Dataset Distillation for Offline Reinforcement Learning

0
Sign in to get full access
Overview
- Offline reinforcement learning aims to learn effective policies from previously collected data without further environment interactions.
- Dataset distillation is a technique that compresses large datasets into smaller synthetic datasets, preserving the essential information for a given task.
- This paper proposes an approach to leverage dataset distillation for offline reinforcement learning, allowing for more efficient training and deployment of reinforcement learning models.
Plain English Explanation
This research paper describes a method for improving offline reinforcement learning, which is the process of training AI models to make decisions without requiring direct interaction with the real-world environment. The key idea is to use dataset distillation, a technique that can compress large datasets into smaller synthetic datasets that still contain the essential information needed for a given task.
By applying dataset distillation to offline reinforcement learning datasets, the researchers were able to train reinforcement learning models more efficiently and with less data. This could be useful in scenarios where data collection is expensive or difficult, such as robotics or complex simulations. The distilled datasets allow the models to learn effective decision-making policies without needing as much original training data.
The paper outlines the technical details of how they implemented this approach, including the specific algorithms and architectural choices. They also present experimental results showing the performance benefits of this method compared to training on the full original datasets.
Technical Explanation
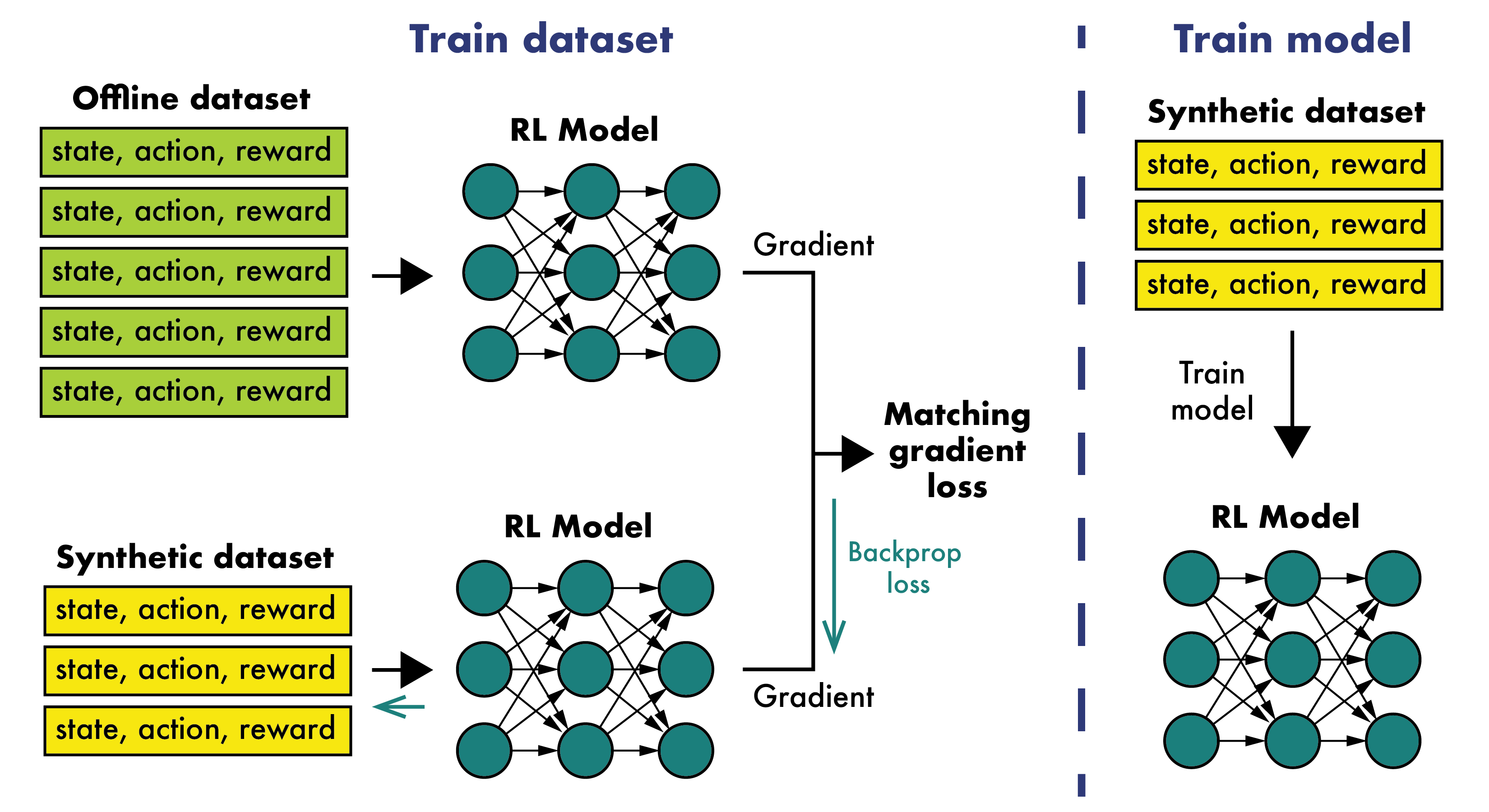
The paper proposes a method called "Dataset Distillation for Offline Reinforcement Learning" (DDORL) that leverages dataset distillation to improve the efficiency of offline reinforcement learning.
The key idea is to take a large dataset of experience collected from interactions with an environment (e.g., trajectories of states, actions, and rewards) and distill it into a much smaller synthetic dataset. This distilled dataset preserves the essential information needed to train an effective reinforcement learning policy, but requires far less storage and computation to use.
The DDORL method consists of two main components:
-
Dataset Distillation: The researchers adapt existing dataset distillation techniques to the offline reinforcement learning setting. This involves optimizing a small set of synthetic datapoints (states, actions, rewards) to mimic the statistical properties of the full dataset.
-
