Optimizing Hardware Resource Partitioning and Job Allocations on Modern GPUs under Power Caps

0

Sign in to get full access
Overview
- This paper presents an approach for optimizing hardware resource partitioning and job allocations on modern GPUs under power caps.
- The authors introduce a technique called "orchestrated co-scheduling" that aims to improve GPU utilization and performance while staying within defined power budgets.
- The research investigates how to best partition GPU resources and schedule workloads to maximize throughput under power constraints.
Plain English Explanation
Modern GPUs are powerful but also energy-hungry, and data centers often need to cap the total power consumption of their GPU systems. This can limit the performance of GPU-accelerated applications. The researchers in this paper developed a new approach called "orchestrated co-scheduling" that tries to get the most out of GPU hardware while staying within defined power budgets.
The key idea is to carefully divide up the GPU's resources (like its processing cores and memory) and then schedule different types of workloads to run simultaneously on those partitions. By matching the right workloads together, the system can maximize overall GPU utilization and performance - even with a power cap in place.
For example, the technique might allocate half the GPU to run a highly parallel machine learning job, while the other half runs a more latency-sensitive video processing task. This "co-scheduling" allows the GPU to be used efficiently without exceeding the power limit.
The paper explores various algorithms and techniques for dividing up GPU resources and scheduling workloads in this way. The goal is to find the optimal configurations to get the best performance possible under different power constraints. This could be very useful for data centers and other organizations that need to run a variety of GPU-accelerated applications while keeping their overall power usage in check.
Technical Explanation
The paper introduces an orchestrated co-scheduling approach for optimizing hardware resource partitioning and job allocations on modern GPUs under power caps. The authors leverage malleability and performance modeling techniques to achieve high GPU utilization while staying within defined power budgets.
The proposed system dynamically partitions GPU resources, such as processing cores and memory, and schedules different types of workloads to run concurrently on those partitions. This "co-scheduling" approach aims to maximize overall GPU throughput by matching complementary workloads that can efficiently utilize the available resources.
The authors evaluate their techniques on large-scale GPU systems and demonstrate significant performance improvements over traditional GPU resource management approaches under power caps. The efficient multi-processor scheduling algorithms developed in this work enable data centers to run a diverse mix of GPU-accelerated applications while staying within their power constraints.
Critical Analysis
The paper provides a comprehensive and well-designed approach to optimizing GPU resource utilization under power caps. The proposed orchestrated co-scheduling technique appears to be a promising solution for addressing the challenge of running heterogeneous GPU workloads efficiently in power-constrained environments.
One potential limitation of the research is that it focuses primarily on synthetic benchmarks and simulations, rather than real-world production workloads. While the authors' experiments demonstrate the effectiveness of their algorithms, further validation on production systems with diverse and dynamic workloads would help strengthen the claims.
Additionally, the paper does not extensively explore the trade-offs between power, performance, and fairness in job scheduling. There may be scenarios where maximizing overall throughput could come at the expense of individual job performance or fair resource allocation. Investigating these nuances could lead to more balanced and practical scheduling policies.
Overall, the research presented in this paper represents a significant contribution to the field of GPU resource management and power-aware computing. The techniques developed could have important implications for the design and operation of large-scale data centers and HPC facilities that rely on energy-efficient GPU-accelerated computing.
Conclusion
This paper introduces an innovative approach called "orchestrated co-scheduling" for optimizing hardware resource partitioning and job allocations on modern GPUs under power caps. By dynamically dividing GPU resources and scheduling complementary workloads to run concurrently, the system can maximize overall GPU utilization and performance while staying within defined power budgets.
