DatAasee -- A Metadata-Lake as Metadata Catalog for a Virtual Data-Lake

0

Sign in to get full access
Overview
- DatAasee is a metadata-lake that acts as a metadata catalog for a virtual data-lake
- It provides a unified view of data sources across an organization
- Key features include automatic metadata extraction, data lineage tracking, and a user-friendly search interface
Plain English Explanation
DatAasee is a system that helps organizations better manage and access their data. It works as a central catalog for tracking metadata - information about the data itself, such as what it contains, where it's stored, and how it's related to other data.
By pulling in metadata from various data sources across an organization, DatAasee provides a unified view of all the data assets. This makes it easier for users to discover, understand, and work with the data they need.
Some key features of DatAasee include:
- Automatic Metadata Extraction: It can automatically scan and extract metadata from different types of data sources, without manual effort.
- Data Lineage Tracking: DatAasee keeps track of how data flows and is transformed between systems, providing visibility into data provenance.
- Intuitive Search Interface: Users can easily search and browse the available data using a user-friendly web interface, instead of having to navigate complex storage systems directly.
By centralizing metadata management, DatAasee aims to make an organization's data more discoverable and usable, unlocking its full value.
Technical Explanation
DatAasee is designed as a metadata-lake - a centralized repository for collecting and managing metadata from various data sources across an organization. It serves as a metadata catalog for a virtual data-lake, providing a unified view of an organization's distributed data assets.
The key components of the DatAasee architecture include:
- Metadata Extraction: DatAasee employs connectors to automatically scan and extract metadata from different types of data sources, including databases, file stores, and streaming platforms.
- Metadata Storage: The extracted metadata is stored in a scalable, queryable repository, allowing for efficient search and retrieval.
- Data Lineage: DatAasee tracks the lineage of data, capturing how it flows and is transformed between systems. This provides visibility into data provenance.
- Search and Browsing: DatAasee offers a user-friendly web interface for searching, browsing, and understanding the available data assets.
By centrally managing metadata, DatAasee aims to make an organization's data more discoverable and usable, enabling data-driven decision-making and fostering collaboration across teams.
Critical Analysis
The paper presents a compelling case for the need to better manage metadata and data discoverability within organizations. DatAasee's ability to automatically extract and centralize metadata from diverse sources is a valuable feature, as it can reduce the manual effort required to maintain data catalogs.
However, the paper does not delve into potential challenges or limitations of the DatAasee approach. For example, it does not address how the system handles data privacy and security concerns when aggregating metadata from various sources. Additionally, the paper does not discuss the scalability of the metadata-lake architecture as the volume and variety of data grows over time.
Further research could explore these areas, as well as investigate the practical real-world deployment and adoption challenges of a system like DatAasee. Evaluating the system's performance and user experience in comparison to alternative metadata management solutions would also provide helpful insights.
Conclusion
DatAasee is a promising approach to addressing the challenge of data discoverability and usability within organizations. By centralizing metadata management in a metadata-lake, the system aims to provide a unified view of an organization's distributed data assets, enabling more effective data-driven decision-making and collaboration.
The key features of automatic metadata extraction, data lineage tracking, and user-friendly search and browsing make DatAasee a compelling solution. However, further research is needed to explore the system's scalability, security, and real-world deployment challenges to fully assess its potential impact on data management practices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DatAasee -- A Metadata-Lake as Metadata Catalog for a Virtual Data-Lake
Christian Himpe
Metadata management for distributed data sources is a long-standing but ever-growing problem. To counter this challenge in a research-data and library-oriented setting, this work constructs a data architecture, derived from the data-lake: the metadata-lake. A proof-of-concept implementation of this proposed metadata system is presented and evaluated as well.
Read more9/10/2024

