Dataset Condensation Driven Machine Unlearning
2402.00195
0
0
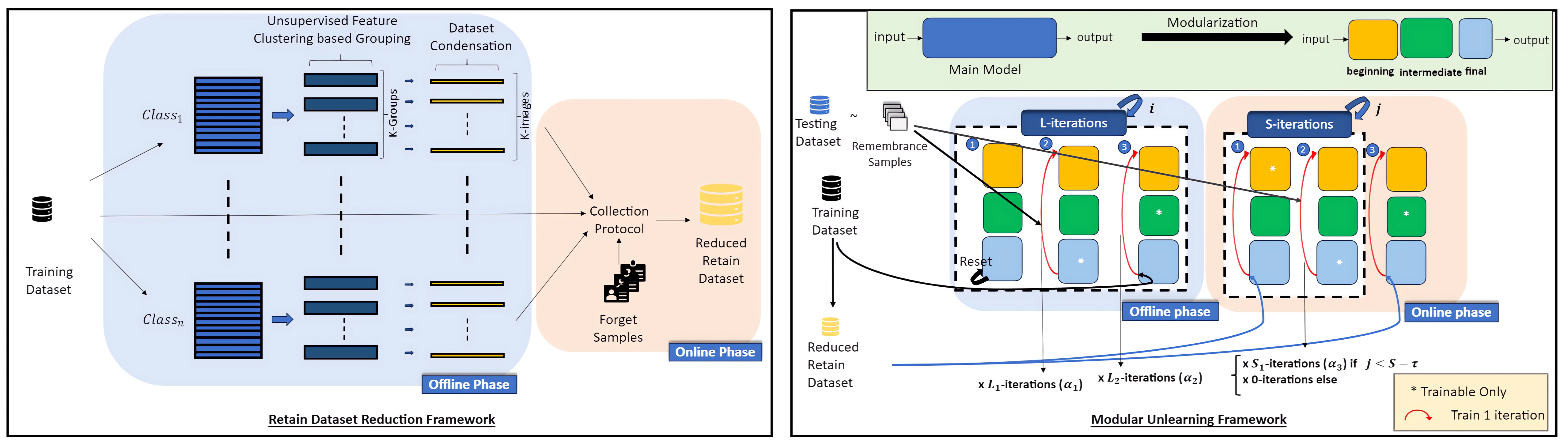
Abstract
The current trend in data regulation requirements and privacy-preserving machine learning has emphasized the importance of machine unlearning. The naive approach to unlearning training data by retraining over the complement of the forget samples is susceptible to computational challenges. These challenges have been effectively addressed through a collection of techniques falling under the umbrella of machine unlearning. However, there still exists a lack of sufficiency in handling persistent computational challenges in harmony with the utility and privacy of unlearned model. We attribute this to the lack of work on improving the computational complexity of approximate unlearning from the perspective of the training dataset. In this paper, we aim to fill this gap by introducing dataset condensation as an essential component of machine unlearning in the context of image classification. To achieve this goal, we propose new dataset condensation techniques and an innovative unlearning scheme that strikes a balance between machine unlearning privacy, utility, and efficiency. Furthermore, we present a novel and effective approach to instrumenting machine unlearning and propose its application in defending against membership inference and model inversion attacks. Additionally, we explore a new application of our approach, which involves removing data from `condensed model', which can be employed to quickly train any arbitrary model without being influenced by unlearning samples. The corresponding code is available at href{https://github.com/algebraicdianuj/DC_U}{URL}.
Create account to get full access
Overview
- Presents a method for "unlearning" machine learning models by condensing the training dataset
- Focuses on image classification tasks and neural networks
- Proposes a technique called "Dataset Condensation Driven Machine Unlearning" (DCDMU) to reduce model size and memory footprint
Plain English Explanation
The paper introduces a technique called "Dataset Condensation Driven Machine Unlearning" (DCDMU) that allows machine learning models to "unlearn" information from their training data. This is particularly useful when you want to remove sensitive or outdated information from a model without having to retrain it from scratch.