The techniques developed in this work could be highly valuable for data centers and other organizations that need to run a diverse mix of GPU-accelerated applications in an energy-efficient manner. The research represents an important advancement in the field of power-aware computing and could inspire further innovations in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimizing Hardware Resource Partitioning and Job Allocations on Modern GPUs under Power Caps
Eishi Arima, Minjoon Kang, Issa Saba, Josef Weidendorfer, Carsten Trinitis, Martin Schulz
CPU-GPU heterogeneous systems are now commonly used in HPC (High-Performance Computing). However, improving the utilization and energy-efficiency of such systems is still one of the most critical issues. As one single program typically cannot fully utilize all resources within a node/chip, co-scheduling (or co-locating) multiple programs with complementary resource requirements is a promising solution. Meanwhile, as power consumption has become the first-class design constraint for HPC systems, such co-scheduling techniques should be well-tailored for power-constrained environments. To this end, the industry recently started supporting hardware-level resource partitioning features on modern GPUs for realizing efficient co-scheduling, which can operate with existing power capping features. For example, NVidia's MIG (Multi-Instance GPU) partitions one single GPU into multiple instances at the granularity of a GPC (Graphics Processing Cluster). In this paper, we explicitly target the combination of hardware-level GPU partitioning features and power capping for power-constrained HPC systems. We provide a systematic methodology to optimize the combination of chip partitioning, job allocations, as well as power capping based on our scalability/interference modeling while taking a variety of aspects into account, such as compute/memory intensity and utilization in heterogeneous computational resources (e.g., Tensor Cores). The experimental result indicates that our approach is successful in selecting a near optimal combination across multiple different workloads.
Read more5/8/2024
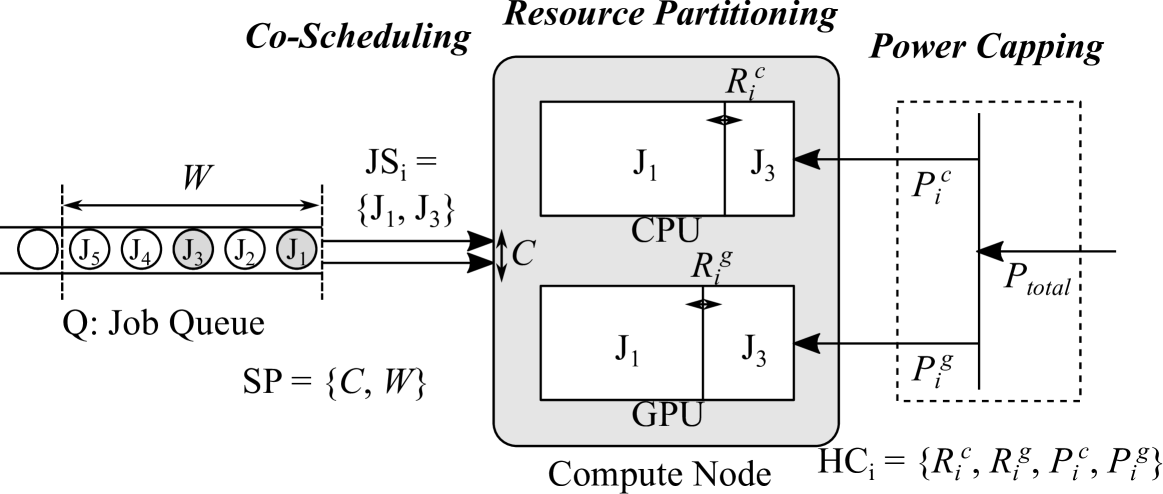
0
Orchestrated Co-scheduling, Resource Partitioning, and Power Capping on CPU-GPU Heterogeneous Systems via Machine Learning
Issa Saba, Eishi Arima, Dai Liu, Martin Schulz
CPU-GPU heterogeneous architectures are now commonly used in a wide variety of computing systems from mobile devices to supercomputers. Maximizing the throughput for multi-programmed workloads on such systems is indispensable as one single program typically cannot fully exploit all available resources. At the same time, power consumption is a key issue and often requires optimizing power allocations to the CPU and GPU while enforcing a total power constraint, in particular when the power/thermal requirements are strict. The result is a system-wide optimization problem with several knobs. In particular we focus on (1) co-scheduling decisions, i.e., selecting programs to co-locate in a space sharing manner; (2) resource partitioning on both CPUs and GPUs; and (3) power capping on both CPUs and GPUs. We solve this problem using predictive performance modeling using machine learning in order to coordinately optimize the above knob setups. Our experiential results using a real system show that our approach achieves up to 67% of speedup compared to a time-sharing-based scheduling with a naive power capping that evenly distributes power budgets across components.
