DDAP: Dual-Domain Anti-Personalization against Text-to-Image Diffusion Models

0

Sign in to get full access
Overview
- The paper proposes a technique called Dual-Domain Anti-Personalization (DDAP) to prevent text-to-image diffusion models from generating personalized images.
- DDAP operates in both the text and image domains to remove personalization signals from the model.
- The authors demonstrate DDAP's effectiveness on various diffusion models and datasets.
Plain English Explanation
The paper addresses a problem with text-to-image diffusion models - these models can inadvertently generate personalized images that reflect the individual biases or preferences of the training data. The researchers developed a technique called Dual-Domain Anti-Personalization (DDAP) to address this issue.
DDAP works by removing personalization signals from the model in both the text and image domains. In the text domain, it removes personal information like names and locations from the training data. In the image domain, it makes the model generate more generic, less personalized images. The researchers show that DDAP can effectively reduce personalization across a variety of diffusion models and datasets.
Technical Explanation
The paper proposes a Dual-Domain Anti-Personalization (DDAP) technique to mitigate personalization in text-to-image diffusion models. The key elements are:
-
Text-Domain Debiasing: The authors remove personal information like names and locations from the training text captions to reduce personalization signals.
-
Image-Domain Debiasing: They introduce a token-level attention erasure technique to make the model generate more generic, less personalized images.
-
Evaluation: The researchers evaluate DDAP on various diffusion models and datasets, demonstrating its effectiveness at reducing personalization while preserving image quality.
Critical Analysis
The paper acknowledges some limitations of DDAP, such as the potential impact on image diversity and the need for careful data curation. The authors also note that their technique may not fully eliminate all personalization signals, as some subtle biases could still remain in the model.
An additional concern is the potential for DDAP to over-correct and produce overly generic, uninteresting images. The balance between reducing personalization and maintaining diversity and creativity in the generated images is an important challenge that warrants further investigation.
Conclusion
The DDAP technique presented in this paper is a valuable contribution to the field of text-to-image diffusion models. By addressing the issue of personalization, the authors have taken an important step towards developing more inclusive and equitable AI systems. While DDAP has some limitations, it represents a promising approach that could have significant implications for the responsible development of generative AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DDAP: Dual-Domain Anti-Personalization against Text-to-Image Diffusion Models
Jing Yang, Runping Xi, Yingxin Lai, Xun Lin, Zitong Yu
Diffusion-based personalized visual content generation technologies have achieved significant breakthroughs, allowing for the creation of specific objects by just learning from a few reference photos. However, when misused to fabricate fake news or unsettling content targeting individuals, these technologies could cause considerable societal harm. To address this problem, current methods generate adversarial samples by adversarially maximizing the training loss, thereby disrupting the output of any personalized generation model trained with these samples. However, the existing methods fail to achieve effective defense and maintain stealthiness, as they overlook the intrinsic properties of diffusion models. In this paper, we introduce a novel Dual-Domain Anti-Personalization framework (DDAP). Specifically, we have developed Spatial Perturbation Learning (SPL) by exploiting the fixed and perturbation-sensitive nature of the image encoder in personalized generation. Subsequently, we have designed a Frequency Perturbation Learning (FPL) method that utilizes the characteristics of diffusion models in the frequency domain. The SPL disrupts the overall texture of the generated images, while the FPL focuses on image details. By alternating between these two methods, we construct the DDAP framework, effectively harnessing the strengths of both domains. To further enhance the visual quality of the adversarial samples, we design a localization module to accurately capture attentive areas while ensuring the effectiveness of the attack and avoiding unnecessary disturbances in the background. Extensive experiments on facial benchmarks have shown that the proposed DDAP enhances the disruption of personalized generation models while also maintaining high quality in adversarial samples, making it more effective in protecting privacy in practical applications.
