Data Valuation by Leveraging Global and Local Statistical Information

0
📊
Sign in to get full access
Overview
- The paper explores methods for quantifying the value of data within a corpus, particularly in the context of machine learning tasks.
- It examines the potential of using global and local statistical information of value distributions to improve data valuation.
- The authors propose a new data valuation method that incorporates value distribution characteristics and a new approach to address dynamic data valuation.
- Extensive experiments are conducted to evaluate the effectiveness and efficiency of the proposed methodologies.
Plain English Explanation
Data is essential for training machine learning models, and understanding the value of data is crucial. Shapley value-based methods are widely used, but accurately calculating Shapley values can be computationally challenging.
This paper suggests that considering the distribution of values within a data corpus could provide valuable insights for data valuation. The authors first explore the characteristics of both global (overall) and local (within subsets) value distributions across different data sets. They then propose a new data valuation method that incorporates these distribution characteristics into an existing Shapley value estimation technique called AME.
Additionally, the authors present a new approach to address the problem of dynamic data valuation, where the value of data changes over time. They formulate an optimization problem that integrates information about both global and local value distributions to tackle this challenge.
Through extensive experiments, the researchers demonstrate the effectiveness and efficiency of their proposed methodologies. The results indicate that leveraging information about value distributions can significantly improve data valuation, enabling better data management and model performance.
Technical Explanation
The paper begins by exploring the characteristics of both global and local value distributions across several simulated and real data corpora. This analysis provides useful insights into the patterns and trends within these value distributions.
Next, the authors propose a new data valuation method that builds upon the Approximate Minimum Effort (AME) technique for estimating Shapley values. By incorporating the explored distribution characteristics, the proposed method aims to improve the accuracy and efficiency of Shapley value estimation.
To address the dynamic data valuation problem, the researchers formulate an optimization problem that integrates information about both global and local value distributions. This novel approach allows for the valuation of data to be updated as the data corpus changes over time, accounting for the evolving value landscape.
The experimental evaluation covers several aspects, including Shapley value estimation, value-based data removal/addition, mislabeled data detection, and incremental/decremental data valuation. The results demonstrate the effectiveness and efficiency of the proposed methodologies, highlighting the significant potential of leveraging global and local value distribution information for data valuation.
Critical Analysis
The paper presents a comprehensive and innovative approach to data valuation, emphasizing the importance of incorporating distribution information. The authors' exploration of global and local value distributions provides valuable insights that can inform more accurate and efficient data valuation techniques.
One potential limitation of the research is the reliance on simulated data and a limited number of real-world data sets. It would be beneficial to expand the evaluation to a wider range of real-world scenarios to assess the generalizability of the proposed methods.
Additionally, while the authors address the dynamic data valuation problem, there may be other factors, such as concept drift or changes in task objectives, that could further complicate the data valuation process. Incorporating these considerations into the proposed framework could enhance its practical applicability.
Further research could investigate the impact of different value distribution characteristics on the performance of data valuation methods, as well as explore the potential trade-offs between global and local distribution information in various application domains.
Conclusion
This paper demonstrates the significant potential of leveraging global and local value distribution information for data valuation in the context of machine learning. The proposed methodologies, which incorporate distribution characteristics into Shapley value estimation and dynamic data valuation, have shown promising results in terms of accuracy and efficiency.
