Data Efficient Child-Adult Speaker Diarization with Simulated Conversations

0

Sign in to get full access
Overview
- Focuses on improving child-adult speaker diarization, a key task in speech recognition
- Proposes a data-efficient approach using simulated conversations to train deep learning models
- Aims to address the challenge of limited real-world child speech data available for model training
Plain English Explanation
The provided paper focuses on improving a critical task in speech recognition called speaker diarization - the ability to accurately identify which speaker is talking at any given time. This is particularly challenging when dealing with conversations that involve both children and adults, as children's speech patterns can differ significantly from adults'.
To address this challenge, the researchers have developed a data-efficient approach that leverages simulated conversations to train deep learning models for child-adult speaker diarization. The key insight is that by creating realistic simulated conversations, they can generate a large and diverse dataset to train their models, without the need for costly and time-consuming collection of real-world child speech data, which is often scarce.
The researchers' approach aims to bridge the performance gap between child and adult speaker diarization, ultimately enabling more accurate and reliable speech recognition systems that can handle a wider range of speaker profiles, including children.
Technical Explanation
The paper presents a data-efficient approach to child-adult speaker diarization, leveraging a simulated dataset of conversational audio. The researchers first collected a diverse corpus of adult speech and then used this data to generate realistic simulated conversations, where child speech is synthetically added.
The simulated conversations are then used to train a deep learning-based diarization model, which learns to accurately identify the speaker (child or adult) at any given time in the audio. The model architecture combines a speaker embedding network with a temporal clustering module to perform the diarization task.
The researchers evaluated their approach on both the simulated dataset and a small-scale real-world dataset of child-adult conversations. The results demonstrate that the model trained on the simulated data can achieve competitive performance on the real-world task, highlighting the data-efficiency of the proposed approach.
Critical Analysis
The paper presents a novel and promising approach to addressing the challenge of limited real-world child speech data for training speaker diarization models. The use of simulated conversations to generate a large and diverse training dataset is a clever solution, and the researchers have demonstrated the effectiveness of this approach through their experiments.
However, it's important to note that the real-world dataset used for evaluation is quite small, and the researchers acknowledge that further validation on larger-scale real-world datasets would be necessary to fully assess the generalization capabilities of their model. Additionally, the simulation process itself may not capture all the nuances and complexities of real-world child-adult conversations, which could potentially limit the model's performance in certain scenarios.
It would also be valuable for the researchers to explore the transferability of their approach to other domains or languages, as the ability to leverage simulated data could have broader implications for speech recognition research.
Conclusion
The paper presents a data-efficient approach to child-adult speaker diarization, which addresses the challenge of limited real-world child speech data. By leveraging simulated conversations, the researchers have developed a deep learning-based model that can achieve competitive performance on this critical speech recognition task.
The proposed method has the potential to significantly improve the accuracy and reliability of speech recognition systems, especially in scenarios involving children. The data-efficient nature of the approach also suggests that it could be applied to other speech-related tasks where data scarcity is a concern.
Overall, this research represents an important step forward in the field of speaker diarization, with the promise of enabling more inclusive and accessible speech recognition technologies for a wider range of users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Data Efficient Child-Adult Speaker Diarization with Simulated Conversations
Anfeng Xu, Tiantian Feng, Helen Tager-Flusberg, Catherine Lord, Shrikanth Narayanan
Automating child speech analysis is crucial for applications such as neurocognitive assessments. Speaker diarization, which identifies ``who spoke when'', is an essential component of the automated analysis. However, publicly available child-adult speaker diarization solutions are scarce due to privacy concerns and a lack of annotated datasets, while manually annotating data for each scenario is both time-consuming and costly. To overcome these challenges, we propose a data-efficient solution by creating simulated child-adult conversations using AudioSet. We then train a Whisper Encoder-based model, achieving strong zero-shot performance on child-adult speaker diarization using real datasets. The model performance improves substantially when fine-tuned with only 30 minutes of real train data, with LoRA further improving the transfer learning performance. The source code and the child-adult speaker diarization model trained on simulated conversations are publicly available.
Read more9/16/2024
🚀
0
Kid-Whisper: Towards Bridging the Performance Gap in Automatic Speech Recognition for Children VS. Adults
Ahmed Adel Attia, Jing Liu, Wei Ai, Dorottya Demszky, Carol Espy-Wilson
Recent advancements in Automatic Speech Recognition (ASR) systems, exemplified by Whisper, have demonstrated the potential of these systems to approach human-level performance given sufficient data. However, this progress doesn't readily extend to ASR for children due to the limited availability of suitable child-specific databases and the distinct characteristics of children's speech. A recent study investigated leveraging the My Science Tutor (MyST) children's speech corpus to enhance Whisper's performance in recognizing children's speech. They were able to demonstrate some improvement on a limited testset. This paper builds on these findings by enhancing the utility of the MyST dataset through more efficient data preprocessing. We reduce the Word Error Rate (WER) on the MyST testset 13.93% to 9.11% with Whisper-Small and from 13.23% to 8.61% with Whisper-Medium and show that this improvement can be generalized to unseen datasets. We also highlight important challenges towards improving children's ASR performance. The results showcase the viable and efficient integration of Whisper for effective children's speech recognition.
