DDoS: Diffusion Distribution Similarity for Out-of-Distribution Detection

0

Sign in to get full access
Overview
- The paper proposes a novel approach called Diffusion Distribution Similarity (DDoS) for detecting out-of-distribution (OOD) samples in machine learning models.
- DDoS leverages the distribution of diffusion features extracted from the input data to identify samples that are significantly different from the training data.
- The method is shown to outperform existing OOD detection techniques on various benchmark datasets.
Plain English Explanation
The paper introduces a new way to detect when a machine learning model is being shown data that is very different from the information it was trained on. This is an important problem, as models can perform poorly or produce unreliable outputs when presented with unexpected or "out-of-distribution" data.
The key idea behind the DDoS approach is to look at how the input data "diffuses" through the neural network. Specifically, the researchers extract certain features from the intermediate layers of the model that capture patterns in the data. They then compare the distribution of these diffusion features for a given input to the distribution seen during training. If the new input is significantly different, it is flagged as out-of-distribution.
This diffusion-based approach allows DDoS to identify OOD samples without needing to explicitly model the training data distribution, which can be challenging. The method is demonstrated to outperform other popular OOD detection techniques across a range of benchmark datasets.
Technical Explanation
The DDoS method works by extracting "diffusion features" from the intermediate layers of a pre-trained neural network model. These features capture the way the input data propagates through the network and are hypothesized to be sensitive to distributional shifts.
Specifically, DDoS computes the mean and covariance of the activations at each layer, forming a multi-dimensional diffusion feature vector for each input. It then measures the similarity between the diffusion feature distribution of a test input and the distribution seen during training using the Wasserstein distance.
Inputs with a large Wasserstein distance are deemed out-of-distribution, as they exhibit significantly different diffusion characteristics compared to the training data. This OOD score can then be used to filter out problematic samples before they are passed to the downstream task model.
The authors evaluate DDoS on several benchmark OOD detection datasets, including CIFAR-10, SVHN, and ImageNet. They show that it outperforms existing methods like ODIN, Mahalanobis, and energy-based scoring in terms of both detection accuracy and computational efficiency.
Critical Analysis
The DDoS method presents a promising new approach for OOD detection that leverages the internal representations learned by neural networks. By focusing on diffusion features rather than directly modeling the training data distribution, it avoids some of the challenges associated with density estimation in high-dimensional spaces.
However, the paper does not explore the limitations of the method in depth. For example, it is unclear how DDoS would perform on more complex or ambiguous OOD samples that share similarities with the training data. The authors also do not investigate the sensitivity of the approach to hyperparameter choices or the specifics of the pre-trained model being used.
Additionally, while the experiments demonstrate the effectiveness of DDoS on standard benchmarks, more real-world evaluations are needed to assess its practical applicability. OOD detection in deployed systems often involves dealing with a diverse range of potential distribution shifts, which may require more sophisticated techniques than those presented here.
Overall, the DDoS method is an interesting contribution to the field of OOD detection, but further research is needed to fully understand its strengths, weaknesses, and the scope of problems it can effectively address.
Conclusion
The DDoS paper introduces a novel approach for detecting out-of-distribution samples in machine learning models. By analyzing the distribution of diffusion features extracted from the internal layers of a pre-trained network, the method can identify inputs that exhibit significantly different characteristics compared to the training data.
The experimental results demonstrate that DDoS outperforms existing OOD detection techniques on several benchmark datasets. This suggests that the approach could be a valuable tool for improving the robustness and reliability of deployed machine learning systems, which often face challenges posed by unexpected or distribution-shifted data.
While the paper provides a solid foundation for this diffusion-based OOD detection strategy, further research is needed to fully understand its limitations and explore ways to enhance its capabilities for more complex real-world scenarios. Nonetheless, the DDoS method represents an interesting and promising direction in this important area of machine learning research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DDoS: Diffusion Distribution Similarity for Out-of-Distribution Detection
Kun Fang, Qinghua Tao, Zuopeng Yang, Xiaolin Huang, Jie Yang
Out-of-Distribution (OoD) detection determines whether the given samples are from the training distribution of the classifier-under-protection, i.e., the In-Distribution (InD), or from a different OoD. Latest researches introduce diffusion models pre-trained on InD data to advocate OoD detection by transferring an OoD image into a generated one that is close to InD, so that one could capture the distribution disparities between original and generated images to detect OoD data. Existing diffusion-based detectors adopt perceptual metrics on the two images to measure such disparities, but ignore a fundamental fact: Perceptual metrics are devised essentially for human-perceived similarities of low-level image patterns, e.g., textures and colors, and are not advisable in evaluating distribution disparities, since images with different low-level patterns could possibly come from the same distribution. To address this issue, we formulate a diffusion-based detection framework that considers the distribution similarity between a tested image and its generated counterpart via a novel proper similarity metric in the informative feature space and probability space learned by the classifier-under-protection. An anomaly-removal strategy is further presented to enlarge such distribution disparities by removing abnormal OoD information in the feature space to facilitate the detection. Extensive empirical results unveil the insufficiency of perceptual metrics and the effectiveness of our distribution similarity framework with new state-of-the-art detection performance.
