Uncertainty Quantification of Data Shapley via Statistical Inference

0
Sign in to get full access
Overview
- Provides a statistical approach for quantifying the uncertainty in Data Shapley, a popular technique for measuring the importance of individual data points.
- Addresses the challenge of estimating the variance and confidence intervals of Data Shapley values, which is crucial for practical applications.
- Proposes a framework that leverages statistical inference to obtain robust uncertainty quantification of Data Shapley.
Plain English Explanation
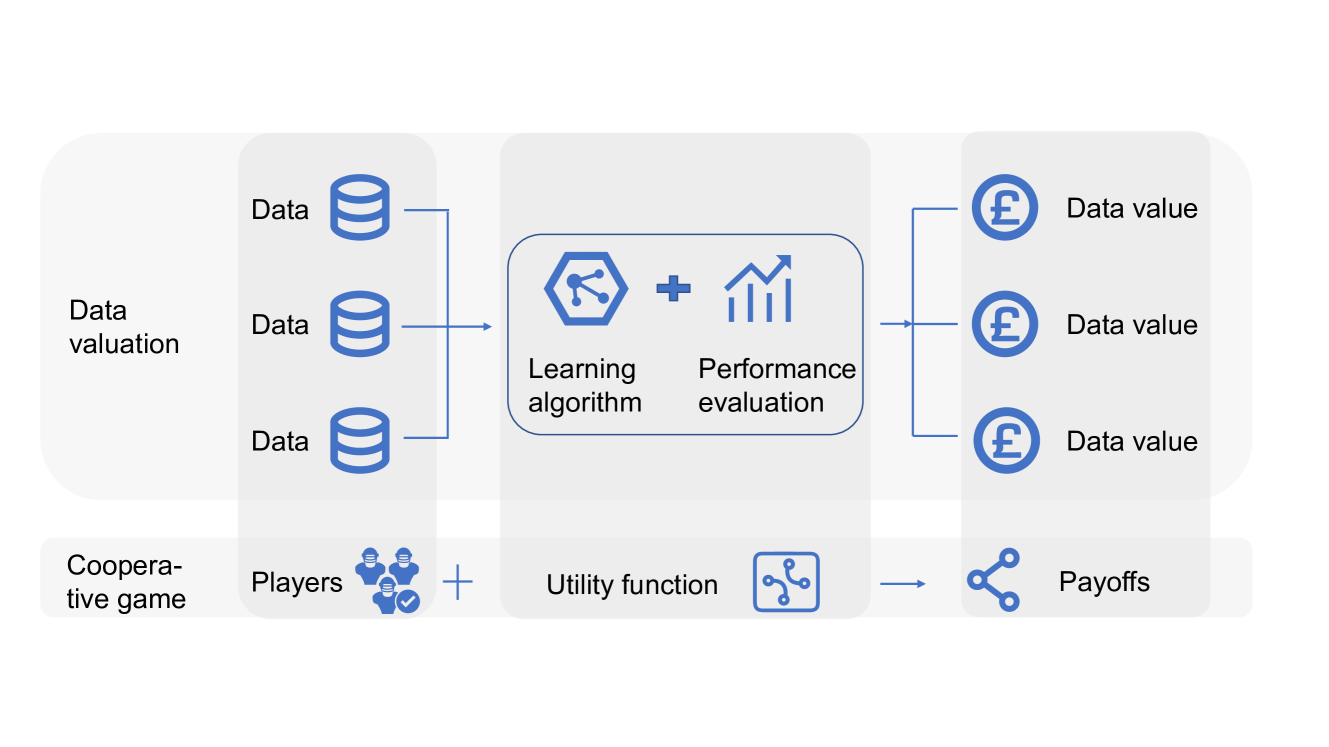
The paper presents a method to better understand the reliability of the Data Shapley technique, which is used to measure how much each data point contributes to the performance of a machine learning model. The Data Shapley approach assigns a numerical "importance" value to each data point, but it can be difficult to know how accurate or reliable these values are.
