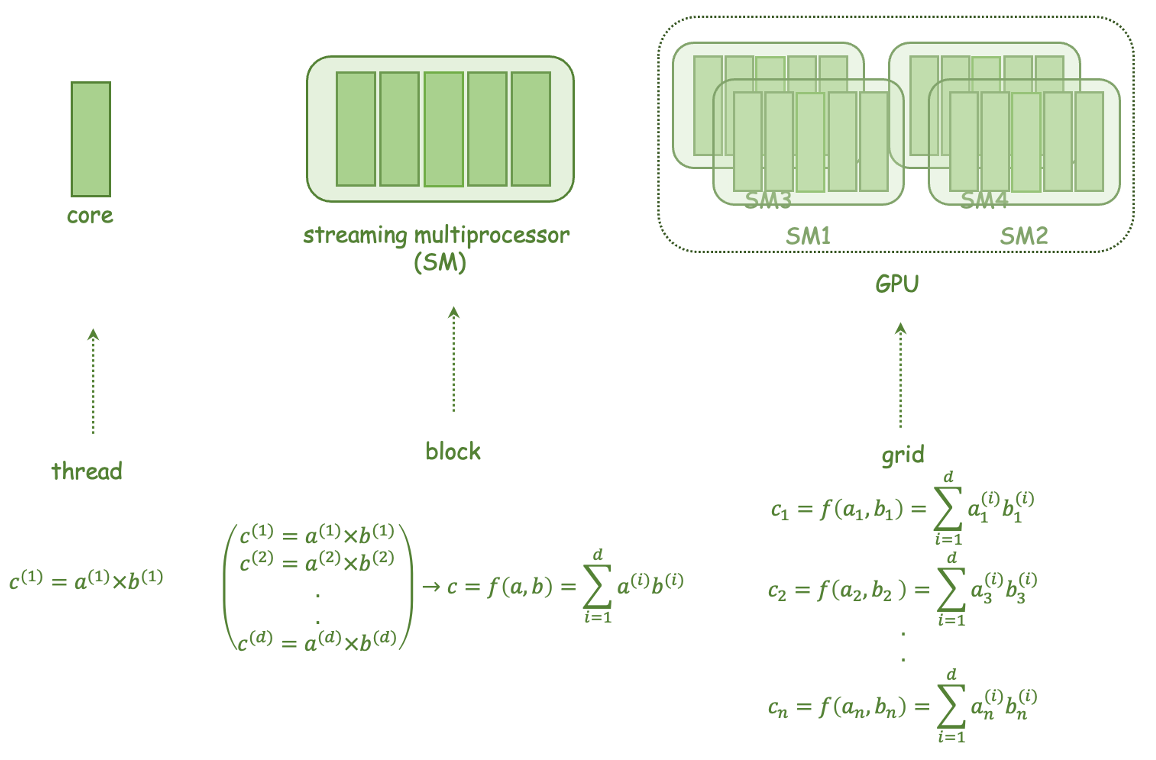
The researchers used a combination of performance characterization and machine learning techniques to study the GPU hardware resource usage of various optimization strategies. They first profiled the execution of a set of GPU kernels (the basic units of computation on a GPU) under different optimization settings, capturing detailed metrics about resource utilization, such as register file usage, shared memory usage, and occupancy.
They then used this profiling data to train machine learning models that could predict the hardware resource usage of a given optimization setting. These models allowed the researchers to explore the tradeoffs between different optimization objectives, such as minimizing runtime versus minimizing energy consumption.
The key insights from this work include:
- [link to "modeling-performance-data-collection-systems-high-energy"](Identifying the most important hardware resources) that impact performance and efficiency, and how these resources are affected by different optimizations.
- Developing a [link to "workload-aware-hardware-accelerator-mining-distributed-deep"](multi-objective performance optimization metric) that can balance multiple, potentially conflicting objectives.
- Demonstrating how machine learning can be used to [link to "optimizing-hardware-resource-partitioning-job-allocations-modern"](model the complex relationships between optimizations and hardware resource usage).
These findings can inform the design of more efficient GPU-accelerated applications and guide the development of advanced optimization techniques that consider the complex interplay between software and hardware.
Critical Analysis
The researchers provided a thorough and methodical approach to understanding GPU hardware resource usage, which is an important aspect of optimizing the performance of GPU-accelerated applications. The use of machine learning to model the relationships between optimizations and resource utilization is a particularly novel and insightful aspect of the work.
However, the paper does not address some potential limitations of the study. For example, the analysis was conducted on a single GPU architecture, and it's unclear how the findings would generalize to other GPU models or even different hardware accelerators, such as tensor processing units (TPUs). Additionally, the paper does not explore the impact of application-level characteristics, such as memory access patterns or parallelism, on hardware resource usage.
Further research could investigate how the proposed techniques and insights scale to more diverse workloads and hardware platforms. Exploring the interactions between software-level optimizations and hardware-level resource management strategies could also lead to more holistic optimization approaches.
Conclusion
This paper presents a data-driven analysis that sheds light on the complex relationship between GPU optimization techniques and hardware resource usage. The researchers leveraged machine learning to model these relationships, allowing them to develop a multi-objective performance optimization metric that can balance competing objectives, such as runtime and energy efficiency.
