Exploring Speech Foundation Models for Speaker Diarization in Child-Adult Dyadic Interactions

0
Sign in to get full access
Overview
- This research paper explores the use of speech foundation models for speaker diarization in child-adult dyadic interactions.
- Speaker diarization is the process of identifying who spoke when in an audio recording.
- The paper investigates how well different speech foundation models, which are pre-trained on large speech datasets, can be used for this task in conversations between children and adults.
Plain English Explanation
Speech foundation models are powerful AI systems that have been trained on massive amounts of audio data to learn how to understand and process speech. These models can be used for a variety of speech-related tasks, such as speech translation, speech recognition, and speaker identification.
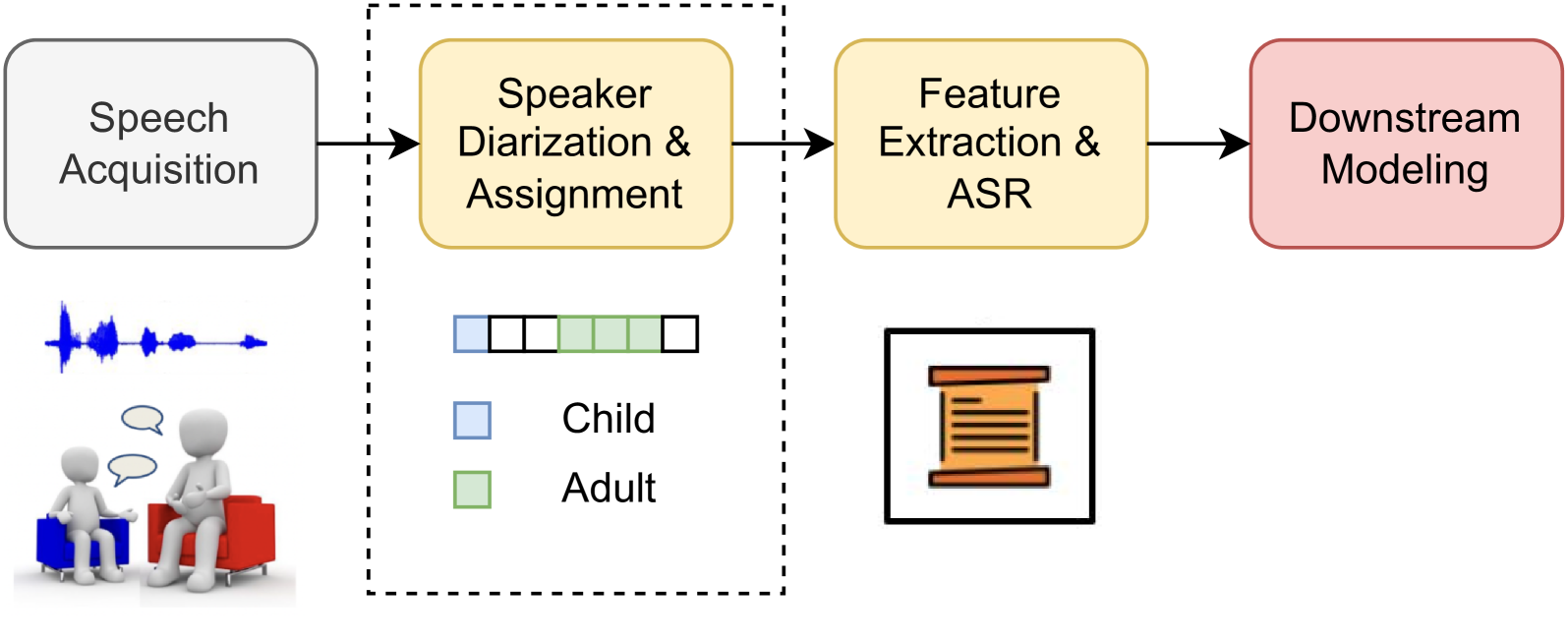
In this paper, the researchers wanted to see how well these speech foundation models could be used for speaker diarization in conversations between children and adults. Speaker diarization is the process of figuring out who is speaking at different points in an audio recording. This is a challenging task, especially for child-adult interactions, which can have a lot of overlap and complex speaking patterns.