Read more5/16/2024
0
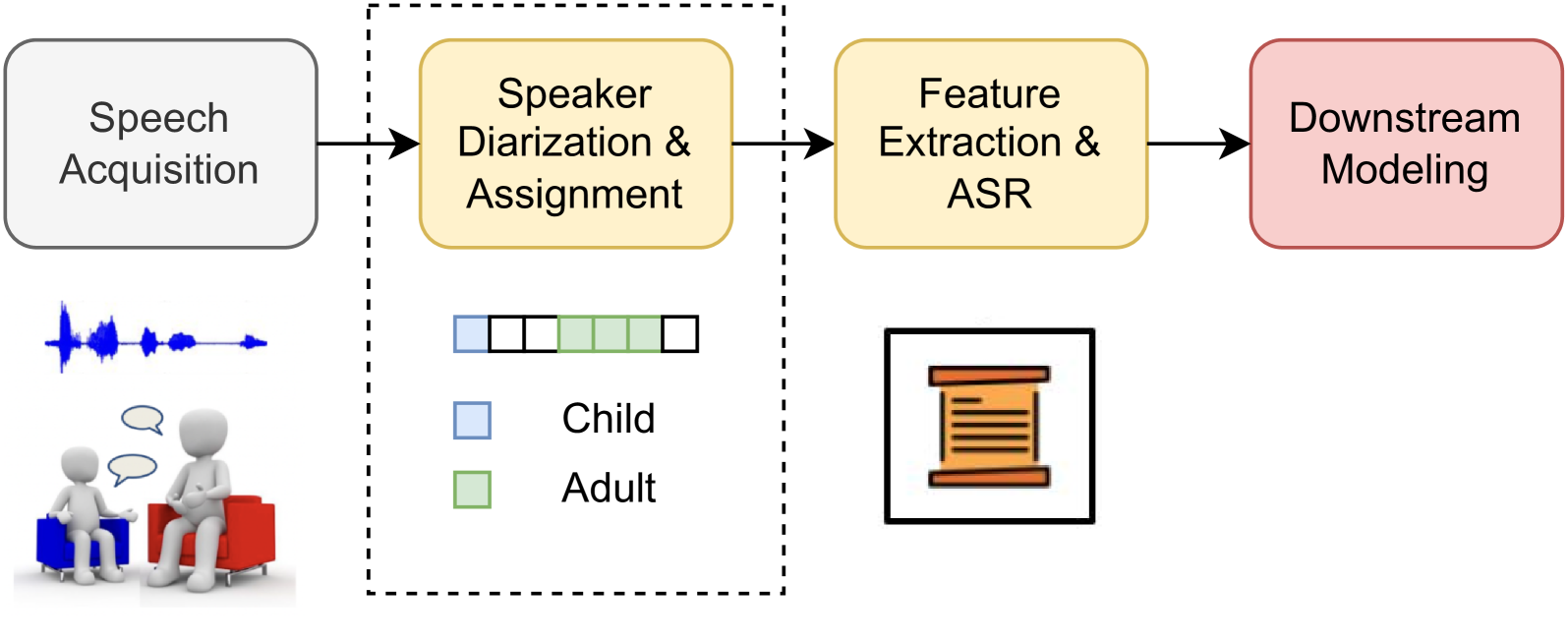
Exploring Speech Foundation Models for Speaker Diarization in Child-Adult Dyadic Interactions
Anfeng Xu, Kevin Huang, Tiantian Feng, Lue Shen, Helen Tager-Flusberg, Shrikanth Narayanan
Speech foundation models, trained on vast datasets, have opened unique opportunities in addressing challenging low-resource speech understanding, such as child speech. In this work, we explore the capabilities of speech foundation models on child-adult speaker diarization. We show that exemplary foundation models can achieve 39.5% and 62.3% relative reductions in Diarization Error Rate and Speaker Confusion Rate, respectively, compared to previous speaker diarization methods. In addition, we benchmark and evaluate the speaker diarization results of the speech foundation models with varying the input audio window size, speaker demographics, and training data ratio. Our results highlight promising pathways for understanding and adopting speech foundation models to facilitate child speech understanding.
