DataNarrative: Automated Data-Driven Storytelling with Visualizations and Texts

0
⛏️
Sign in to get full access
Overview
- Provides instructions for the EMNLP 2020 proceedings
- Covers key details like credits, introduction, and electronically-available resources
Plain English Explanation
This paper outlines the instructions for authors submitting papers to the Empirical Methods in Natural Language Processing (EMNLP) 2020 conference proceedings. It covers important information like giving credit to the right people, introducing the context of the proceedings, and highlighting resources that will be made available electronically.
The credits section acknowledges the individuals and organizations involved in putting together the EMNLP 2020 proceedings. The introduction provides background on the conference and the purpose of the proceedings. The electronically-available resources section lists the various materials that will be made accessible online for authors and attendees.
Overall, this paper lays out the key administrative and logistical details that authors need to know when submitting their work to be included in the official EMNLP 2020 proceedings.
Technical Explanation
The paper begins with a credits section that acknowledges the contributions of various individuals and groups involved in organizing the EMNLP 2020 conference and compiling the proceedings. This includes the EMNLP 2020 Program Chairs, the EMNLP 2020 General Chairs, the Association for Computational Linguistics (ACL), and the International Committee on Computational Linguistics (ICCL).
The introduction section provides context on the EMNLP conference series and the purpose of the proceedings. It notes that EMNLP is a leading conference in the field of natural language processing, and the proceedings will contain the accepted papers presented at the 2020 event.
The electronically-available resources section details the various materials that will be made accessible online for authors and attendees. This includes templates, style files, and other supporting documents needed for paper submissions. It also mentions that the final proceedings will be available electronically through the ACL Anthology.
Critical Analysis
The instructions provided in this paper cover the key administrative and logistical details that authors need to know when submitting their work to the EMNLP 2020 proceedings. However, the paper does not go into significant depth on the technical or content-related requirements for the papers themselves.
While the information on electronically-available resources is useful, the paper could be improved by providing more comprehensive guidance on formatting, structure, length limits, and other technical specifications for the paper submissions. Additional details on the review and selection process, as well as any formatting or presentation requirements for accepted papers, would also be valuable.
Furthermore, the paper does not address any potential issues or limitations that authors may face when preparing their submissions. Acknowledging and providing advice on common challenges or pitfalls could make the instructions more helpful and actionable for authors.
Conclusion
This paper outlines the key administrative details for the EMNLP 2020 proceedings, including credits, introduction, and resources. It provides a solid foundation for authors on the logistics of submitting their work, but could be strengthened by incorporating more comprehensive technical guidance and addressing potential challenges. Overall, the instructions serve as an important reference point for ensuring a successful EMNLP 2020 conference and proceedings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
0
DataNarrative: Automated Data-Driven Storytelling with Visualizations and Texts
Mohammed Saidul Islam, Md Tahmid Rahman Laskar, Md Rizwan Parvez, Enamul Hoque, Shafiq Joty
Data-driven storytelling is a powerful method for conveying insights by combining narrative techniques with visualizations and text. These stories integrate visual aids, such as highlighted bars and lines in charts, along with textual annotations explaining insights. However, creating such stories requires a deep understanding of the data and meticulous narrative planning, often necessitating human intervention, which can be time-consuming and mentally taxing. While Large Language Models (LLMs) excel in various NLP tasks, their ability to generate coherent and comprehensive data stories remains underexplored. In this work, we introduce a novel task for data story generation and a benchmark containing 1,449 stories from diverse sources. To address the challenges of crafting coherent data stories, we propose a multiagent framework employing two LLM agents designed to replicate the human storytelling process: one for understanding and describing the data (Reflection), generating the outline, and narration, and another for verification at each intermediary step. While our agentic framework generally outperforms non-agentic counterparts in both model-based and human evaluations, the results also reveal unique challenges in data story generation.
Read more8/15/2024

0
From Data to Story: Towards Automatic Animated Data Video Creation with LLM-based Multi-Agent Systems
Leixian Shen, Haotian Li, Yun Wang, Huamin Qu
Creating data stories from raw data is challenging due to humans' limited attention spans and the need for specialized skills. Recent advancements in large language models (LLMs) offer great opportunities to develop systems with autonomous agents to streamline the data storytelling workflow. Though multi-agent systems have benefits such as fully realizing LLM potentials with decomposed tasks for individual agents, designing such systems also faces challenges in task decomposition, performance optimization for sub-tasks, and workflow design. To better understand these issues, we develop Data Director, an LLM-based multi-agent system designed to automate the creation of animated data videos, a representative genre of data stories. Data Director interprets raw data, breaks down tasks, designs agent roles to make informed decisions automatically, and seamlessly integrates diverse components of data videos. A case study demonstrates Data Director's effectiveness in generating data videos. Throughout development, we have derived lessons learned from addressing challenges, guiding further advancements in autonomous agents for data storytelling. We also shed light on future directions for global optimization, human-in-the-loop design, and the application of advanced multi-modal LLMs.
