MetaHive: A Cache-Optimized Metadata Management for Heterogeneous Key-Value Stores

0
Sign in to get full access
Overview
- MetaHive is a cache-optimized metadata management system for heterogeneous key-value stores.
- It aims to improve performance and reduce storage costs for applications that rely on metadata-heavy workloads.
- The system leverages caching techniques and a hierarchical metadata structure to efficiently manage metadata across different key-value stores.
Plain English Explanation
MetaHive: A Cache-Optimized Metadata Management for Heterogeneous Key-Value Stores is a research paper that presents a new approach to managing metadata in distributed data storage systems. Metadata is information about the data itself, such as file names, timestamps, and other attributes. Efficiently managing and accessing this metadata is crucial for many applications, particularly those that work with large volumes of data.
The key idea behind MetaHive is to use a cache-optimized approach to metadata management. This means that the system is designed to take advantage of fast, in-memory caching to speed up access to frequently used metadata. The system also uses a hierarchical structure to organize the metadata, which allows it to efficiently manage metadata across different types of key-value stores, such as Redis, Cassandra, and Couchbase.
By using these techniques, MetaHive aims to improve the performance and reduce the storage costs of applications that rely on metadata-heavy workloads. This could be particularly useful for applications such as content management systems, enterprise file management tools, and big data analytics platforms, which often need to work with large volumes of metadata.
Technical Explanation
MetaHive: A Cache-Optimized Metadata Management for Heterogeneous Key-Value Stores presents a novel system for managing metadata in distributed key-value stores. The key-value store is a common data storage architecture used in many modern applications, but managing the metadata associated with the data stored in these systems can be challenging.
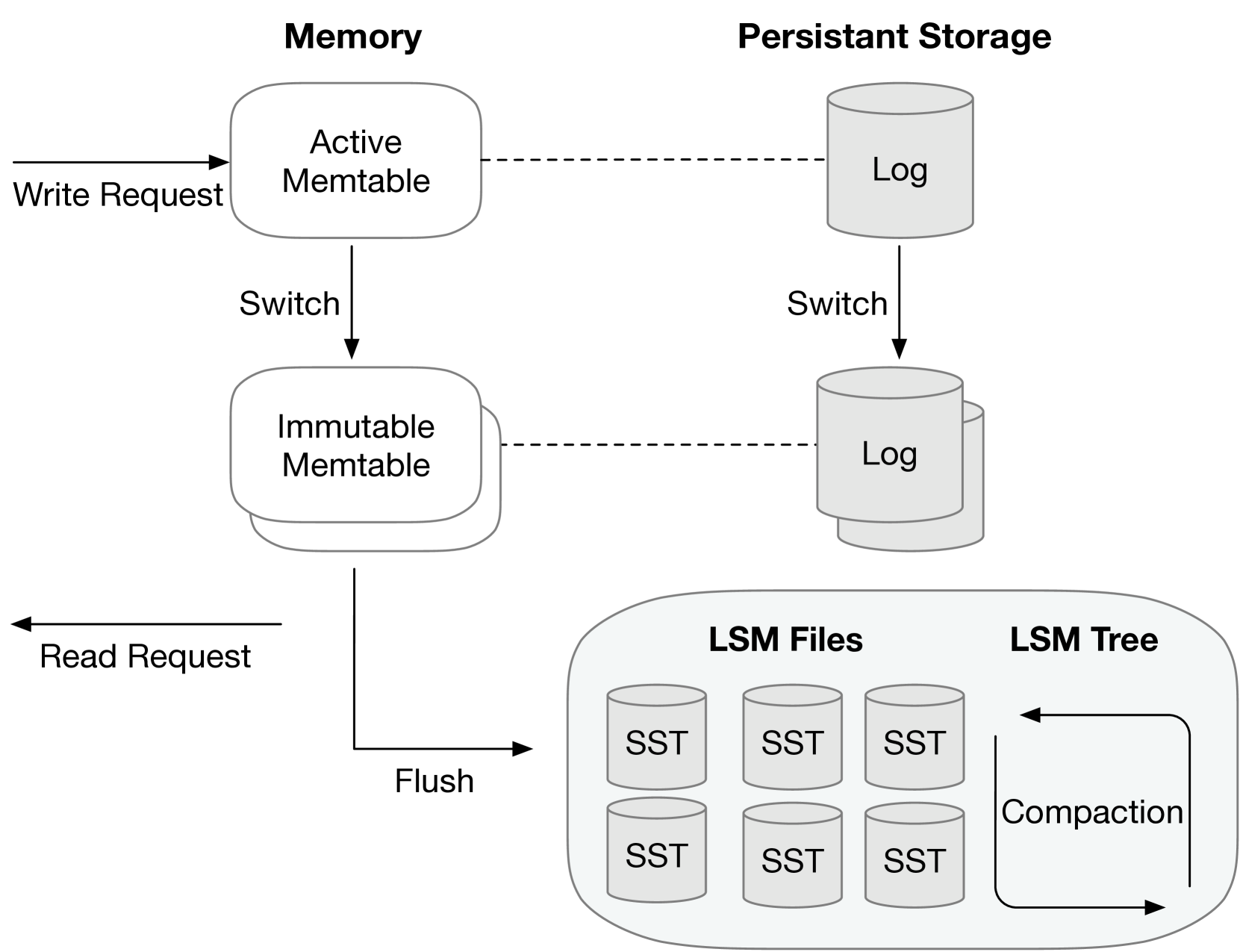
The core idea behind MetaHive is to use a cache-optimized approach to metadata management. This involves a hierarchical metadata structure that can efficiently manage metadata across different types of key-value stores, such as Redis, Cassandra, and Couchbase. The system leverages in-memory caching to improve the performance of frequently accessed metadata, and it also includes techniques for compacting and compressing the metadata to reduce storage costs.