Read more7/30/2024
0
DP-RDM: Adapting Diffusion Models to Private Domains Without Fine-Tuning
Jonathan Lebensold, Maziar Sanjabi, Pietro Astolfi, Adriana Romero-Soriano, Kamalika Chaudhuri, Mike Rabbat, Chuan Guo
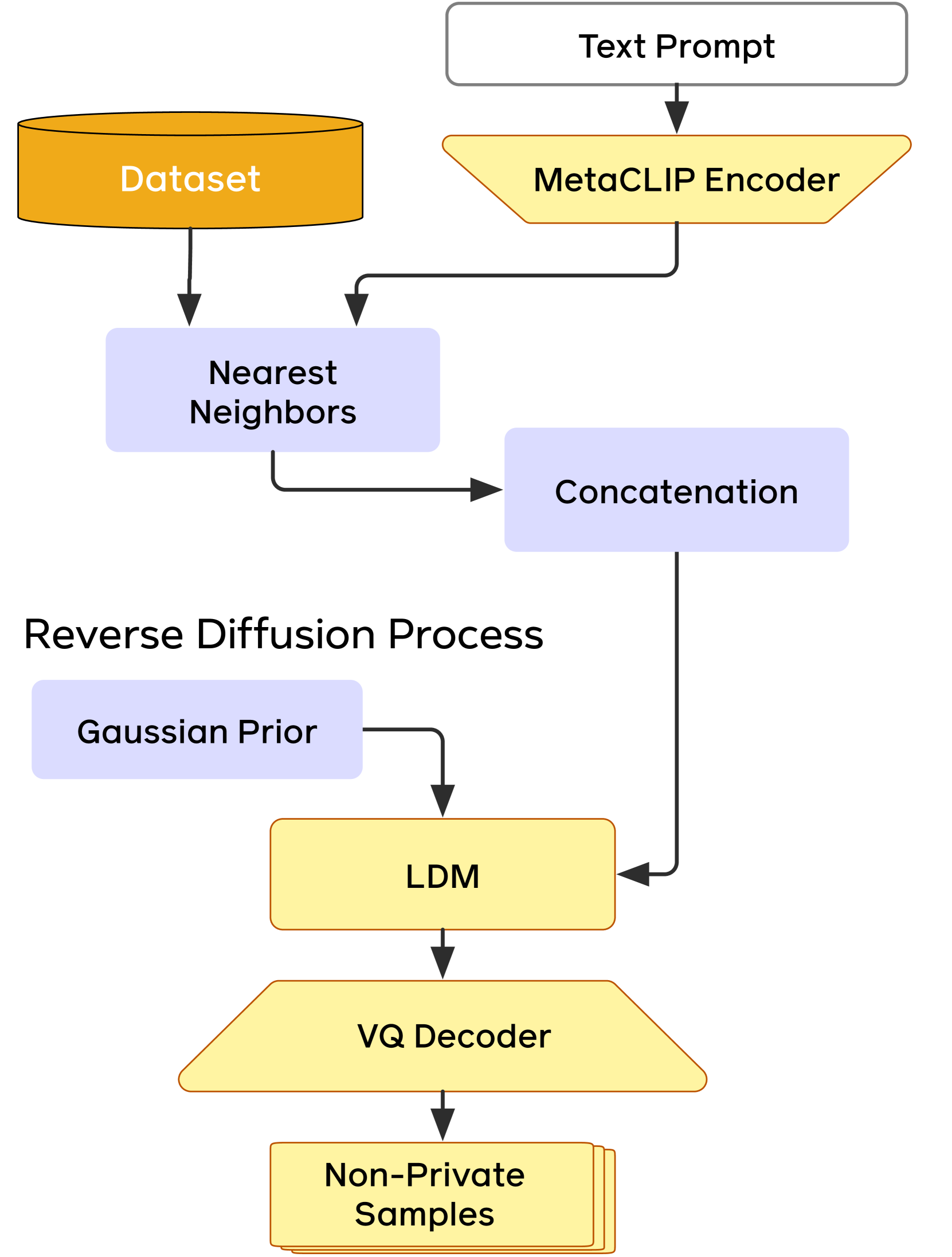
Text-to-image diffusion models have been shown to suffer from sample-level memorization, possibly reproducing near-perfect replica of images that they are trained on, which may be undesirable. To remedy this issue, we develop the first differentially private (DP) retrieval-augmented generation algorithm that is capable of generating high-quality image samples while providing provable privacy guarantees. Specifically, we assume access to a text-to-image diffusion model trained on a small amount of public data, and design a DP retrieval mechanism to augment the text prompt with samples retrieved from a private retrieval dataset. Our emph{differentially private retrieval-augmented diffusion model} (DP-RDM) requires no fine-tuning on the retrieval dataset to adapt to another domain, and can use state-of-the-art generative models to generate high-quality image samples while satisfying rigorous DP guarantees. For instance, when evaluated on MS-COCO, our DP-RDM can generate samples with a privacy budget of $epsilon=10$, while providing a $3.5$ point improvement in FID compared to public-only retrieval for up to $10,000$ queries.