Read more8/9/2024
0
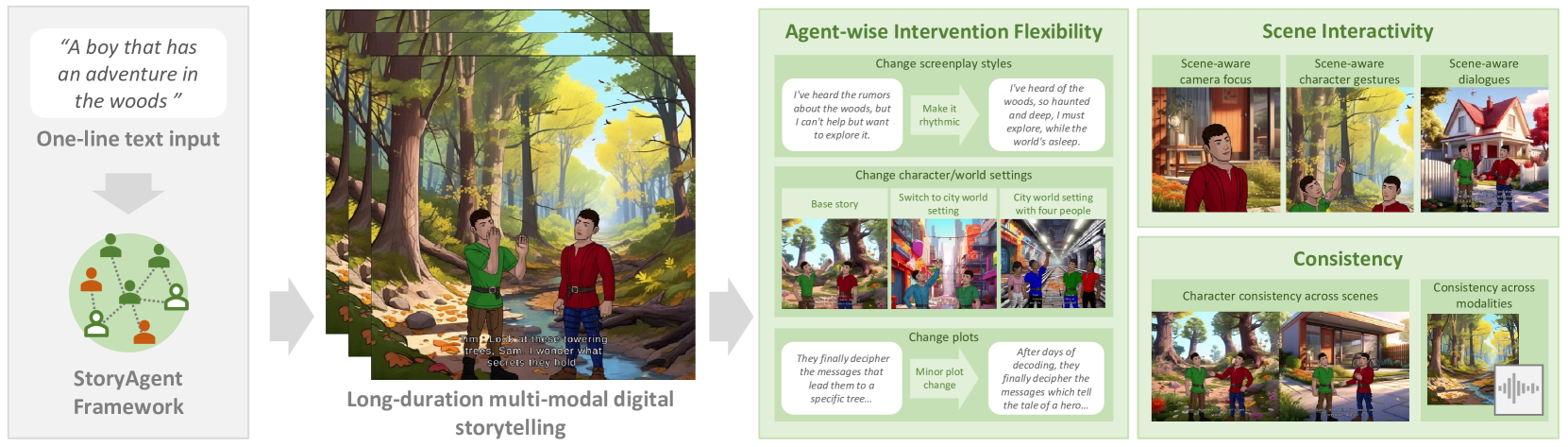
From Words to Worlds: Transforming One-line Prompt into Immersive Multi-modal Digital Stories with Communicative LLM Agent
Samuel S. Sohn, Danrui Li, Sen Zhang, Che-Jui Chang, Mubbasir Kapadia
Digital storytelling, essential in entertainment, education, and marketing, faces challenges in production scalability and flexibility. The StoryAgent framework, introduced in this paper, utilizes Large Language Models and generative tools to automate and refine digital storytelling. Employing a top-down story drafting and bottom-up asset generation approach, StoryAgent tackles key issues such as manual intervention, interactive scene orchestration, and narrative consistency. This framework enables efficient production of interactive and consistent narratives across multiple modalities, democratizing content creation and enhancing engagement. Our results demonstrate the framework's capability to produce coherent digital stories without reference videos, marking a significant advancement in automated digital storytelling.
Read more6/24/2024
💬
0
Improving Visual Storytelling with Multimodal Large Language Models
Xiaochuan Lin, Xiangyong Chen
Visual storytelling is an emerging field that combines images and narratives to create engaging and contextually rich stories. Despite its potential, generating coherent and emotionally resonant visual stories remains challenging due to the complexity of aligning visual and textual information. This paper presents a novel approach leveraging large language models (LLMs) and large vision-language models (LVLMs) combined with instruction tuning to address these challenges. We introduce a new dataset comprising diverse visual stories, annotated with detailed captions and multimodal elements. Our method employs a combination of supervised and reinforcement learning to fine-tune the model, enhancing its narrative generation capabilities. Quantitative evaluations using GPT-4 and qualitative human assessments demonstrate that our approach significantly outperforms existing models, achieving higher scores in narrative coherence, relevance, emotional depth, and overall quality. The results underscore the effectiveness of instruction tuning and the potential of LLMs/LVLMs in advancing visual storytelling.
Read more7/4/2024