Offline Policy Learning: The distilled synthetic dataset is then used to train a reinforcement learning agent using standard offline RL algorithms like behavior cloning and batch-constrained Q-learning.
The authors evaluate DDORL on several standard benchmarks for offline RL, demonstrating significant improvements in sample efficiency and final performance compared to training on the full datasets. They also analyze the properties of the distilled datasets and show that they capture the key structures needed for effective policy learning.
Critical Analysis
The paper makes a compelling case for the benefits of using dataset distillation to improve offline reinforcement learning. By compressing large datasets into smaller synthetic versions, the method allows for more efficient training and deployment of reinforcement learning models.
However, the paper does not address some potential limitations and caveats of this approach:
-
Generalization Concerns: It's unclear how well the distilled datasets would generalize to novel situations beyond the original training data. The synthetic datapoints may not capture all the nuances and edge cases present in the real-world.
-
Hyperparameter Sensitivity: The performance of DDORL likely depends heavily on the specific hyperparameters and design choices for the distillation process. The paper does not provide a thorough sensitivity analysis.
-
Interpretability: The distilled datasets are synthetic and may be difficult for humans to interpret. This could make it challenging to understand and debug the learned policies.
-
Scalability: The authors only evaluate DDORL on relatively small-scale benchmark problems. Scaling the method to large, high-dimensional environments remains an open challenge.
Further research is needed to address these limitations and explore the broader applicability of dataset distillation for offline reinforcement learning. Incorporating curriculum learning or latent distillation techniques may also help improve the quality and generalization of the distilled datasets.
Conclusion
This paper presents a novel approach called "Dataset Distillation for Offline Reinforcement Learning" (DDORL) that leverages dataset distillation to improve the efficiency of offline reinforcement learning. By compressing large datasets into smaller synthetic versions, DDORL allows for more sample-efficient training of reinforcement learning models.
The proposed method demonstrates promising results on standard benchmarks, offering significant improvements in sample efficiency and final performance compared to training on the full datasets. However, the paper also highlights several important limitations and areas for future research, such as concerns about generalization, hyperparameter sensitivity, and interpretability.