The researchers tested out several different speech foundation models to see which ones worked best for this task. They found that some models were better than others at accurately identifying the different speakers in the recordings. This could be useful for things like analyzing children's speech or improving speaker diarization systems.
Technical Explanation
The paper evaluates the performance of various speech foundation models for the task of speaker diarization in child-adult dyadic interactions. The researchers used several state-of-the-art speech foundation models, including HuBERT, XLSR-Wav2Vec, and SpeechT5, and tested them on a dataset of child-adult conversations.
The experiment design involved fine-tuning the speech foundation models on the speaker diarization task and comparing their performance against a baseline system that did not use pre-trained models. The researchers measured metrics such as diarization error rate (DER) and speaker precision and recall to assess the models' ability to accurately identify the speakers in the recordings.
The results show that the speech foundation models generally outperformed the baseline system, with the XLSR-Wav2Vec model achieving the best overall performance. The paper also provides insights into the strengths and weaknesses of the different models, such as their ability to handle overlapping speech and their robustness to variations in audio quality and speaker characteristics.
Critical Analysis
The paper provides a valuable contribution to the field of speaker diarization, particularly in the context of child-adult interactions, which can be challenging due to the complex speaking patterns and overlapping speech. The use of pre-trained speech foundation models is a promising approach, as these models have been shown to capture rich linguistic and acoustic representations that can be leveraged for various speech-related tasks.
However, the paper also acknowledges some limitations of the research. For example, the dataset used for the experiments was relatively small, and the performance of the models may vary on larger or more diverse datasets. Additionally, the paper does not explore the potential biases or fairness issues that may arise when using these models, particularly in the context of child speech, which can be influenced by factors such as age, gender, and socioeconomic status.
Further research could investigate the performance of these models on a wider range of child-adult interaction scenarios, as well as explore techniques for improving the models' robustness and fairness. Additionally, it would be valuable to investigate the potential applications of this technology, such as in educational settings or for analyzing children's language development.
Conclusion
This paper presents an important exploration of the use of speech foundation models for speaker diarization in child-adult dyadic interactions. The findings suggest that these pre-trained models can outperform traditional approaches, offering a promising avenue for improving the accuracy and robustness of speaker diarization systems. While the research has some limitations, it represents a valuable step forward in the ongoing efforts to develop more advanced speech processing technologies that can better understand and analyze human communication, particularly in the context of child development and education.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring Speech Foundation Models for Speaker Diarization in Child-Adult Dyadic Interactions
Anfeng Xu, Kevin Huang, Tiantian Feng, Lue Shen, Helen Tager-Flusberg, Shrikanth Narayanan
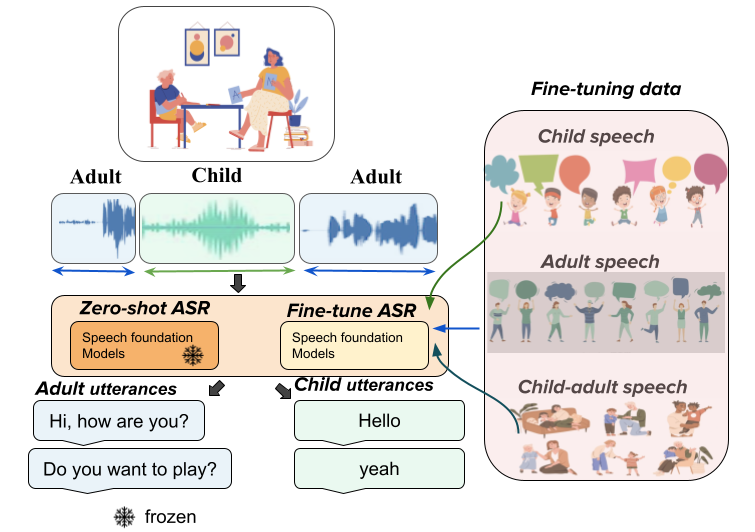
Speech foundation models, trained on vast datasets, have opened unique opportunities in addressing challenging low-resource speech understanding, such as child speech. In this work, we explore the capabilities of speech foundation models on child-adult speaker diarization. We show that exemplary foundation models can achieve 39.5% and 62.3% relative reductions in Diarization Error Rate and Speaker Confusion Rate, respectively, compared to previous speaker diarization methods. In addition, we benchmark and evaluate the speaker diarization results of the speech foundation models with varying the input audio window size, speaker demographics, and training data ratio. Our results highlight promising pathways for understanding and adopting speech foundation models to facilitate child speech understanding.