The authors of this paper introduce a statistical approach to quantify the uncertainty in the Data Shapley values. This allows users to not only get the importance score for each data point, but also understand how confident they can be in those scores. This is important because it helps users make more informed decisions when using Data Shapley for tasks like dataset selection or model debugging.
The key idea is to treat the Data Shapley values as statistical estimates and then use established statistical inference techniques to calculate the variance and confidence intervals around those estimates. This provides a principled way to assess the reliability of the Data Shapley scores, rather than just relying on the raw numbers.
Technical Explanation
The paper first reviews the Data Shapley approach, which estimates the importance of each data point by measuring its marginal contribution to the model's performance. However, the authors note that the original Data Shapley formulation does not provide a way to quantify the uncertainty in these importance scores.
To address this, the paper proposes a statistical framework for uncertainty quantification of Data Shapley. The core idea is to view the Data Shapley values as statistical estimates and then leverage techniques from statistical inference to obtain their variance and confidence intervals.
Specifically, the authors show that under certain assumptions, the Data Shapley values can be modeled as sample means of random variables. This allows them to apply standard statistical results, such as the central limit theorem, to derive analytical expressions for the variance and confidence intervals of the Data Shapley scores.
The paper also discusses practical considerations, such as dealing with heteroscedasticity (non-constant variance) in the underlying random variables. To handle this, the authors propose using heteroscedasticity-consistent standard errors to obtain robust uncertainty estimates.
Through experiments on several real-world datasets, the authors demonstrate that their statistical uncertainty quantification approach provides reliable and interpretable confidence intervals for Data Shapley values. This can help practitioners better understand the robustness of data importance scores and make more informed decisions based on them.
Critical Analysis
The paper makes a valuable contribution by addressing the important issue of uncertainty quantification in Data Shapley, a widely used technique for data valuation. By providing a principled statistical framework, the authors enable users to better assess the reliability of the Data Shapley scores, which is crucial for practical applications.
One limitation mentioned in the paper is the assumption of independent and identically distributed (i.i.d.) random variables underlying the Data Shapley values. In practice, data points in a dataset may exhibit complex dependencies, which could violate this assumption and affect the accuracy of the uncertainty estimates. Exploring extensions to handle more general data structures would be an interesting direction for future research.
Additionally, the paper focuses on obtaining analytical expressions for the variance and confidence intervals of Data Shapley values. While this provides interpretable uncertainty estimates, it may be computationally challenging for large-scale datasets. Investigating more efficient numerical approximation methods could expand the practical applicability of the proposed approach.
Overall, this paper takes an important step towards making Data Shapley a more robust and trustworthy tool for data-driven decision-making. The statistical uncertainty quantification framework introduced here can help practitioners better understand the reliability of data importance scores and make more informed choices, particularly in high-stakes applications.
Conclusion
This paper presents a statistical approach for quantifying the uncertainty in Data Shapley, a widely used technique for measuring the importance of individual data points. By treating the Data Shapley values as statistical estimates and leveraging techniques from statistical inference, the authors develop a principled framework to obtain reliable variance and confidence interval estimates.
The proposed method enables users to not only get the Data Shapley importance scores but also understand how confident they can be in those scores. This is a crucial capability for practical applications, where data-driven decisions often rely on the robustness and interpretability of the underlying data valuation measures.
The paper's contribution is an important step towards making Data Shapley a more trustworthy and transparent tool for data-driven decision-making. The statistical uncertainty quantification approach introduced here can help practitioners better assess the reliability of data importance scores and make more informed choices, particularly in high-stakes applications where the confidence in data valuation is paramount.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Uncertainty Quantification of Data Shapley via Statistical Inference
Mengmeng Wu, Zhihong Liu, Xiang Li, Ruoxi Jia, Xiangyu Chang
As data plays an increasingly pivotal role in decision-making, the emergence of data markets underscores the growing importance of data valuation. Within the machine learning landscape, Data Shapley stands out as a widely embraced method for data valuation. However, a limitation of Data Shapley is its assumption of a fixed dataset, contrasting with the dynamic nature of real-world applications where data constantly evolves and expands. This paper establishes the relationship between Data Shapley and infinite-order U-statistics and addresses this limitation by quantifying the uncertainty of Data Shapley with changes in data distribution from the perspective of U-statistics. We make statistical inferences on data valuation to obtain confidence intervals for the estimations. We construct two different algorithms to estimate this uncertainty and provide recommendations for their applicable situations. We also conduct a series of experiments on various datasets to verify asymptotic normality and propose a practical trading scenario enabled by this method.