Overall, this work represents an important step forward in the field of offline reinforcement learning, providing a new tool to make these techniques more practical and accessible. As the field continues to evolve, further advancements in dataset distillation and other novel approaches will be crucial for expanding the real-world impact of reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dataset Distillation for Offline Reinforcement Learning
Jonathan Light, Yuanzhe Liu, Ziniu Hu
Offline reinforcement learning often requires a quality dataset that we can train a policy on. However, in many situations, it is not possible to get such a dataset, nor is it easy to train a policy to perform well in the actual environment given the offline data. We propose using data distillation to train and distill a better dataset which can then be used for training a better policy model. We show that our method is able to synthesize a dataset where a model trained on it achieves similar performance to a model trained on the full dataset or a model trained using percentile behavioral cloning. Our project site is available at $href{https://datasetdistillation4rl.github.io}{text{here}}$. We also provide our implementation at $href{https://github.com/ggflow123/DDRL}{text{this GitHub repository}}$.
Read more8/2/2024

0
Behaviour Distillation
Andrei Lupu, Chris Lu, Jarek Liesen, Robert Tjarko Lange, Jakob Foerster
Dataset distillation aims to condense large datasets into a small number of synthetic examples that can be used as drop-in replacements when training new models. It has applications to interpretability, neural architecture search, privacy, and continual learning. Despite strong successes in supervised domains, such methods have not yet been extended to reinforcement learning, where the lack of a fixed dataset renders most distillation methods unusable. Filling the gap, we formalize behaviour distillation, a setting that aims to discover and then condense the information required for training an expert policy into a synthetic dataset of state-action pairs, without access to expert data. We then introduce Hallucinating Datasets with Evolution Strategies (HaDES), a method for behaviour distillation that can discover datasets of just four state-action pairs which, under supervised learning, train agents to competitive performance levels in continuous control tasks. We show that these datasets generalize out of distribution to training policies with a wide range of architectures and hyperparameters. We also demonstrate application to a downstream task, namely training multi-task agents in a zero-shot fashion. Beyond behaviour distillation, HaDES provides significant improvements in neuroevolution for RL over previous approaches and achieves SoTA results on one standard supervised dataset distillation task. Finally, we show that visualizing the synthetic datasets can provide human-interpretable task insights.
Read more6/24/2024

0
What is Dataset Distillation Learning?
William Yang, Ye Zhu, Zhiwei Deng, Olga Russakovsky
Dataset distillation has emerged as a strategy to overcome the hurdles associated with large datasets by learning a compact set of synthetic data that retains essential information from the original dataset. While distilled data can be used to train high performing models, little is understood about how the information is stored. In this study, we posit and answer three questions about the behavior, representativeness, and point-wise information content of distilled data. We reveal distilled data cannot serve as a substitute for real data during training outside the standard evaluation setting for dataset distillation. Additionally, the distillation process retains high task performance by compressing information related to the early training dynamics of real models. Finally, we provide an framework for interpreting distilled data and reveal that individual distilled data points contain meaningful semantic information. This investigation sheds light on the intricate nature of distilled data, providing a better understanding on how they can be effectively utilized.
Read more7/23/2024

0
Data-Efficient Generation for Dataset Distillation
Zhe Li, Weitong Zhang, Sarah Cechnicka, Bernhard Kainz
While deep learning techniques have proven successful in image-related tasks, the exponentially increased data storage and computation costs become a significant challenge. Dataset distillation addresses these challenges by synthesizing only a few images for each class that encapsulate all essential information. Most current methods focus on matching. The problems lie in the synthetic images not being human-readable and the dataset performance being insufficient for downstream learning tasks. Moreover, the distillation time can quickly get out of bounds when the number of synthetic images per class increases even slightly. To address this, we train a class conditional latent diffusion model capable of generating realistic synthetic images with labels. The sampling time can be reduced to several tens of images per seconds. We demonstrate that models can be effectively trained using only a small set of synthetic images and evaluated on a large real test set. Our approach achieved rank (1) in The First Dataset Distillation Challenge at ECCV 2024 on the CIFAR100 and TinyImageNet datasets.
Read more9/9/2024