By highlighting the importance of considering value distributions, this research opens up new avenues for improving data management and model development. The insights gained from this work could have far-reaching implications for various applications that rely on high-quality data, ultimately contributing to the advancement of machine learning and its real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Data Valuation by Leveraging Global and Local Statistical Information
Xiaoling Zhou, Ou Wu, Michael K. Ng, Hao Jiang
Data valuation has garnered increasing attention in recent years, given the critical role of high-quality data in various applications, particularly in machine learning tasks. There are diverse technical avenues to quantify the value of data within a corpus. While Shapley value-based methods are among the most widely used techniques in the literature due to their solid theoretical foundation, the accurate calculation of Shapley values is often intractable, leading to the proposal of numerous approximated calculation methods. Despite significant progress, nearly all existing methods overlook the utilization of distribution information of values within a data corpus. In this paper, we demonstrate that both global and local statistical information of value distributions hold significant potential for data valuation within the context of machine learning. Firstly, we explore the characteristics of both global and local value distributions across several simulated and real data corpora. Useful observations and clues are obtained. Secondly, we propose a new data valuation method that estimates Shapley values by incorporating the explored distribution characteristics into an existing method, AME. Thirdly, we present a new path to address the dynamic data valuation problem by formulating an optimization problem that integrates information of both global and local value distributions. Extensive experiments are conducted on Shapley value estimation, value-based data removal/adding, mislabeled data detection, and incremental/decremental data valuation. The results showcase the effectiveness and efficiency of our proposed methodologies, affirming the significant potential of global and local value distributions in data valuation.
Read more5/29/2024
📊
0
EcoVal: An Efficient Data Valuation Framework for Machine Learning
Ayush K Tarun, Vikram S Chundawat, Murari Mandal, Hong Ming Tan, Bowei Chen, Mohan Kankanhalli
Quantifying the value of data within a machine learning workflow can play a pivotal role in making more strategic decisions in machine learning initiatives. The existing Shapley value based frameworks for data valuation in machine learning are computationally expensive as they require considerable amount of repeated training of the model to obtain the Shapley value. In this paper, we introduce an efficient data valuation framework EcoVal, to estimate the value of data for machine learning models in a fast and practical manner. Instead of directly working with individual data sample, we determine the value of a cluster of similar data points. This value is further propagated amongst all the member cluster points. We show that the overall value of the data can be determined by estimating the intrinsic and extrinsic value of each data. This is enabled by formulating the performance of a model as a textit{production function}, a concept which is popularly used to estimate the amount of output based on factors like labor and capital in a traditional free economic market. We provide a formal proof of our valuation technique and elucidate the principles and mechanisms that enable its accelerated performance. We demonstrate the real-world applicability of our method by showcasing its effectiveness for both in-distribution and out-of-sample data. This work addresses one of the core challenges of efficient data valuation at scale in machine learning models. The code is available at underline{https://github.com/respai-lab/ecoval}.
Read more7/10/2024

0
Is Data Valuation Learnable and Interpretable?
Ou Wu, Weiyao Zhu, Mengyang Li
Measuring the value of individual samples is critical for many data-driven tasks, e.g., the training of a deep learning model. Recent literature witnesses the substantial efforts in developing data valuation methods. The primary data valuation methodology is based on the Shapley value from game theory, and various methods are proposed along this path. {Even though Shapley value-based valuation has solid theoretical basis, it is entirely an experiment-based approach and no valuation model has been constructed so far.} In addition, current data valuation methods ignore the interpretability of the output values, despite an interptable data valuation method is of great helpful for applications such as data pricing. This study aims to answer an important question: is data valuation learnable and interpretable? A learned valuation model have several desirable merits such as fixed number of parameters and knowledge reusability. An intrepretable data valuation model can explain why a sample is valuable or invaluable. To this end, two new data value modeling frameworks are proposed, in which a multi-layer perception~(MLP) and a new regression tree are utilized as specific base models for model training and interpretability, respectively. Extensive experiments are conducted on benchmark datasets. {The experimental results provide a positive answer for the question.} Our study opens up a new technical path for the assessing of data values. Large data valuation models can be built across many different data-driven tasks, which can promote the widespread application of data valuation.