Read more5/8/2024
🏅
0
Hierarchical Resource Partitioning on Modern GPUs: A Reinforcement Learning Approach
Urvij Saroliya, Eishi Arima, Dai Liu, Martin Schulz
GPU-based heterogeneous architectures are now commonly used in HPC clusters. Due to their architectural simplicity specialized for data-level parallelism, GPUs can offer much higher computational throughput and memory bandwidth than CPUs in the same generation do. However, as the available resources in GPUs have increased exponentially over the past decades, it has become increasingly difficult for a single program to fully utilize them. As a consequence, the industry has started supporting several resource partitioning features in order to improve the resource utilization by co-scheduling multiple programs on the same GPU die at the same time. Driven by the technological trend, this paper focuses on hierarchical resource partitioning on modern GPUs, and as an example, we utilize a combination of two different features available on recent NVIDIA GPUs in a hierarchical manner: MPS (Multi-Process Service), a finer-grained logical partitioning; and MIG (Multi-Instance GPU), a coarse-grained physical partitioning. We propose a method for comprehensively co-optimizing the setup of hierarchical partitioning and the selection of co-scheduling groups from a given set of jobs, based on reinforcement learning using their profiles. Our thorough experimental results demonstrate that our approach can successfully set up job concurrency, partitioning, and co-scheduling group selections simultaneously. This results in a maximum throughput improvement by a factor of 1.87 compared to the time-sharing scheduling.
Read more5/15/2024
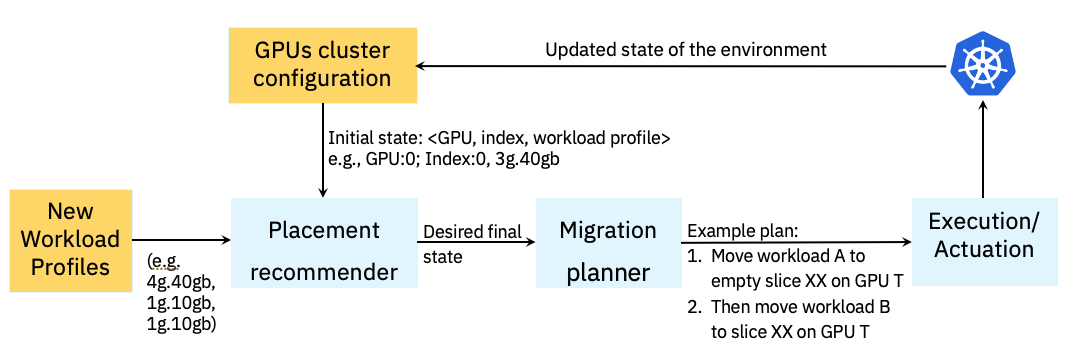
0
Optimal Workload Placement on Multi-Instance GPUs
Bekir Turkkan, Pavankumar Murali, Pavithra Harsha, Rohan Arora, Gerard Vanloo, Chandra Narayanaswami
There is an urgent and pressing need to optimize usage of Graphical Processing Units (GPUs), which have arguably become one of the most expensive and sought after IT resources. To help with this goal, several of the current generation of GPUs support a partitioning feature, called Multi-Instance GPU (MIG) to allow multiple workloads to share a GPU, albeit with some constraints. In this paper we investigate how to optimize the placement of Large Language Model (LLM)-based AI Inferencing workloads on GPUs. We first identify and present several use cases that are encountered in practice that require workloads to be efficiently placed or migrated to other GPUs to make room for incoming workloads. The overarching goal is to use as few GPUs as possible and to further minimize memory and compute wastage on GPUs that are utilized. We have developed two approaches to address this problem: an optimization method and a heuristic method. We benchmark these with two workload scheduling heuristics for multiple use cases. Our results show up to 2.85x improvement in the number of GPUs used and up to 70% reduction in GPU wastage over baseline heuristics. We plan to enable the SRE community to leverage our proposed method in production environments.
Read more9/11/2024