The key idea behind DCDMU is to generate a much smaller "condensed" dataset that captures the essential information needed to train the model. By training the model on this condensed dataset, you can effectively reduce the model's size and memory footprint while also removing the unwanted information. This can be especially helpful in scenarios where you need to comply with data privacy regulations or update models with new information.
The paper focuses on image classification tasks and neural networks, but the underlying principles could potentially be applied to other machine learning domains as well. The authors demonstrate the effectiveness of DCDMU through experiments on various image datasets and show that it can achieve significant model size reduction without compromising performance.
Technical Explanation
The paper introduces a technique called "Dataset Condensation Driven Machine Unlearning" (DCDMU) to reduce the size and memory footprint of machine learning models, particularly neural networks used for image classification tasks.
The core idea behind DCDMU is to generate a much smaller "condensed" dataset that captures the essential information needed to train the model. This condensed dataset is then used to train the model, effectively "unlearning" the original, larger dataset.
The authors propose a two-stage process for DCDMU:
-
Dataset Condensation: The original training dataset is condensed into a smaller set of synthetic data points that can still effectively train the model. This is achieved through an optimization process that aims to maximize the similarity between the model trained on the original dataset and the model trained on the condensed dataset.
-
Model Unlearning: The condensed dataset is used to train a new model, which effectively removes the unwanted information from the original dataset while maintaining the model's performance on the target task.
The authors evaluate DCDMU on various image classification tasks and datasets, including CIFAR-10, CIFAR-100, and ImageNet. They compare the performance and model size of the unlearned models to the original models, demonstrating significant reductions in model size without compromising classification accuracy.
Critical Analysis
The paper presents an interesting and potentially useful technique for "unlearning" machine learning models, but there are a few potential limitations and areas for further research:
-
Generalization to other domains: The paper focuses on image classification tasks and neural networks, but it's unclear if the DCDMU approach would be as effective for other types of machine learning models or tasks, such as natural language processing or tabular data.
-
Data privacy and security: While the paper mentions the potential benefits of DCDMU for data privacy, the authors don't provide a thorough analysis of the privacy-preserving properties of the technique. Further research is needed to understand the privacy implications and potential vulnerabilities of DCDMU.
-
Interpretability and explainability: The paper doesn't address the interpretability or explainability of the unlearned models. It's unclear how the DCDMU process affects the interpretability of the model's decision-making, which could be an important consideration in certain applications.
-
Computational complexity: The dataset condensation and model unlearning processes described in the paper could be computationally expensive, particularly for large-scale datasets and models. The efficiency and scalability of the DCDMU approach should be further investigated.
Despite these limitations, the DCDMU technique presented in this paper offers a promising approach for reducing the size and memory footprint of machine learning models while potentially addressing data privacy concerns. Further research and development in this area could lead to valuable advancements in the field of machine unlearning.
Conclusion
The paper introduces a novel technique called "Dataset Condensation Driven Machine Unlearning" (DCDMU) that allows machine learning models to "unlearn" information from their training data. By generating a much smaller "condensed" dataset and training the model on this condensed data, DCDMU can effectively reduce the model's size and memory footprint while removing unwanted information.
The authors demonstrate the effectiveness of DCDMU through experiments on various image classification tasks and datasets, showing significant reductions in model size without compromising performance. While the paper focuses on neural networks and image classification, the underlying principles of DCDMU could potentially be applied to other machine learning domains as well.
