Decentralized Directed Collaboration for Personalized Federated Learning
2405.17876
0
0
🚀
Abstract
Personalized Federated Learning (PFL) is proposed to find the greatest personalized models for each client. To avoid the central failure and communication bottleneck in the server-based FL, we concentrate on the Decentralized Personalized Federated Learning (DPFL) that performs distributed model training in a Peer-to-Peer (P2P) manner. Most personalized works in DPFL are based on undirected and symmetric topologies, however, the data, computation and communication resources heterogeneity result in large variances in the personalized models, which lead the undirected aggregation to suboptimal personalized performance and unguaranteed convergence. To address these issues, we propose a directed collaboration DPFL framework by incorporating stochastic gradient push and partial model personalized, called textbf{D}ecentralized textbf{Fed}erated textbf{P}artial textbf{G}radient textbf{P}ush (textbf{DFedPGP}). It personalizes the linear classifier in the modern deep model to customize the local solution and learns a consensus representation in a fully decentralized manner. Clients only share gradients with a subset of neighbors based on the directed and asymmetric topologies, which guarantees flexible choices for resource efficiency and better convergence. Theoretically, we show that the proposed DFedPGP achieves a superior convergence rate of $mathcal{O}(frac{1}{sqrt{T}})$ in the general non-convex setting, and prove the tighter connectivity among clients will speed up the convergence. The proposed method achieves state-of-the-art (SOTA) accuracy in both data and computation heterogeneity scenarios, demonstrating the efficiency of the directed collaboration and partial gradient push.
Create account to get full access
Overview
- The paper proposes a new approach called Decentralized Federated Partial Gradient Push (DFedPGP) to address issues with personalized federated learning (PFL) in decentralized settings.
- Existing PFL methods often use undirected and symmetric topologies, leading to suboptimal personalized performance and unstable convergence due to resource heterogeneity.
- DFedPGP incorporates stochastic gradient push and partial model personalization, allowing clients to share gradients with a subset of neighbors in a directed, asymmetric manner for better efficiency and convergence.
Plain English Explanation
Personalized Federated Learning (PFL) aims to create customized machine learning models for individual users or "clients" by training on their local data. This is useful when the data and computing resources vary widely between clients, as is common in real-world applications.
However, traditional PFL approaches that rely on a central server can be prone to failures and communication bottlenecks. To address this, the paper focuses on Decentralized Personalized Federated Learning (DPFL), where the model training is done in a peer-to-peer (P2P) manner without a central server.
Most DPFL methods use undirected and symmetric network topologies, where clients share information equally with all their neighbors. But due to the heterogeneity in data, computation, and communication resources, this can lead to large variations in the personalized models, resulting in suboptimal performance and unstable convergence.
The proposed DFedPGP framework introduces a directed collaboration approach, where clients only share gradients with a subset of their neighbors based on an asymmetric topology. This allows for more flexible resource management and faster convergence. DFedPGP also incorporates partial model personalization, customizing only the linear classifier layer while learning a consensus representation across clients.
Technical Explanation
The key elements of the DFedPGP framework are:
-
Directed and Asymmetric Topology: Clients only share gradients with a subset of their neighbors, based on an directed and asymmetric network topology. This allows for more efficient resource utilization and better convergence compared to undirected, symmetric topologies used in prior DPFL methods.
-
Stochastic Gradient Push: Clients update their models by incorporating gradients from their neighbors, using a stochastic gradient push approach. This helps maintain a consensus representation across the network while allowing for personalized customization.
-
Partial Model Personalization: DFedPGP personalizes only the linear classifier layer of the deep learning model, while keeping the rest of the model layers shared across clients. This strikes a balance between personalization and global representation learning.
The paper provides a theoretical analysis showing that DFedPGP achieves a superior convergence rate of O(1/sqrt(T)) in the non-convex setting, where T is the number of training iterations. It also demonstrates that tighter client connectivity speeds up the convergence.
Experiments on both data and computational heterogeneity scenarios show that DFedPGP outperforms state-of-the-art DPFL methods, highlighting the benefits of the directed collaboration and partial gradient push approach.
Critical Analysis
The paper provides a comprehensive solution to address the limitations of existing DPFL methods, such as suboptimal personalized performance and unstable convergence. The proposed DFedPGP framework offers a principled way to leverage directed and asymmetric topologies for efficient resource utilization and faster convergence.
However, the paper does not explore the practical implications of implementing the directed topology in real-world scenarios, where establishing and maintaining such a network may introduce additional challenges. Additionally, the partial model personalization approach could be further investigated to understand the trade-offs between personalization and global representation learning in different applications.
Accelerating Hybrid Federated Learning Convergence under Partial is another relevant work that explores similar ideas of partial model personalization, which could be compared to the DFedPGP approach.
Further research could also investigate the performance of DFedPGP in more diverse and dynamic network environments, as well as its scalability to large-scale federated learning systems with heterogeneous and long-tailed data distributions.
Conclusion
The Decentralized Federated Partial Gradient Push (DFedPGP) framework proposed in this paper represents a significant advancement in personalized federated learning for decentralized settings. By incorporating directed and asymmetric topologies, stochastic gradient push, and partial model personalization, DFedPGP addresses the key challenges of resource heterogeneity and convergence issues in previous DPFL methods.
