Data-Driven Estimation of Conditional Expectations, Application to Optimal Stopping and Reinforcement Learning

0
Sign in to get full access
Overview
- Data-driven estimation of conditional expectations
- Application to optimal stopping and reinforcement learning
- Uses neural networks to estimate conditional expectations from data
Plain English Explanation
Data-driven estimation refers to using machine learning techniques, like neural networks, to estimate quantities of interest from observed data, rather than relying on analytical models. In this paper, the authors focus on estimating conditional expectations, which are important for solving problems in optimal stopping and reinforcement learning.
Optimal stopping problems arise when you need to decide the best time to take an action, like selling a stock or exercising an option. Reinforcement learning is a type of machine learning where an agent learns to take actions in an environment to maximize some reward.
The key insight of this paper is that by using neural networks to estimate the relevant conditional expectations, you can solve these types of problems more effectively, without needing to make restrictive assumptions about the underlying mathematical models. The neural networks can capture complex, nonlinear relationships in the data.
The authors demonstrate the effectiveness of their data-driven approach on several example problems, showing how it can outperform traditional analytical methods.
Technical Explanation
The paper presents a framework for data-driven estimation of conditional expectations and applies it to problems in optimal stopping and reinforcement learning.
The core idea is to use neural networks to directly estimate the relevant conditional expectations from observed data, rather than relying on analytical models that make simplifying assumptions. This allows the method to capture complex, nonlinear relationships in the data.
For optimal stopping, the authors show how to use the estimated conditional expectations to determine the optimal stopping rule. Link to optimal stopping section
For reinforcement learning, they incorporate the conditional expectation estimates into the Bellman equation, the fundamental equation that governs the optimal value function. Link to reinforcement learning section
The authors evaluate their approach on several benchmark problems, demonstrating that it can outperform traditional analytical methods, especially in cases with complex, high-dimensional state spaces.
Critical Analysis
The paper provides a strong theoretical foundation and empirical evidence for the benefits of data-driven conditional expectation estimation. However, a few potential limitations or areas for future work are worth noting:
-
The neural network architectures and training procedures used in the experiments are relatively standard. Exploring more advanced neural network designs or meta-learning approaches could potentially further improve performance.
-
The paper focuses on single-agent settings. Extending the data-driven approach to multi-agent or adversarial environments, as found in many real-world applications, would be an interesting direction. Link to multi-agent systems
-
While the paper demonstrates the effectiveness of the approach on benchmark problems, more work is needed to understand its scalability and robustness to real-world complexities, such as partial observability, non-stationarity, and noisy data. Link to scalability and robustness
Overall, this paper makes an important contribution by showcasing the power of data-driven conditional expectation estimation for solving complex decision-making problems. The ideas presented here could have a significant impact on the fields of optimal stopping and reinforcement learning.
Conclusion
This paper introduces a data-driven approach to estimating conditional expectations and demonstrates its effectiveness for solving problems in optimal stopping and reinforcement learning. By using neural networks to directly learn from observed data, the method can capture complex, nonlinear relationships without relying on restrictive analytical assumptions.
The authors show that this data-driven approach can outperform traditional analytical methods, especially in high-dimensional, complex environments. While the paper focuses on single-agent settings, the ideas presented here could be extended to multi-agent and more realistic real-world scenarios, potentially leading to significant advancements in decision-making and control systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data-Driven Estimation of Conditional Expectations, Application to Optimal Stopping and Reinforcement Learning
George V. Moustakides
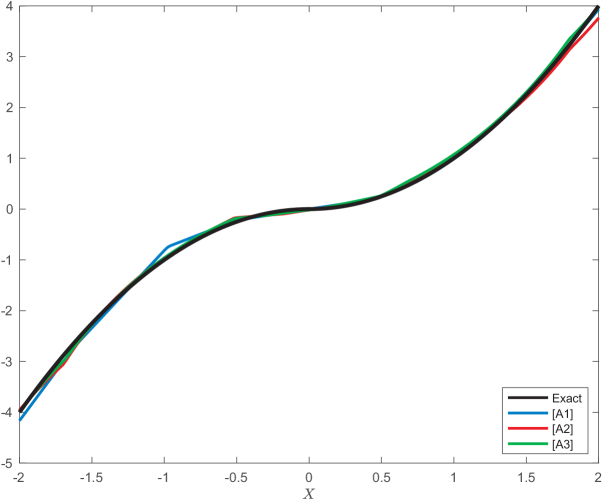
When the underlying conditional density is known, conditional expectations can be computed analytically or numerically. When, however, such knowledge is not available and instead we are given a collection of training data, the goal of this work is to propose simple and purely data-driven means for estimating directly the desired conditional expectation. Because conditional expectations appear in the description of a number of stochastic optimization problems with the corresponding optimal solution satisfying a system of nonlinear equations, we extend our data-driven method to cover such cases as well. We test our methodology by applying it to Optimal Stopping and Optimal Action Policy in Reinforcement Learning.