The insights from this work can inform the design of more efficient GPU-accelerated applications and guide the development of advanced optimization strategies that consider the intricate interplay between software and hardware. As GPUs continue to play a crucial role in [link to "aimodels.fyi/papers/arxiv/modeling-performance-data-collection-systems-high-energy"](high-performance computing) and [link to "aimodels.fyi/papers/arxiv/workload-aware-hardware-accelerator-mining-distributed-deep"](artificial intelligence), this type of research will become increasingly important for unlocking the full potential of these powerful hardware accelerators.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data-Driven Analysis to Understand GPU Hardware Resource Usage of Optimizations
Tanzima Z. Islam, Aniruddha Marathe, Holland Schutte, Mohammad Zaeed
With heterogeneous systems, the number of GPUs per chip increases to provide computational capabilities for solving science at a nanoscopic scale. However, low utilization for single GPUs defies the need to invest more money for expensive ccelerators. While related work develops optimizations for improving application performance, none studies how these optimizations impact hardware resource usage or the average GPU utilization. This paper takes a data-driven analysis approach in addressing this gap by (1) characterizing how hardware resource usage affects device utilization, execution time, or both, (2) presenting a multi-objective metric to identify important application-device interactions that can be optimized to improve device utilization and application performance jointly, (3) studying hardware resource usage behaviors of several optimizations for a benchmark application, and finally (4) identifying optimization opportunities for several scientific proxy applications based on their hardware resource usage behaviors. Furthermore, we demonstrate the applicability of our methodology by applying the identified optimizations to a proxy application, which improves the execution time, device utilization and power consumption by up to 29.6%, 5.3% and 26.5% respectively.
Read more8/20/2024

0
Optimizing Hardware Resource Partitioning and Job Allocations on Modern GPUs under Power Caps
Eishi Arima, Minjoon Kang, Issa Saba, Josef Weidendorfer, Carsten Trinitis, Martin Schulz
CPU-GPU heterogeneous systems are now commonly used in HPC (High-Performance Computing). However, improving the utilization and energy-efficiency of such systems is still one of the most critical issues. As one single program typically cannot fully utilize all resources within a node/chip, co-scheduling (or co-locating) multiple programs with complementary resource requirements is a promising solution. Meanwhile, as power consumption has become the first-class design constraint for HPC systems, such co-scheduling techniques should be well-tailored for power-constrained environments. To this end, the industry recently started supporting hardware-level resource partitioning features on modern GPUs for realizing efficient co-scheduling, which can operate with existing power capping features. For example, NVidia's MIG (Multi-Instance GPU) partitions one single GPU into multiple instances at the granularity of a GPC (Graphics Processing Cluster). In this paper, we explicitly target the combination of hardware-level GPU partitioning features and power capping for power-constrained HPC systems. We provide a systematic methodology to optimize the combination of chip partitioning, job allocations, as well as power capping based on our scalability/interference modeling while taking a variety of aspects into account, such as compute/memory intensity and utilization in heterogeneous computational resources (e.g., Tensor Cores). The experimental result indicates that our approach is successful in selecting a near optimal combination across multiple different workloads.
Read more5/8/2024
0
A Preliminary Study on Accelerating Simulation Optimization with GPU Implementation
Jinghai He, Haoyu Liu, Yuhang Wu, Zeyu Zheng, Tingyu Zhu
We provide a preliminary study on utilizing GPU (Graphics Processing Unit) to accelerate computation for three simulation optimization tasks with either first-order or second-order algorithms. Compared to the implementation using only CPU (Central Processing Unit), the GPU implementation benefits from computational advantages of parallel processing for large-scale matrices and vectors operations. Numerical experiments demonstrate computational advantages of utilizing GPU implementation in simulation optimization problems, and show that such advantage comparatively further increase as the problem scale increases.
Read more4/19/2024

0
A Comprehensive Analysis of Process Energy Consumption on Multi-Socket Systems with GPUs
Luis G. Le'on-Vega, Niccol`o Tosato, Stefano Cozzini
Robustly estimating energy consumption in High-Performance Computing (HPC) is essential for assessing the energy footprint of modern workloads, particularly in fields such as Artificial Intelligence (AI) research, development, and deployment. The extensive use of supercomputers for AI training has heightened concerns about energy consumption and carbon emissions. Existing energy estimation tools often assume exclusive use of computing nodes, a premise that becomes problematic with the advent of supercomputers integrating microservices, as seen in initiatives like Acceleration as a Service (XaaS) and cloud computing. This work investigates the impact of executed instructions on overall power consumption, providing insights into the comprehensive behaviour of HPC systems. We introduce two novel mathematical models to estimate a process's energy consumption based on the total node energy, process usage, and a normalised vector of the probability distribution of instruction types for CPU and GPU processes. Our approach enables energy accounting for specific processes without the need for isolation. Our models demonstrate high accuracy, predicting CPU power consumption with a mere 1.9% error. For GPU predictions, the models achieve a central relative error of 9.7%, showing a clear tendency to fit the test data accurately. These results pave the way for new tools to measure and account for energy consumption in shared supercomputing environments.
Read more9/10/2024