Decentralized Personalized Federated Learning based on a Conditional Sparse-to-Sparser Scheme
2404.15943
0
0
Abstract
Decentralized Federated Learning (DFL) has become popular due to its robustness and avoidance of centralized coordination. In this paradigm, clients actively engage in training by exchanging models with their networked neighbors. However, DFL introduces increased costs in terms of training and communication. Existing methods focus on minimizing communication often overlooking training efficiency and data heterogeneity. To address this gap, we propose a novel textit{sparse-to-sparser} training scheme: DA-DPFL. DA-DPFL initializes with a subset of model parameters, which progressively reduces during training via textit{dynamic aggregation} and leads to substantial energy savings while retaining adequate information during critical learning periods. Our experiments showcase that DA-DPFL substantially outperforms DFL baselines in test accuracy, while achieving up to $5$ times reduction in energy costs. We provide a theoretical analysis of DA-DPFL's convergence by solidifying its applicability in decentralized and personalized learning. The code is available at:https://github.com/EricLoong/da-dpfl
Create account to get full access
Overview
- This paper proposes a decentralized personalized federated learning approach based on a conditional 'sparse-to-sparser' scheme.
- The key ideas are to leverage model pruning and sparsification to improve the efficiency and personalization of federated learning in decentralized settings.
- The approach aims to address the challenges of heterogeneity and communication constraints in federated learning scenarios.
Plain English Explanation
Federated learning is a way for multiple devices or organizations to train machine learning models together without sharing their raw data. This can be useful when the data is sensitive or distributed across many locations. However, federated learning can be challenging when the devices have very different capabilities or data distributions.
This paper introduces a new approach to federated learning that tries to address these challenges. The key idea is to gradually make the machine learning models smaller and more specialized for each device, using a technique called "model pruning". This can reduce the amount of data that needs to be shared between devices, which is important when the network connections are slow or unreliable.
The researchers also use another technique called "sparsification" to further compress the models, making them even smaller and more efficient. The goal is to create personalized models that work well for each individual device or organization, while still allowing them to benefit from the collective knowledge gained through federated learning.
By using these techniques, the researchers hope to enable more effective and scalable federated learning, especially in decentralized settings where the devices and data may be quite heterogeneous.
Technical Explanation
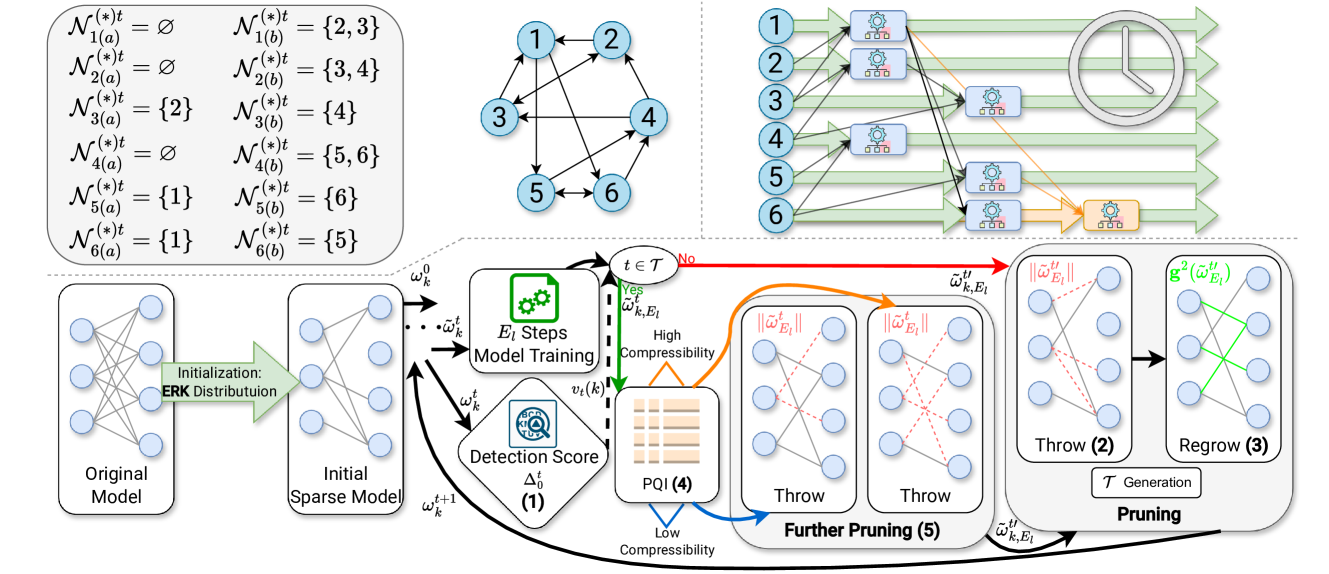
The paper proposes a Decentralized Personalized Federated Learning approach based on a conditional 'sparse-to-sparser' scheme. The key ideas are to leverage model pruning and sparsification to improve the efficiency and personalization of federated learning in decentralized settings.