Read more7/19/2024
🏅
0
Post Reinforcement Learning Inference
Vasilis Syrgkanis, Ruohan Zhan
We consider estimation and inference using data collected from reinforcement learning algorithms. These algorithms, characterized by their adaptive experimentation, interact with individual units over multiple stages, dynamically adjusting their strategies based on previous interactions. Our goal is to evaluate a counterfactual policy post-data collection and estimate structural parameters, like dynamic treatment effects, which can be used for credit assignment and determining the effect of earlier actions on final outcomes. Such parameters of interest can be framed as solutions to moment equations, but not minimizers of a population loss function, leading to Z-estimation approaches for static data. However, in the adaptive data collection environment of reinforcement learning, where algorithms deploy nonstationary behavior policies, standard estimators do not achieve asymptotic normality due to the fluctuating variance. We propose a weighted Z-estimation approach with carefully designed adaptive weights to stabilize the time-varying estimation variance. We identify proper weighting schemes to restore the consistency and asymptotic normality of the weighted Z-estimators for target parameters, which allows for hypothesis testing and constructing uniform confidence regions. Primary applications include dynamic treatment effect estimation and dynamic off-policy evaluation.
Read more5/14/2024

0
Conditional Bayesian Quadrature
Zonghao Chen, Masha Naslidnyk, Arthur Gretton, Franc{c}ois-Xavier Briol
We propose a novel approach for estimating conditional or parametric expectations in the setting where obtaining samples or evaluating integrands is costly. Through the framework of probabilistic numerical methods (such as Bayesian quadrature), our novel approach allows to incorporates prior information about the integrands especially the prior smoothness knowledge about the integrands and the conditional expectation. As a result, our approach provides a way of quantifying uncertainty and leads to a fast convergence rate, which is confirmed both theoretically and empirically on challenging tasks in Bayesian sensitivity analysis, computational finance and decision making under uncertainty.
Read more6/26/2024
0
A Functional Model Method for Nonconvex Nonsmooth Conditional Stochastic Optimization
Andrzej Ruszczy'nski, Shangzhe Yang
We consider stochastic optimization problems involving an expected value of a nonlinear function of a base random vector and a conditional expectation of another function depending on the base random vector, a dependent random vector, and the decision variables. We call such problems conditional stochastic optimization problems. They arise in many applications, such as uplift modeling, reinforcement learning, and contextual optimization. We propose a specialized single time-scale stochastic method for nonconvex constrained conditional stochastic optimization problems with a Lipschitz smooth outer function and a generalized differentiable inner function. In the method, we approximate the inner conditional expectation with a rich parametric model whose mean squared error satisfies a stochastic version of a {L}ojasiewicz condition. The model is used by an inner learning algorithm. The main feature of our approach is that unbiased stochastic estimates of the directions used by the method can be generated with one observation from the joint distribution per iteration, which makes it applicable to real-time learning. The directions, however, are not gradients or subgradients of any overall objective function. We prove the convergence of the method with probability one, using the method of differential inclusions and a specially designed Lyapunov function, involving a stochastic generalization of the Bregman distance. Finally, a numerical illustration demonstrates the viability of our approach.
Read more5/20/2024