Read more5/14/2024
🛸
0
Subject-Diffusion:Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning
Jian Ma, Junhao Liang, Chen Chen, Haonan Lu
Recent progress in personalized image generation using diffusion models has been significant. However, development in the area of open-domain and non-fine-tuning personalized image generation is proceeding rather slowly. In this paper, we propose Subject-Diffusion, a novel open-domain personalized image generation model that, in addition to not requiring test-time fine-tuning, also only requires a single reference image to support personalized generation of single- or multi-subject in any domain. Firstly, we construct an automatic data labeling tool and use the LAION-Aesthetics dataset to construct a large-scale dataset consisting of 76M images and their corresponding subject detection bounding boxes, segmentation masks and text descriptions. Secondly, we design a new unified framework that combines text and image semantics by incorporating coarse location and fine-grained reference image control to maximize subject fidelity and generalization. Furthermore, we also adopt an attention control mechanism to support multi-subject generation. Extensive qualitative and quantitative results demonstrate that our method outperforms other SOTA frameworks in single, multiple, and human customized image generation. Please refer to our href{https://oppo-mente-lab.github.io/subject_diffusion/}{project page}
Read more5/21/2024
0
Prompt-Agnostic Adversarial Perturbation for Customized Diffusion Models
Cong Wan, Yuhang He, Xiang Song, Yihong Gong
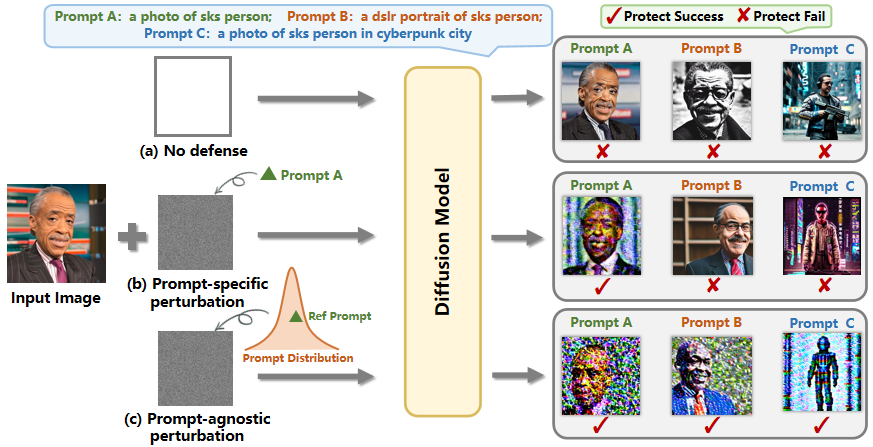
Diffusion models have revolutionized customized text-to-image generation, allowing for efficient synthesis of photos from personal data with textual descriptions. However, these advancements bring forth risks including privacy breaches and unauthorized replication of artworks. Previous researches primarily center around using prompt-specific methods to generate adversarial examples to protect personal images, yet the effectiveness of existing methods is hindered by constrained adaptability to different prompts. In this paper, we introduce a Prompt-Agnostic Adversarial Perturbation (PAP) method for customized diffusion models. PAP first models the prompt distribution using a Laplace Approximation, and then produces prompt-agnostic perturbations by maximizing a disturbance expectation based on the modeled distribution. This approach effectively tackles the prompt-agnostic attacks, leading to improved defense stability. Extensive experiments in face privacy and artistic style protection, demonstrate the superior generalization of our method in comparison to existing techniques.
Read more9/2/2024