Read more7/30/2024
🏷️
0
DU-Shapley: A Shapley Value Proxy for Efficient Dataset Valuation
Felipe Garrido-Lucero, Benjamin Heymann, Maxime Vono, Patrick Loiseau, Vianney Perchet
We consider the dataset valuation problem, that is, the problem of quantifying the incremental gain, to some relevant pre-defined utility of a machine learning task, of aggregating an individual dataset to others. The Shapley value is a natural tool to perform dataset valuation due to its formal axiomatic justification, which can be combined with Monte Carlo integration to overcome the computational tractability challenges. Such generic approximation methods, however, remain expensive in some cases. In this paper, we exploit the knowledge about the structure of the dataset valuation problem to devise more efficient Shapley value estimators. We propose a novel approximation, referred to as discrete uniform Shapley, which is expressed as an expectation under a discrete uniform distribution with support of reasonable size. We justify the relevancy of the proposed framework via asymptotic and non-asymptotic theoretical guarantees and illustrate its benefits via an extensive set of numerical experiments.
Read more6/19/2024
📊
0
Rethinking Data Shapley for Data Selection Tasks: Misleads and Merits
Jiachen T. Wang, Tianji Yang, James Zou, Yongchan Kwon, Ruoxi Jia
Data Shapley provides a principled approach to data valuation and plays a crucial role in data-centric machine learning (ML) research. Data selection is considered a standard application of Data Shapley. However, its data selection performance has shown to be inconsistent across settings in the literature. This study aims to deepen our understanding of this phenomenon. We introduce a hypothesis testing framework and show that Data Shapley's performance can be no better than random selection without specific constraints on utility functions. We identify a class of utility functions, monotonically transformed modular functions, within which Data Shapley optimally selects data. Based on this insight, we propose a heuristic for predicting Data Shapley's effectiveness in data selection tasks. Our experiments corroborate these findings, adding new insights into when Data Shapley may or may not succeed.
Read more5/8/2024
📊
0
Data Valuation by Leveraging Global and Local Statistical Information
Xiaoling Zhou, Ou Wu, Michael K. Ng, Hao Jiang
Data valuation has garnered increasing attention in recent years, given the critical role of high-quality data in various applications, particularly in machine learning tasks. There are diverse technical avenues to quantify the value of data within a corpus. While Shapley value-based methods are among the most widely used techniques in the literature due to their solid theoretical foundation, the accurate calculation of Shapley values is often intractable, leading to the proposal of numerous approximated calculation methods. Despite significant progress, nearly all existing methods overlook the utilization of distribution information of values within a data corpus. In this paper, we demonstrate that both global and local statistical information of value distributions hold significant potential for data valuation within the context of machine learning. Firstly, we explore the characteristics of both global and local value distributions across several simulated and real data corpora. Useful observations and clues are obtained. Secondly, we propose a new data valuation method that estimates Shapley values by incorporating the explored distribution characteristics into an existing method, AME. Thirdly, we present a new path to address the dynamic data valuation problem by formulating an optimization problem that integrates information of both global and local value distributions. Extensive experiments are conducted on Shapley value estimation, value-based data removal/adding, mislabeled data detection, and incremental/decremental data valuation. The results showcase the effectiveness and efficiency of our proposed methodologies, affirming the significant potential of global and local value distributions in data valuation.
Read more5/29/2024