The superior convergence guarantees and state-of-the-art performance demonstrated in the paper suggest that DFedPGP could have a profound impact on real-world applications, particularly in scenarios with diverse client data and computing resources. As the field of federated learning continues to evolve, techniques like DFedPGP will be crucial in unlocking the full potential of personalized and decentralized machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
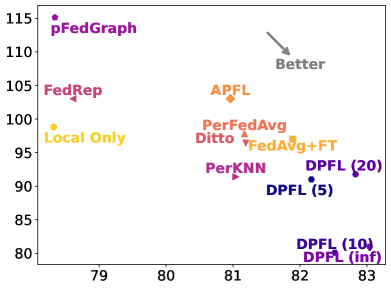
Decentralized Personalized Federated Learning
Salma Kharrat, Marco Canini, Samuel Horvath
0
0
This work tackles the challenges of data heterogeneity and communication limitations in decentralized federated learning. We focus on creating a collaboration graph that guides each client in selecting suitable collaborators for training personalized models that leverage their local data effectively. Our approach addresses these issues through a novel, communication-efficient strategy that enhances resource efficiency. Unlike traditional methods, our formulation identifies collaborators at a granular level by considering combinatorial relations of clients, enhancing personalization while minimizing communication overhead. We achieve this through a bi-level optimization framework that employs a constrained greedy algorithm, resulting in a resource-efficient collaboration graph for personalized learning. Extensive evaluation against various baselines across diverse datasets demonstrates the superiority of our method, named DPFL. DPFL consistently outperforms other approaches, showcasing its effectiveness in handling real-world data heterogeneity, minimizing communication overhead, enhancing resource efficiency, and building personalized models in decentralized federated learning scenarios.
6/11/2024
Decentralized Personalized Federated Learning based on a Conditional Sparse-to-Sparser Scheme
Qianyu Long, Qiyuan Wang, Christos Anagnostopoulos, Daning Bi
0
0
Decentralized Federated Learning (DFL) has become popular due to its robustness and avoidance of centralized coordination. In this paradigm, clients actively engage in training by exchanging models with their networked neighbors. However, DFL introduces increased costs in terms of training and communication. Existing methods focus on minimizing communication often overlooking training efficiency and data heterogeneity. To address this gap, we propose a novel textit{sparse-to-sparser} training scheme: DA-DPFL. DA-DPFL initializes with a subset of model parameters, which progressively reduces during training via textit{dynamic aggregation} and leads to substantial energy savings while retaining adequate information during critical learning periods. Our experiments showcase that DA-DPFL substantially outperforms DFL baselines in test accuracy, while achieving up to $5$ times reduction in energy costs. We provide a theoretical analysis of DA-DPFL's convergence by solidifying its applicability in decentralized and personalized learning. The code is available at:https://github.com/EricLoong/da-dpfl
4/26/2024

Personalized Federated Learning via Stacking
Emilio Cantu-Cervini
0
0
Traditional Federated Learning (FL) methods typically train a single global model collaboratively without exchanging raw data. In contrast, Personalized Federated Learning (PFL) techniques aim to create multiple models that are better tailored to individual clients' data. We present a novel personalization approach based on stacked generalization where clients directly send each other privacy-preserving models to be used as base models to train a meta-model on private data. Our approach is flexible, accommodating various privacy-preserving techniques and model types, and can be applied in horizontal, hybrid, and vertically partitioned federations. Additionally, it offers a natural mechanism for assessing each client's contribution to the federation. Through comprehensive evaluations across diverse simulated data heterogeneity scenarios, we showcase the effectiveness of our method.
4/23/2024
🛠️
Decentralized Sporadic Federated Learning: A Unified Algorithmic Framework with Convergence Guarantees
Shahryar Zehtabi, Dong-Jun Han, Rohit Parasnis, Seyyedali Hosseinalipour, Christopher G. Brinton
0
0
Decentralized federated learning (DFL) captures FL settings where both (i) model updates and (ii) model aggregations are exclusively carried out by the clients without a central server. Existing DFL works have mostly focused on settings where clients conduct a fixed number of local updates between local model exchanges, overlooking heterogeneity and dynamics in communication and computation capabilities. In this work, we propose Decentralized Sporadic Federated Learning (DSpodFL), a DFL methodology built on a generalized notion of sporadicity in both local gradient and aggregation processes. DSpodFL subsumes many existing decentralized optimization methods under a unified algorithmic framework by modeling the per-iteration (i) occurrence of gradient descent at each client and (ii) exchange of models between client pairs as arbitrary indicator random variables, thus capturing heterogeneous and time-varying computation/communication scenarios. We analytically characterize the convergence behavior of DSpodFL for both convex and non-convex models, for both constant and diminishing learning rates, under mild assumptions on the communication graph connectivity, data heterogeneity across clients, and gradient noises, and show how our bounds recover existing results as special cases. Experiments demonstrate that DSpodFL consistently achieves improved training speeds compared with baselines under various system settings.
6/4/2024