Read more6/13/2024
0
Evaluation of state-of-the-art ASR Models in Child-Adult Interactions
Aditya Ashvin, Rimita Lahiri, Aditya Kommineni, Somer Bishop, Catherine Lord, Sudarsana Reddy Kadiri, Shrikanth Narayanan
The ability to reliably transcribe child-adult conversations in a clinical setting is valuable for diagnosis and understanding of numerous developmental disorders such as Autism Spectrum Disorder. Recent advances in deep learning architectures and availability of large scale transcribed data has led to development of speech foundation models that have shown dramatic improvements in ASR performance. However, the ability of these models to translate well to conversational child-adult interactions is under studied. In this work, we provide a comprehensive evaluation of ASR performance on a dataset containing child-adult interactions from autism diagnostic sessions, using Whisper, Wav2Vec2, HuBERT, and WavLM. We find that speech foundation models show a noticeable performance drop (15-20% absolute WER) for child speech compared to adult speech in the conversational setting. Then, we employ LoRA on the best performing zero shot model (whisper-large) to probe the effectiveness of fine-tuning in a low resource setting, resulting in ~8% absolute WER improvement for child speech and ~13% absolute WER improvement for adult speech.
Read more9/25/2024

0
A Large-Scale Evaluation of Speech Foundation Models
Shu-wen Yang, Heng-Jui Chang, Zili Huang, Andy T. Liu, Cheng-I Lai, Haibin Wu, Jiatong Shi, Xuankai Chang, Hsiang-Sheng Tsai, Wen-Chin Huang, Tzu-hsun Feng, Po-Han Chi, Yist Y. Lin, Yung-Sung Chuang, Tzu-Hsien Huang, Wei-Cheng Tseng, Kushal Lakhotia, Shang-Wen Li, Abdelrahman Mohamed, Shinji Watanabe, Hung-yi Lee
The foundation model paradigm leverages a shared foundation model to achieve state-of-the-art (SOTA) performance for various tasks, requiring minimal downstream-specific modeling and data annotation. This approach has proven crucial in the field of Natural Language Processing (NLP). However, the speech processing community lacks a similar setup to explore the paradigm systematically. In this work, we establish the Speech processing Universal PERformance Benchmark (SUPERB) to study the effectiveness of the paradigm for speech. We propose a unified multi-tasking framework to address speech processing tasks in SUPERB using a frozen foundation model followed by task-specialized, lightweight prediction heads. Combining our results with community submissions, we verify that the foundation model paradigm is promising for speech, and our multi-tasking framework is simple yet effective, as the best-performing foundation model shows competitive generalizability across most SUPERB tasks. For reproducibility and extensibility, we have developed a long-term maintained platform that enables deterministic benchmarking, allows for result sharing via an online leaderboard, and promotes collaboration through a community-driven benchmark database to support new development cycles. Finally, we conduct a series of analyses to offer an in-depth understanding of SUPERB and speech foundation models, including information flows across tasks inside the models, the correctness of the weighted-sum benchmarking protocol and the statistical significance and robustness of the benchmark.
Read more5/31/2024

0
Data Efficient Child-Adult Speaker Diarization with Simulated Conversations
Anfeng Xu, Tiantian Feng, Helen Tager-Flusberg, Catherine Lord, Shrikanth Narayanan
Automating child speech analysis is crucial for applications such as neurocognitive assessments. Speaker diarization, which identifies ``who spoke when'', is an essential component of the automated analysis. However, publicly available child-adult speaker diarization solutions are scarce due to privacy concerns and a lack of annotated datasets, while manually annotating data for each scenario is both time-consuming and costly. To overcome these challenges, we propose a data-efficient solution by creating simulated child-adult conversations using AudioSet. We then train a Whisper Encoder-based model, achieving strong zero-shot performance on child-adult speaker diarization using real datasets. The model performance improves substantially when fine-tuned with only 30 minutes of real train data, with LoRA further improving the transfer learning performance. The source code and the child-adult speaker diarization model trained on simulated conversations are publicly available.
Read more9/16/2024