Prompt-Agnostic Adversarial Perturbation for Customized Diffusion Models

0
Sign in to get full access
Overview
- Introduces a prompt-agnostic adversarial perturbation technique for customized diffusion models
- Demonstrates how this method can be used to generate customized images while maintaining high visual quality
- Discusses the importance of prompt-agnostic adversarial perturbation in the context of personalized content generation
Plain English Explanation
This paper presents a new technique called "prompt-agnostic adversarial perturbation" that can be used to generate customized images using diffusion models. Diffusion models are a type of machine learning model that can create images from scratch based on text descriptions, known as "prompts."
The key idea is that the researchers have developed a way to slightly modify the input to the diffusion model in a way that doesn't change the overall meaning of the prompt, but results in a customized image that is unique to the individual user. This is done by adding a small amount of "noise" to the input, which the model then uses to generate a new image.
The advantage of this approach is that it allows for personalized content generation while maintaining high visual quality. Rather than relying on a one-size-fits-all model, the prompt-agnostic adversarial perturbation technique can tailor the output to the user's preferences or needs.
This could be useful in a variety of applications, such as personalized content generation, privacy-preserving text generation, or customizable AI assistants.
Technical Explanation
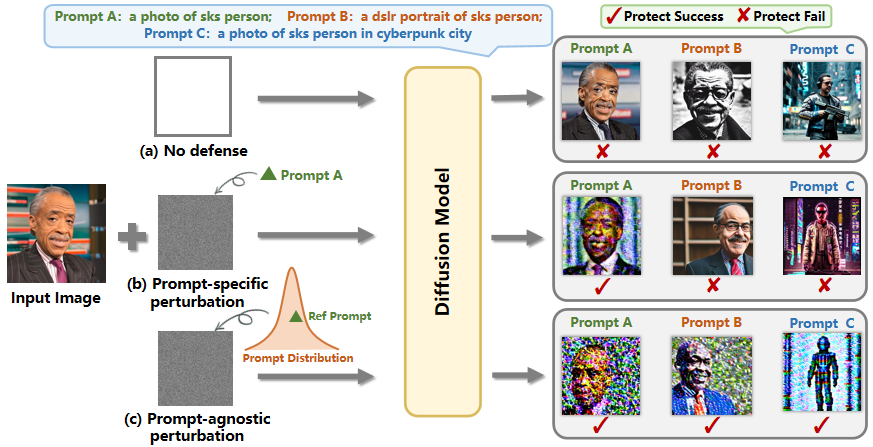
The paper proposes a novel technique called "prompt-agnostic adversarial perturbation" (PAAP) for customizing the outputs of diffusion models. The key idea is to add a small, imperceptible perturbation to the input prompt that does not change the semantic meaning, but leads to a customized image generation.
The researchers first define a set of target attributes that they want to control in the generated images, such as color scheme, style, or object placement. They then formulate an optimization problem to find the perturbation that maximizes the difference between the target attributes and the actual attributes of the generated image.
This optimization is performed in a "prompt-agnostic" manner, meaning that the perturbation is independent of the specific input prompt used. The researchers demonstrate that this approach can generate customized images across a wide range of prompts while maintaining high visual quality.
The paper also includes extensive experiments to validate the effectiveness of PAAP. They show that the method can generate images that match user preferences across various target attributes, and that the customized images are perceptually similar to the baseline images generated without perturbation.
Additionally, the researchers explore the robustness of PAAP to different diffusion models and dataset sizes, and investigate the transferability of the perturbations across models and datasets.
Critical Analysis
The paper presents a compelling approach to customizing the outputs of diffusion models, which is an important area of research given the increasing use of these models in various applications.
One potential limitation of the PAAP method is that it requires the definition of specific target attributes, which may not always be straightforward or align with user preferences. It would be interesting to see if the approach could be extended to more open-ended or user-specified customization goals.
Additionally, while the paper demonstrates the effectiveness of PAAP on a range of prompts and diffusion models, it would be valuable to understand the limitations or failure cases of the technique, as well as the computational overhead required for the optimization process.
Finally, the paper does not discuss the potential ethical implications of using such a customization technique, such as the risk of exacerbating biases or the need for transparency around the process. These are important considerations that should be addressed in future work.
Conclusion
The "prompt-agnostic adversarial perturbation" technique presented in this paper is a promising approach for customizing the outputs of diffusion models while maintaining high visual quality. By slightly modifying the input prompts in a way that does not change their semantic meaning, the method can generate images tailored to user preferences or needs.
This work has important implications for personalized content generation, privacy-preserving text generation, and the development of customizable AI assistants. As diffusion models continue to be widely adopted, techniques like PAAP will become increasingly important for ensuring that the generated content meets the diverse needs and preferences of users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prompt-Agnostic Adversarial Perturbation for Customized Diffusion Models
Cong Wan, Yuhang He, Xiang Song, Yihong Gong
Diffusion models have revolutionized customized text-to-image generation, allowing for efficient synthesis of photos from personal data with textual descriptions. However, these advancements bring forth risks including privacy breaches and unauthorized replication of artworks. Previous researches primarily center around using prompt-specific methods to generate adversarial examples to protect personal images, yet the effectiveness of existing methods is hindered by constrained adaptability to different prompts. In this paper, we introduce a Prompt-Agnostic Adversarial Perturbation (PAP) method for customized diffusion models. PAP first models the prompt distribution using a Laplace Approximation, and then produces prompt-agnostic perturbations by maximizing a disturbance expectation based on the modeled distribution. This approach effectively tackles the prompt-agnostic attacks, leading to improved defense stability. Extensive experiments in face privacy and artistic style protection, demonstrate the superior generalization of our method in comparison to existing techniques.
Read more9/2/2024