The paper describes the architecture of MetaHive, including its key components: the metadata cache, the metadata store, and the metadata compaction and compression modules. It also presents the results of experiments that demonstrate the performance and storage benefits of the MetaHive approach compared to traditional metadata management techniques.
Critical Analysis
The MetaHive paper presents a well-designed and thorough system for addressing the challenges of metadata management in distributed key-value stores. The authors have clearly put a lot of thought into the design and implementation of the system, and the experimental results suggest that it can provide significant performance and storage benefits.
However, the paper does not address some potential limitations of the approach. For example, it is not clear how the system would scale to handle extremely large volumes of metadata or how it would handle metadata that is constantly changing. Additionally, the paper does not discuss how the system would handle failures or errors in the underlying key-value stores, which could be an important consideration for real-world deployments.
Overall, the MetaHive system appears to be a promising approach to metadata management, but further research and development may be needed to address these potential limitations and ensure that the system can be deployed effectively in production environments.
Conclusion
MetaHive: A Cache-Optimized Metadata Management for Heterogeneous Key-Value Stores presents a novel system for managing metadata in distributed key-value stores. By using a cache-optimized, hierarchical metadata structure, the system aims to improve the performance and reduce the storage costs of applications that rely on metadata-heavy workloads.
The technical details and experimental results presented in the paper suggest that the MetaHive approach could be a valuable tool for a wide range of applications, from content management systems to big data analytics platforms. While the system may have some limitations that require further research and development, the core ideas behind MetaHive represent an important contribution to the field of distributed data management.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MetaHive: A Cache-Optimized Metadata Management for Heterogeneous Key-Value Stores
Alireza Heidari, Amirhossein Ahmadi, Zefeng Zhi, Wei Zhang
Cloud key-value (KV) stores provide businesses with a cost-effective and adaptive alternative to traditional on-premise data management solutions. KV stores frequently consist of heterogeneous clusters, characterized by varying hardware specifications of the deployment nodes, with each node potentially running a distinct version of the KV store software. This heterogeneity is accompanied by the diverse metadata that they need to manage. In this study, we introduce MetaHive, a cache-optimized approach to managing metadata in heterogeneous KV store clusters. MetaHive disaggregates the original data from its associated metadata to promote independence between them, while maintaining their interconnection during usage. This makes the metadata opaque from the downstream processes and the other KV stores in the cluster. MetaHive also ensures that the KV and metadata entries are stored in the vicinity of each other in memory and storage. This allows MetaHive to optimally utilize the caching mechanism without extra storage read overhead for metadata retrieval. We deploy MetaHive to ensure data integrity in RocksDB and demonstrate its rapid data validation with minimal effect on performance.
Read more7/30/2024

0
DatAasee -- A Metadata-Lake as Metadata Catalog for a Virtual Data-Lake
Christian Himpe
Metadata management for distributed data sources is a long-standing but ever-growing problem. To counter this challenge in a research-data and library-oriented setting, this work constructs a data architecture, derived from the data-lake: the metadata-lake. A proof-of-concept implementation of this proposed metadata system is presented and evaluated as well.
Read more9/10/2024
0
Data Caching for Enterprise-Grade Petabyte-Scale OLAP
Chunxu Tang (James), Bin Fan (James), Jing Zhao (James), Chen Liang (James), Yi Wang (James), Beinan Wang (James), Ziyue Qiu (James), Lu Qiu (James), Bowen Ding (James), Shouzhuo Sun (James), Saiguang Che (James), Jiaming Mai (James), Shouwei Chen (James), Yu Zhu (James), Jianjian Xie (James), Yutian (James), Sun, Yao Li, Yangjun Zhang, Ke Wang, Mingmin Chen
With the exponential growth of data and evolving use cases, petabyte-scale OLAP data platforms are increasingly adopting a model that decouples compute from storage. This shift, evident in organizations like Uber and Meta, introduces operational challenges including massive, read-heavy I/O traffic with potential throttling, as well as skewed and fragmented data access patterns. Addressing these challenges, this paper introduces the Alluxio local (edge) cache, a highly effective architectural optimization tailored for such environments. This embeddable cache, optimized for petabyte-scale data analytics, leverages local SSD resources to alleviate network I/O and API call pressures, significantly improving data transfer efficiency. Integrated with OLAP systems like Presto and storage services like HDFS, the Alluxio local cache has demonstrated its effectiveness in handling large-scale, enterprise-grade workloads over three years of deployment at Uber and Meta. We share insights and operational experiences in implementing these optimizations, providing valuable perspectives on managing modern, massive-scale OLAP workloads.
Read more6/11/2024
📊
0
Humboldt: Metadata-Driven Extensible Data Discovery
Alex Bauerle, c{C}au{g}atay Demiralp, Michael Stonebraker
Data discovery is crucial for data management and analysis and can benefit from better utilization of metadata. For example, users may want to search data using queries like ``find the tables created by Alex and endorsed by Mike that contain sales numbers.'' They may also want to see how the data they view relates to other data, its lineage, or the quality and compliance of its upstream datasets, all metadata. Yet, effectively surfacing metadata through interactive user interfaces (UIs) to augment data discovery poses challenges. Constantly revamping UIs with each update to metadata sources (or providers) consumes significant development resources and lacks scalability and extensibility. In response, we introduce Humboldt, a new framework enabling interactive data systems to effectively leverage metadata for data discovery and rapidly evolve their UIs to support metadata changes. Humboldt decouples metadata sources from the implementation of data discovery UIs that support search and dataset visualization using metadata fields. It automatically generates interactive data discovery interfaces from declarative specifications, avoiding costly metadata-specific (re)implementations.
Read more8/22/2024