Read more6/6/2024
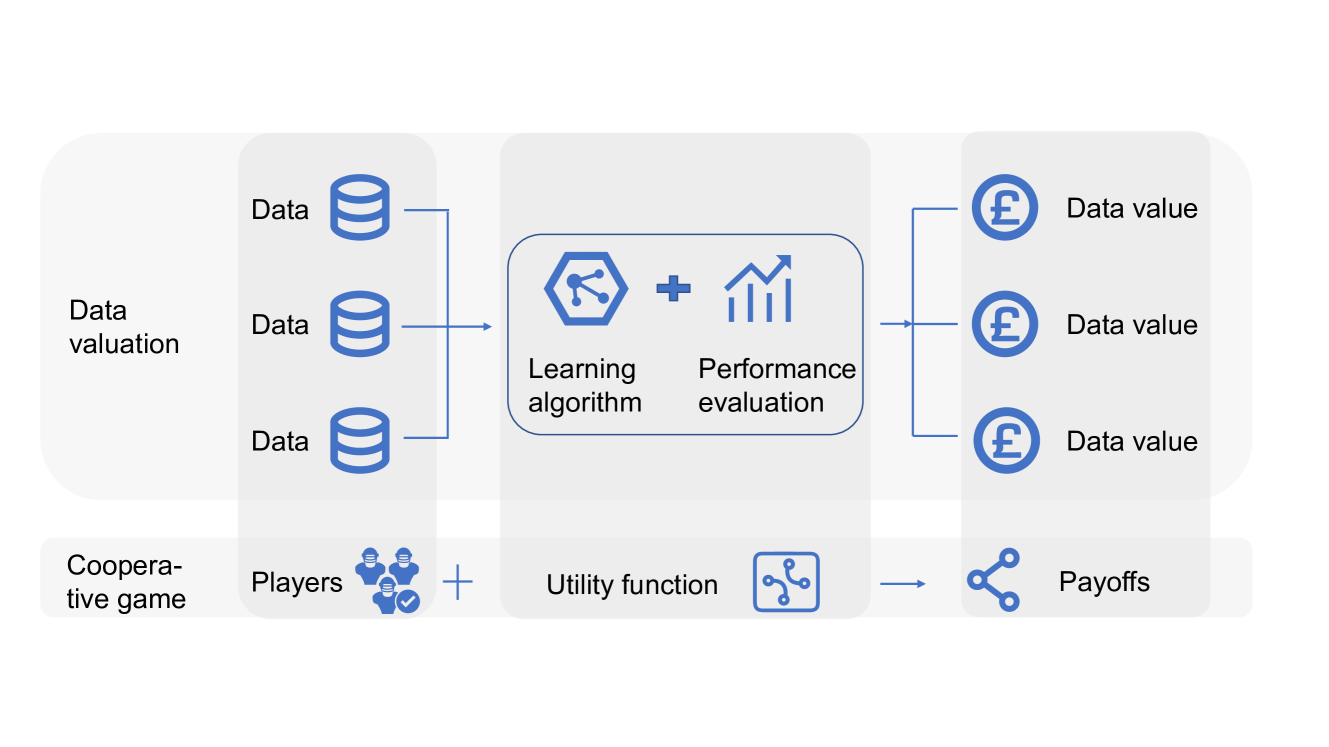
0
Uncertainty Quantification of Data Shapley via Statistical Inference
Mengmeng Wu, Zhihong Liu, Xiang Li, Ruoxi Jia, Xiangyu Chang
As data plays an increasingly pivotal role in decision-making, the emergence of data markets underscores the growing importance of data valuation. Within the machine learning landscape, Data Shapley stands out as a widely embraced method for data valuation. However, a limitation of Data Shapley is its assumption of a fixed dataset, contrasting with the dynamic nature of real-world applications where data constantly evolves and expands. This paper establishes the relationship between Data Shapley and infinite-order U-statistics and addresses this limitation by quantifying the uncertainty of Data Shapley with changes in data distribution from the perspective of U-statistics. We make statistical inferences on data valuation to obtain confidence intervals for the estimations. We construct two different algorithms to estimate this uncertainty and provide recommendations for their applicable situations. We also conduct a series of experiments on various datasets to verify asymptotic normality and propose a practical trading scenario enabled by this method.
Read more7/30/2024