The proposed approach consists of several steps:
- Initialization: Each client trains a personalized model using their local data.
- Conditioning: The personalized models are then conditioned on a global model, which helps to address the heterogeneity of the clients' data and models.
- Pruning and Sparsification: The conditioned models are progressively pruned and sparsified, reducing their size and communication requirements.
- Aggregation: The pruned and sparsified models are aggregated at the server, and the global model is updated.
- Redistribution: The updated global model is then redistributed to the clients for the next round of training.
The authors evaluate their approach on several benchmark datasets and show that it outperforms traditional federated learning methods in terms of personalization, communication efficiency, and energy efficiency. The sparsity-inducing nature of the approach also enables better scalability in decentralized settings.
Critical Analysis
The paper presents a promising approach for improving the efficiency and personalization of federated learning in decentralized settings. The use of model pruning and sparsification techniques is well-justified, as they can significantly reduce the communication overhead and enable more effective personalization.
However, the paper does not extensively discuss the potential drawbacks or limitations of the proposed approach. For example, the impact of the conditioning step on model performance and the tradeoffs involved in the pruning and sparsification process could be explored in more depth.
Additionally, while the experiments demonstrate the benefits of the approach, it would be valuable to see how it performs in real-world, large-scale scenarios with a diverse range of client devices and data distributions. Further research could also investigate the robustness of the approach to different types of model architectures and federated learning settings.
Overall, this paper presents an interesting and potentially impactful contribution to the field of decentralized federated learning. By addressing the challenges of heterogeneity and communication constraints, the proposed approach has the potential to enable more efficient and personalized machine learning in a wide range of applications.
Conclusion
The paper introduces a novel decentralized personalized federated learning approach based on a conditional 'sparse-to-sparser' scheme. By leveraging model pruning and sparsification techniques, the approach aims to improve the efficiency and personalization of federated learning in decentralized settings.
The key contributions of this work include the integration of conditioning, pruning, and sparsification into a unified federated learning framework, as well as the demonstration of the approach's benefits in terms of personalization, communication efficiency, and energy efficiency.
The proposed approach has the potential to enable more effective and scalable federated learning, especially in scenarios where the participating devices and data distributions are highly heterogeneous. Further research could explore the approach's robustness and real-world applicability, as well as investigate potential extensions or refinements to the core techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Decentralized Sporadic Federated Learning: A Unified Algorithmic Framework with Convergence Guarantees
Shahryar Zehtabi, Dong-Jun Han, Rohit Parasnis, Seyyedali Hosseinalipour, Christopher G. Brinton
0
0
Decentralized federated learning (DFL) captures FL settings where both (i) model updates and (ii) model aggregations are exclusively carried out by the clients without a central server. Existing DFL works have mostly focused on settings where clients conduct a fixed number of local updates between local model exchanges, overlooking heterogeneity and dynamics in communication and computation capabilities. In this work, we propose Decentralized Sporadic Federated Learning (DSpodFL), a DFL methodology built on a generalized notion of sporadicity in both local gradient and aggregation processes. DSpodFL subsumes many existing decentralized optimization methods under a unified algorithmic framework by modeling the per-iteration (i) occurrence of gradient descent at each client and (ii) exchange of models between client pairs as arbitrary indicator random variables, thus capturing heterogeneous and time-varying computation/communication scenarios. We analytically characterize the convergence behavior of DSpodFL for both convex and non-convex models, for both constant and diminishing learning rates, under mild assumptions on the communication graph connectivity, data heterogeneity across clients, and gradient noises, and show how our bounds recover existing results as special cases. Experiments demonstrate that DSpodFL consistently achieves improved training speeds compared with baselines under various system settings.