The DCDMU technique presented in this paper offers a promising approach for addressing data privacy concerns and model maintenance challenges in machine learning. Further research and development in this area could lead to valuable advancements in the field of machine unlearning, with potential applications in a wide range of industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
Machine Unlearning: A Comprehensive Survey
Weiqi Wang, Zhiyi Tian, Shui Yu
0
0
As the right to be forgotten has been legislated worldwide, many studies attempt to design unlearning mechanisms to protect users' privacy when they want to leave machine learning service platforms. Specifically, machine unlearning is to make a trained model to remove the contribution of an erased subset of the training dataset. This survey aims to systematically classify a wide range of machine unlearning and discuss their differences, connections and open problems. We categorize current unlearning methods into four scenarios: centralized unlearning, distributed and irregular data unlearning, unlearning verification, and privacy and security issues in unlearning. Since centralized unlearning is the primary domain, we use two parts to introduce: firstly, we classify centralized unlearning into exact unlearning and approximate unlearning; secondly, we offer a detailed introduction to the techniques of these methods. Besides the centralized unlearning, we notice some studies about distributed and irregular data unlearning and introduce federated unlearning and graph unlearning as the two representative directions. After introducing unlearning methods, we review studies about unlearning verification. Moreover, we consider the privacy and security issues essential in machine unlearning and organize the latest related literature. Finally, we discuss the challenges of various unlearning scenarios and address the potential research directions.
5/14/2024

Gone but Not Forgotten: Improved Benchmarks for Machine Unlearning
Keltin Grimes, Collin Abidi, Cole Frank, Shannon Gallagher
0
0
Machine learning models are vulnerable to adversarial attacks, including attacks that leak information about the model's training data. There has recently been an increase in interest about how to best address privacy concerns, especially in the presence of data-removal requests. Machine unlearning algorithms aim to efficiently update trained models to comply with data deletion requests while maintaining performance and without having to resort to retraining the model from scratch, a costly endeavor. Several algorithms in the machine unlearning literature demonstrate some level of privacy gains, but they are often evaluated only on rudimentary membership inference attacks, which do not represent realistic threats. In this paper we describe and propose alternative evaluation methods for three key shortcomings in the current evaluation of unlearning algorithms. We show the utility of our alternative evaluations via a series of experiments of state-of-the-art unlearning algorithms on different computer vision datasets, presenting a more detailed picture of the state of the field.
5/30/2024
🤔
Machine Unlearning in Contrastive Learning
Zixin Wang, Kongyang Chen
0
0
Machine unlearning is a complex process that necessitates the model to diminish the influence of the training data while keeping the loss of accuracy to a minimum. Despite the numerous studies on machine unlearning in recent years, the majority of them have primarily focused on supervised learning models, leaving research on contrastive learning models relatively underexplored. With the conviction that self-supervised learning harbors a promising potential, surpassing or rivaling that of supervised learning, we set out to investigate methods for machine unlearning centered around contrastive learning models. In this study, we introduce a novel gradient constraint-based approach for training the model to effectively achieve machine unlearning. Our method only necessitates a minimal number of training epochs and the identification of the data slated for unlearning. Remarkably, our approach demonstrates proficient performance not only on contrastive learning models but also on supervised learning models, showcasing its versatility and adaptability in various learning paradigms.
5/14/2024

Data Selection for Transfer Unlearning
Nazanin Mohammadi Sepahvand, Vincent Dumoulin, Eleni Triantafillou, Gintare Karolina Dziugaite
0
0
As deep learning models are becoming larger and data-hungrier, there are growing ethical, legal and technical concerns over use of data: in practice, agreements on data use may change over time, rendering previously-used training data impermissible for training purposes. These issues have driven increased attention to machine unlearning: removing the influence of a subset of training data from a trained model. In this work, we advocate for a relaxed definition of unlearning that does not address privacy applications but targets a scenario where a data owner withdraws permission of use of their data for training purposes. In this context, we consider the important problem of emph{transfer unlearning} where a pretrained model is transferred to a target dataset that contains some non-static data that may need to be unlearned in the future. We propose a new method that uses a mechanism for selecting relevant examples from an auxiliary static dataset, and finetunes on the selected data instead of non-static target data; addressing all unlearning requests ahead of time. We also adapt a recent relaxed definition of unlearning to our problem setting and demonstrate that our approach is an exact transfer unlearner according to it, while being highly efficient (amortized). We find that our method outperforms the gold standard exact unlearning (finetuning on only the static portion of the target dataset) on several datasets, especially for small static sets, sometimes approaching an upper bound for test accuracy. We also analyze factors influencing the accuracy boost obtained by data selection.
5/20/2024