Read more9/17/2024
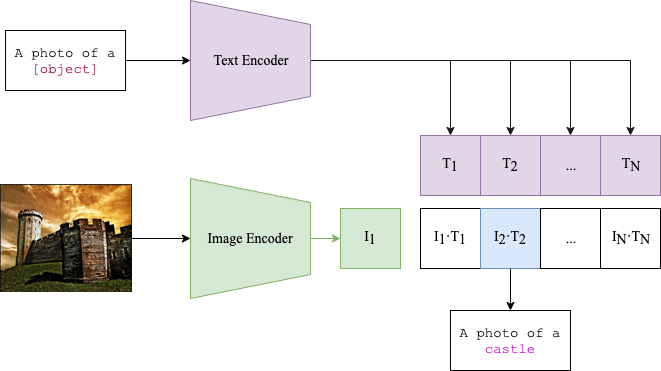
0
Exploiting Diffusion Prior for Out-of-Distribution Detection
Armando Zhu, Jiabei Liu, Keqin Li, Shuying Dai, Bo Hong, Peng Zhao, Changsong Wei
Out-of-distribution (OOD) detection is crucial for deploying robust machine learning models, especially in areas where security is critical. However, traditional OOD detection methods often fail to capture complex data distributions from large scale date. In this paper, we present a novel approach for OOD detection that leverages the generative ability of diffusion models and the powerful feature extraction capabilities of CLIP. By using these features as conditional inputs to a diffusion model, we can reconstruct the images after encoding them with CLIP. The difference between the original and reconstructed images is used as a signal for OOD identification. The practicality and scalability of our method is increased by the fact that it does not require class-specific labeled ID data, as is the case with many other methods. Extensive experiments on several benchmark datasets demonstrates the robustness and effectiveness of our method, which have significantly improved the detection accuracy.
Read more8/22/2024

0
Diffusion for Out-of-Distribution Detection on Road Scenes and Beyond
Silvio Galesso, Philipp Schroppel, Hssan Driss, Thomas Brox
In recent years, research on out-of-distribution (OoD) detection for semantic segmentation has mainly focused on road scenes -- a domain with a constrained amount of semantic diversity. In this work, we challenge this constraint and extend the domain of this task to general natural images. To this end, we introduce: 1. the ADE-OoD benchmark, which is based on the ADE20k dataset and includes images from diverse domains with a high semantic diversity, and 2. a novel approach that uses Diffusion score matching for OoD detection (DOoD) and is robust to the increased semantic diversity. ADE-OoD features indoor and outdoor images, defines 150 semantic categories as in-distribution, and contains a variety of OoD objects. For DOoD, we train a diffusion model with an MLP architecture on semantic in-distribution embeddings and build on the score matching interpretation to compute pixel-wise OoD scores at inference time. On common road scene OoD benchmarks, DOoD performs on par or better than the state of the art, without using outliers for training or making assumptions about the data domain. On ADE-OoD, DOoD outperforms previous approaches, but leaves much room for future improvements.