6/4/2024
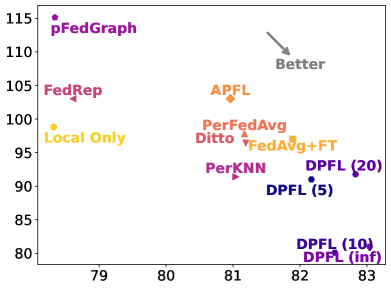
Decentralized Personalized Federated Learning
Salma Kharrat, Marco Canini, Samuel Horvath
0
0
This work tackles the challenges of data heterogeneity and communication limitations in decentralized federated learning. We focus on creating a collaboration graph that guides each client in selecting suitable collaborators for training personalized models that leverage their local data effectively. Our approach addresses these issues through a novel, communication-efficient strategy that enhances resource efficiency. Unlike traditional methods, our formulation identifies collaborators at a granular level by considering combinatorial relations of clients, enhancing personalization while minimizing communication overhead. We achieve this through a bi-level optimization framework that employs a constrained greedy algorithm, resulting in a resource-efficient collaboration graph for personalized learning. Extensive evaluation against various baselines across diverse datasets demonstrates the superiority of our method, named DPFL. DPFL consistently outperforms other approaches, showcasing its effectiveness in handling real-world data heterogeneity, minimizing communication overhead, enhancing resource efficiency, and building personalized models in decentralized federated learning scenarios.
6/11/2024
🚀
Decentralized Directed Collaboration for Personalized Federated Learning
Yingqi Liu, Yifan Shi, Qinglun Li, Baoyuan Wu, Xueqian Wang, Li Shen
0
0
Personalized Federated Learning (PFL) is proposed to find the greatest personalized models for each client. To avoid the central failure and communication bottleneck in the server-based FL, we concentrate on the Decentralized Personalized Federated Learning (DPFL) that performs distributed model training in a Peer-to-Peer (P2P) manner. Most personalized works in DPFL are based on undirected and symmetric topologies, however, the data, computation and communication resources heterogeneity result in large variances in the personalized models, which lead the undirected aggregation to suboptimal personalized performance and unguaranteed convergence. To address these issues, we propose a directed collaboration DPFL framework by incorporating stochastic gradient push and partial model personalized, called textbf{D}ecentralized textbf{Fed}erated textbf{P}artial textbf{G}radient textbf{P}ush (textbf{DFedPGP}). It personalizes the linear classifier in the modern deep model to customize the local solution and learns a consensus representation in a fully decentralized manner. Clients only share gradients with a subset of neighbors based on the directed and asymmetric topologies, which guarantees flexible choices for resource efficiency and better convergence. Theoretically, we show that the proposed DFedPGP achieves a superior convergence rate of $mathcal{O}(frac{1}{sqrt{T}})$ in the general non-convex setting, and prove the tighter connectivity among clients will speed up the convergence. The proposed method achieves state-of-the-art (SOTA) accuracy in both data and computation heterogeneity scenarios, demonstrating the efficiency of the directed collaboration and partial gradient push.
5/29/2024
🔎
Decentralized Federated Learning: A Survey and Perspective
Liangqi Yuan, Ziran Wang, Lichao Sun, Philip S. Yu, Christopher G. Brinton
0
0
Federated learning (FL) has been gaining attention for its ability to share knowledge while maintaining user data, protecting privacy, increasing learning efficiency, and reducing communication overhead. Decentralized FL (DFL) is a decentralized network architecture that eliminates the need for a central server in contrast to centralized FL (CFL). DFL enables direct communication between clients, resulting in significant savings in communication resources. In this paper, a comprehensive survey and profound perspective are provided for DFL. First, a review of the methodology, challenges, and variants of CFL is conducted, laying the background of DFL. Then, a systematic and detailed perspective on DFL is introduced, including iteration order, communication protocols, network topologies, paradigm proposals, and temporal variability. Next, based on the definition of DFL, several extended variants and categorizations are proposed with state-of-the-art (SOTA) technologies. Lastly, in addition to summarizing the current challenges in the DFL, some possible solutions and future research directions are also discussed.
5/7/2024