0
DDAP: Dual-Domain Anti-Personalization against Text-to-Image Diffusion Models
Jing Yang, Runping Xi, Yingxin Lai, Xun Lin, Zitong Yu
Diffusion-based personalized visual content generation technologies have achieved significant breakthroughs, allowing for the creation of specific objects by just learning from a few reference photos. However, when misused to fabricate fake news or unsettling content targeting individuals, these technologies could cause considerable societal harm. To address this problem, current methods generate adversarial samples by adversarially maximizing the training loss, thereby disrupting the output of any personalized generation model trained with these samples. However, the existing methods fail to achieve effective defense and maintain stealthiness, as they overlook the intrinsic properties of diffusion models. In this paper, we introduce a novel Dual-Domain Anti-Personalization framework (DDAP). Specifically, we have developed Spatial Perturbation Learning (SPL) by exploiting the fixed and perturbation-sensitive nature of the image encoder in personalized generation. Subsequently, we have designed a Frequency Perturbation Learning (FPL) method that utilizes the characteristics of diffusion models in the frequency domain. The SPL disrupts the overall texture of the generated images, while the FPL focuses on image details. By alternating between these two methods, we construct the DDAP framework, effectively harnessing the strengths of both domains. To further enhance the visual quality of the adversarial samples, we design a localization module to accurately capture attentive areas while ensuring the effectiveness of the attack and avoiding unnecessary disturbances in the background. Extensive experiments on facial benchmarks have shown that the proposed DDAP enhances the disruption of personalized generation models while also maintaining high quality in adversarial samples, making it more effective in protecting privacy in practical applications.
Read more7/30/2024

0
Not All Prompts Are Made Equal: Prompt-based Pruning of Text-to-Image Diffusion Models
Alireza Ganjdanesh, Reza Shirkavand, Shangqian Gao, Heng Huang
Text-to-image (T2I) diffusion models have demonstrated impressive image generation capabilities. Still, their computational intensity prohibits resource-constrained organizations from deploying T2I models after fine-tuning them on their internal target data. While pruning techniques offer a potential solution to reduce the computational burden of T2I models, static pruning methods use the same pruned model for all input prompts, overlooking the varying capacity requirements of different prompts. Dynamic pruning addresses this issue by utilizing a separate sub-network for each prompt, but it prevents batch parallelism on GPUs. To overcome these limitations, we introduce Adaptive Prompt-Tailored Pruning (APTP), a novel prompt-based pruning method designed for T2I diffusion models. Central to our approach is a prompt router model, which learns to determine the required capacity for an input text prompt and routes it to an architecture code, given a total desired compute budget for prompts. Each architecture code represents a specialized model tailored to the prompts assigned to it, and the number of codes is a hyperparameter. We train the prompt router and architecture codes using contrastive learning, ensuring that similar prompts are mapped to nearby codes. Further, we employ optimal transport to prevent the codes from collapsing into a single one. We demonstrate APTP's effectiveness by pruning Stable Diffusion (SD) V2.1 using CC3M and COCO as target datasets. APTP outperforms the single-model pruning baselines in terms of FID, CLIP, and CMMD scores. Our analysis of the clusters learned by APTP reveals they are semantically meaningful. We also show that APTP can automatically discover previously empirically found challenging prompts for SD, e.g., prompts for generating text images, assigning them to higher capacity codes.
Read more6/19/2024

0
Anonymization Prompt Learning for Facial Privacy-Preserving Text-to-Image Generation
Liang Shi, Jie Zhang, Shiguang Shan
Text-to-image diffusion models, such as Stable Diffusion, generate highly realistic images from text descriptions. However, the generation of certain content at such high quality raises concerns. A prominent issue is the accurate depiction of identifiable facial images, which could lead to malicious deepfake generation and privacy violations. In this paper, we propose Anonymization Prompt Learning (APL) to address this problem. Specifically, we train a learnable prompt prefix for text-to-image diffusion models, which forces the model to generate anonymized facial identities, even when prompted to produce images of specific individuals. Extensive quantitative and qualitative experiments demonstrate the successful anonymization performance of APL, which anonymizes any specific individuals without compromising the quality of non-identity-specific image generation. Furthermore, we reveal the plug-and-play property of the learned prompt prefix, enabling its effective application across different pretrained text-to-image models for transferrable privacy and security protection against the risks of deepfakes.
Read more6/21/2024