0
Dataversifying Natural Sciences: Pioneering a Data Lake Architecture for Curated Data-Centric Experiments in Life & Earth Sciences
Genoveva Vargas-Solar (LIRIS), J'er^ome Darmont (ERIC), Alejandro Adorjan (LIRIS), Javier A. Espinosa-Oviedo (LIRIS), Carmem Hara (ERIC), Sabine Loudcher (ERIC), Regina Motz (DIMAP), Martin Musicante (DIMAP), Jos'e-Luis Zechinelli-Martini
This vision paper introduces a pioneering data lake architecture designed to meet Life & Earth sciences' burgeoning data management needs. As the data landscape evolves, the imperative to navigate and maximize scientific opportunities has never been greater. Our vision paper outlines a strategic approach to unify and integrate diverse datasets, aiming to cultivate a collaborative space conducive to scientific discovery.The core of the design and construction of a data lake is the development of formal and semi-automatic tools, enabling the meticulous curation of quantitative and qualitative data from experiments. Our unique ''research-in-the-loop'' methodology ensures that scientists across various disciplines are integrally involved in the curation process, combining automated, mathematical, and manual tasks to address complex problems, from seismic detection to biodiversity studies. By fostering reproducibility and applicability of research, our approach enhances the integrity and impact of scientific experiments. This initiative is set to improve data management practices, strengthening the capacity of Life & Earth sciences to solve some of our time's most critical environmental and biological challenges.
Read more4/1/2024
📊
0
Retrieve, Merge, Predict: Augmenting Tables with Data Lakes
Riccardo Cappuzzo (SODA Team - Inria Saclay), Aimee Coelho (Dataiku), Felix Lefebvre (SODA Team - Inria Saclay), Paolo Papotti (EURECOM), Gael Varoquaux (SODA Team - Inria Saclay)
We present an in-depth analysis of data discovery in data lakes, focusing on table augmentation for given machine learning tasks. We analyze alternative methods used in the three main steps: retrieving joinable tables, merging information, and predicting with the resultant table. As data lakes, the paper uses YADL (Yet Another Data Lake) -- a novel dataset we developed as a tool for benchmarking this data discovery task -- and Open Data US, a well-referenced real data lake. Through systematic exploration on both lakes, our study outlines the importance of accurately retrieving join candidates and the efficiency of simple merging methods. We report new insights on the benefits of existing solutions and on their limitations, aiming at guiding future research in this space.
Read more5/28/2024
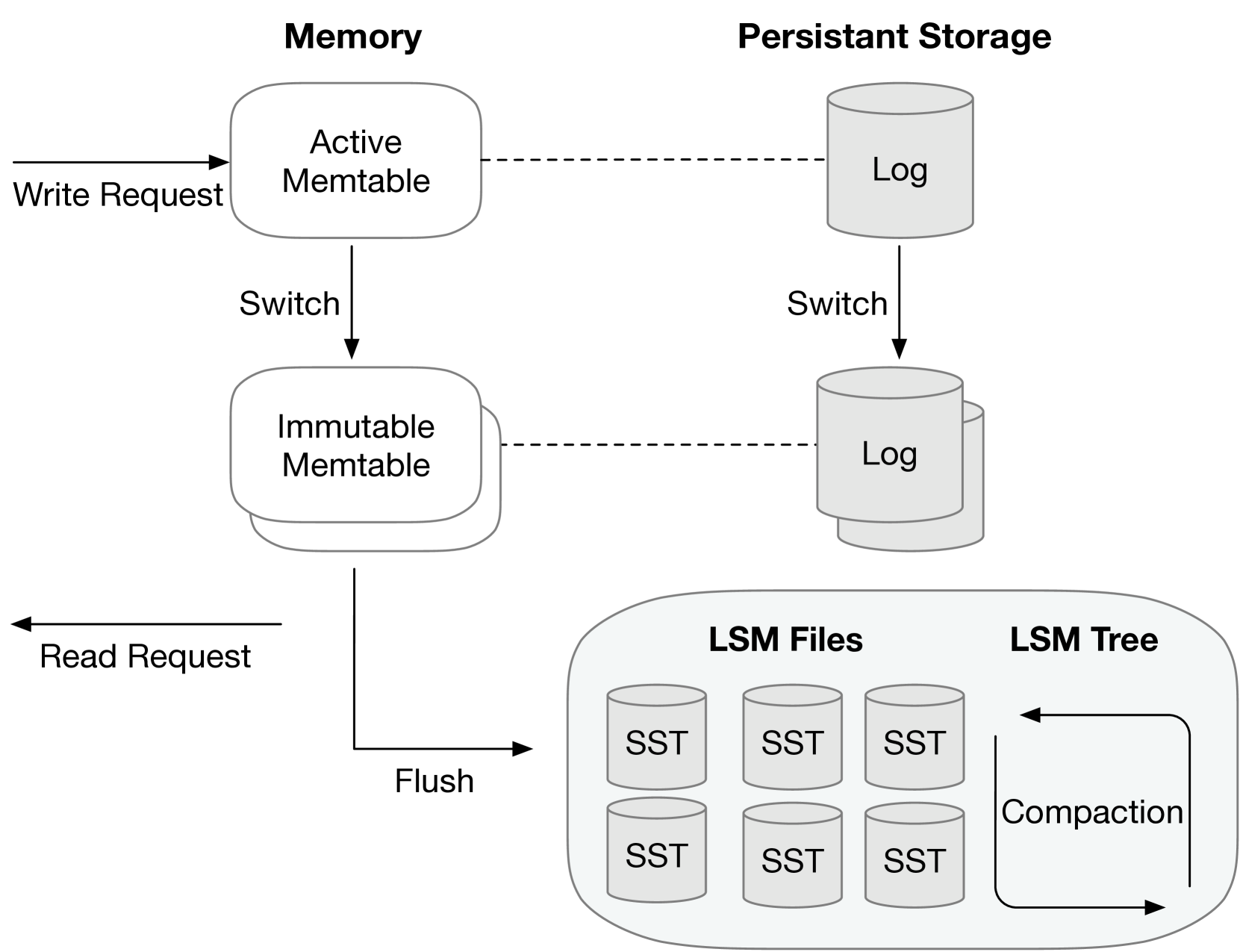
0
MetaHive: A Cache-Optimized Metadata Management for Heterogeneous Key-Value Stores
Alireza Heidari, Amirhossein Ahmadi, Zefeng Zhi, Wei Zhang
Cloud key-value (KV) stores provide businesses with a cost-effective and adaptive alternative to traditional on-premise data management solutions. KV stores frequently consist of heterogeneous clusters, characterized by varying hardware specifications of the deployment nodes, with each node potentially running a distinct version of the KV store software. This heterogeneity is accompanied by the diverse metadata that they need to manage. In this study, we introduce MetaHive, a cache-optimized approach to managing metadata in heterogeneous KV store clusters. MetaHive disaggregates the original data from its associated metadata to promote independence between them, while maintaining their interconnection during usage. This makes the metadata opaque from the downstream processes and the other KV stores in the cluster. MetaHive also ensures that the KV and metadata entries are stored in the vicinity of each other in memory and storage. This allows MetaHive to optimally utilize the caching mechanism without extra storage read overhead for metadata retrieval. We deploy MetaHive to ensure data integrity in RocksDB and demonstrate its rapid data validation with minimal effect on performance.
Read more7/30/2024