Read more7/23/2024
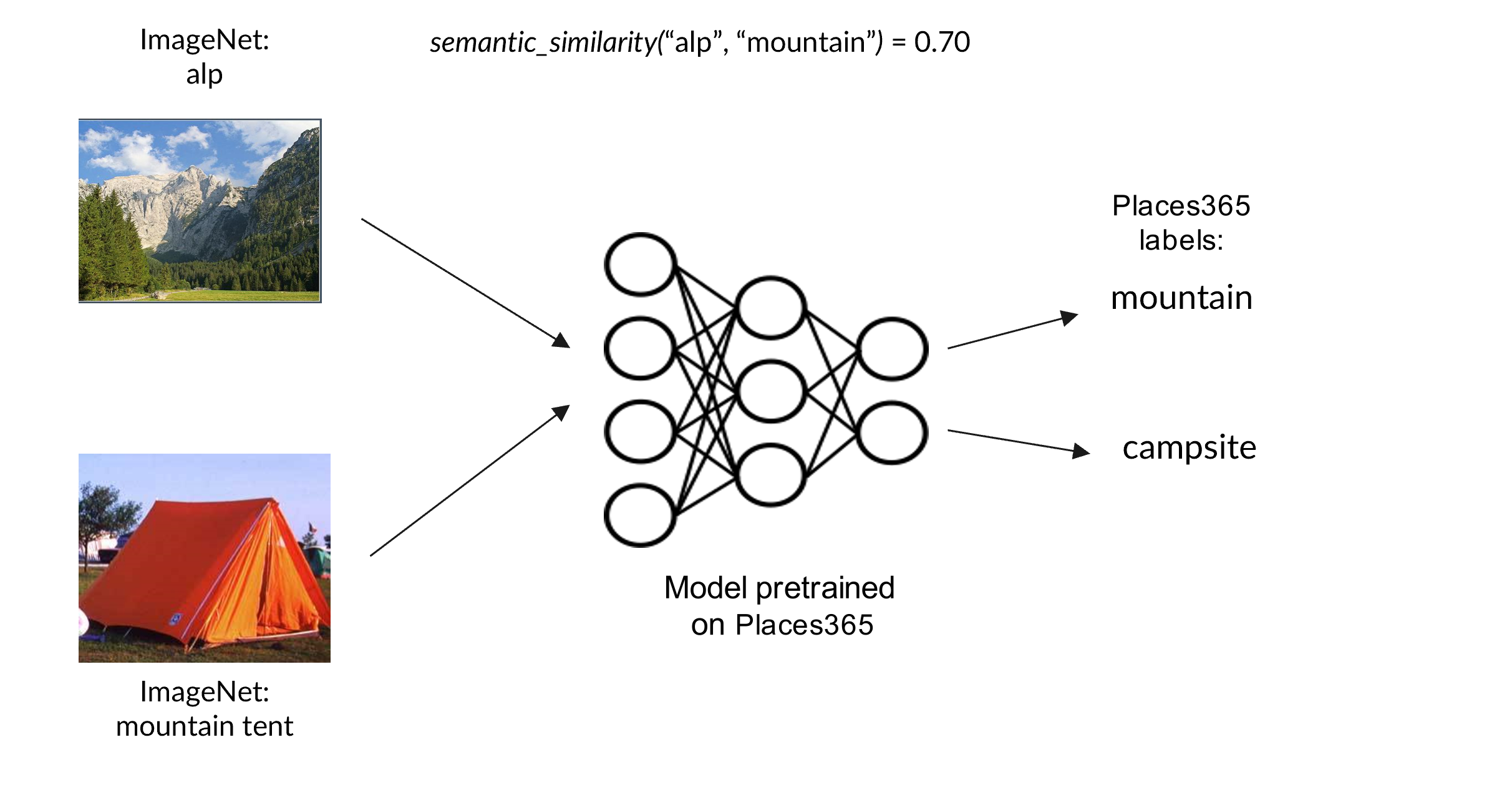
0
Toward a Realistic Benchmark for Out-of-Distribution Detection
Pietro Recalcati, Fabio Garcea, Luca Piano, Fabrizio Lamberti, Lia Morra
Deep neural networks are increasingly used in a wide range of technologies and services, but remain highly susceptible to out-of-distribution (OOD) samples, that is, drawn from a different distribution than the original training set. A common approach to address this issue is to endow deep neural networks with the ability to detect OOD samples. Several benchmarks have been proposed to design and validate OOD detection techniques. However, many of them are based on far-OOD samples drawn from very different distributions, and thus lack the complexity needed to capture the nuances of real-world scenarios. In this work, we introduce a comprehensive benchmark for OOD detection, based on ImageNet and Places365, that assigns individual classes as in-distribution or out-of-distribution depending on the semantic similarity with the training set. Several techniques can be used to determine which classes should be considered in-distribution, yielding benchmarks with varying properties. Experimental results on different OOD detection techniques show how their measured efficacy depends on the selected benchmark and how confidence-based techniques may outperform classifier-based ones on near-OOD samples.
Read more4/17/2024