Read more6/13/2024
0
Who Said What? An Automated Approach to Analyzing Speech in Preschool Classrooms
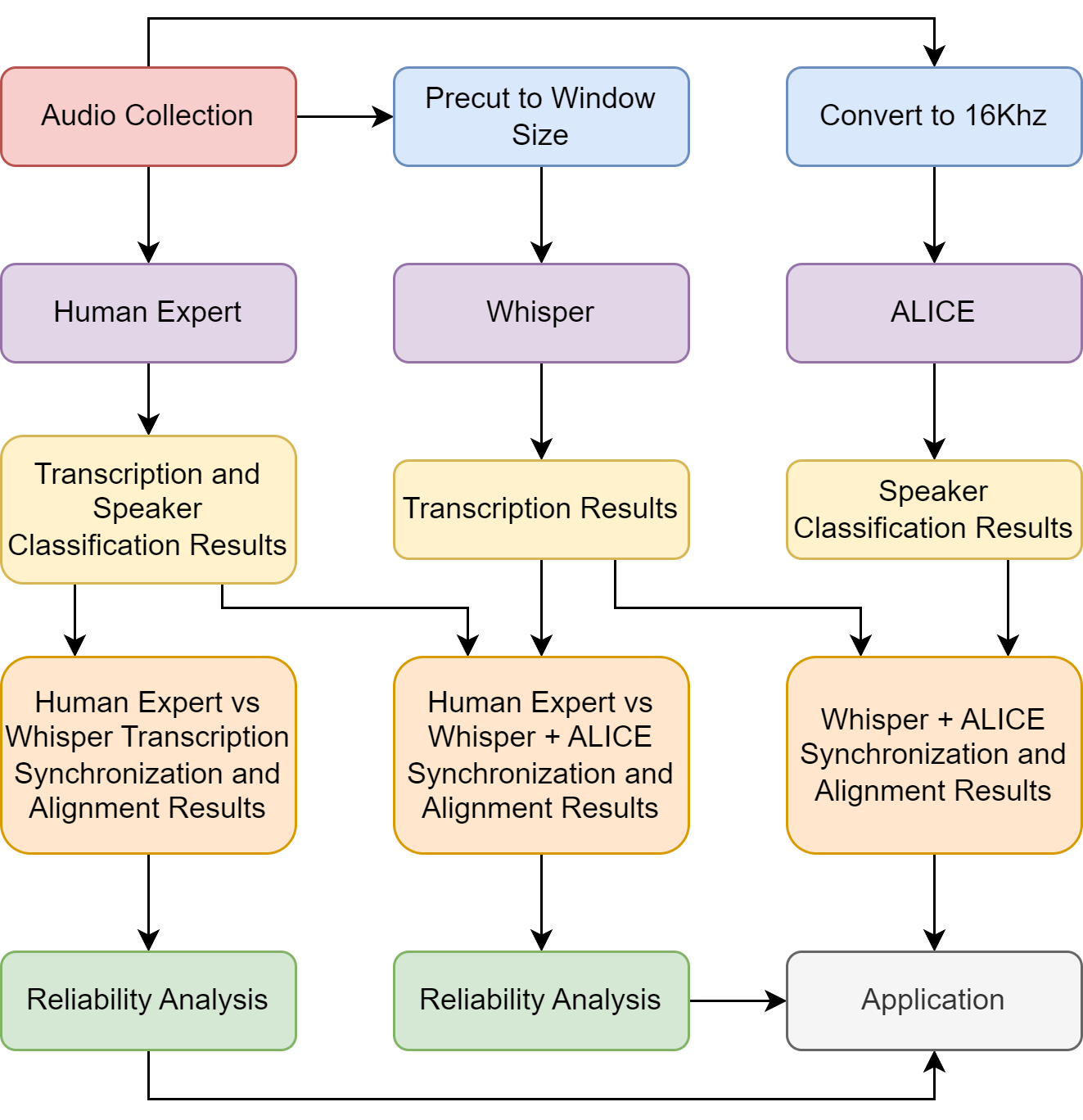
Anchen Sun, Juan J Londono, Batya Elbaum, Luis Estrada, Roberto Jose Lazo, Laura Vitale, Hugo Gonzalez Villasanti, Riccardo Fusaroli, Lynn K Perry, Daniel S Messinger
Young children spend substantial portions of their waking hours in noisy preschool classrooms. In these environments, children's vocal interactions with teachers are critical contributors to their language outcomes, but manually transcribing these interactions is prohibitive. Using audio from child- and teacher-worn recorders, we propose an automated framework that uses open source software both to classify speakers (ALICE) and to transcribe their utterances (Whisper). We compare results from our framework to those from a human expert for 110 minutes of classroom recordings, including 85 minutes from child-word microphones (n=4 children) and 25 minutes from teacher-worn microphones (n=2 teachers). The overall proportion of agreement, that is, the proportion of correctly classified teacher and child utterances, was .76, with an error-corrected kappa of .50 and a weighted F1 of .76. The word error rate for both teacher and child transcriptions was .15, meaning that 15% of words would need to be deleted, added, or changed to equate the Whisper and expert transcriptions. Moreover, speech features such as the mean length of utterances in words, the proportion of teacher and child utterances that were questions, and the proportion of utterances that were responded to within 2.5 seconds were similar when calculated separately from expert and automated transcriptions. The results suggest substantial progress in analyzing classroom speech that may support children's language development. Future research using natural language processing is under way to improve speaker classification and to analyze results from the application of the automated framework to a larger dataset containing classroom recordings from 13 children and 3 teachers observed on 17 occasions over one year.
Read more4/12/2024