Decentralized Smoothing ADMM for Quantile Regression with Non-Convex Sparse Penalties

0

Sign in to get full access
Overview
- This paper presents a decentralized algorithm for solving quantile regression problems with non-convex and non-smooth sparse penalties.
- The algorithm, called Decentralized Smoothing ADMM (DS-ADMM), combines the Alternating Direction Method of Multipliers (ADMM) with a smoothing technique to handle the non-convex and non-smooth penalties.
- The method is designed for distributed learning settings, where data and computation are divided across multiple nodes in a network.
Plain English Explanation
In this paper, the researchers developed a new algorithm to solve a specific type of machine learning problem called quantile regression. Quantile regression is a technique used to estimate the relationship between a set of predictor variables and different quantiles (or percentiles) of the target variable, rather than just the average relationship.
The researchers' algorithm, called Decentralized Smoothing ADMM (DS-ADMM), is designed to work in a distributed learning setting, where the data and computations are divided across multiple nodes or computers in a network. This is useful when the dataset is too large to fit on a single machine or when the data is naturally distributed, such as in healthcare or financial applications.
A key challenge the researchers addressed is that the objective function they want to minimize includes non-convex and non-smooth sparse penalties. These types of penalties are useful for feature selection, as they encourage the model to use only a subset of the available features. However, they also make the optimization problem more difficult to solve.
The DS-ADMM algorithm combines two powerful techniques to handle this challenge:
-
Alternating Direction Method of Multipliers (ADMM): This is an optimization algorithm that splits the original problem into smaller, easier-to-solve subproblems and coordinates their solutions.
-
Smoothing: The researchers apply a smoothing technique to the non-convex and non-smooth sparse penalties, which makes them easier to optimize while still preserving their essential properties.
By using these techniques, the DS-ADMM algorithm can efficiently solve the quantile regression problem in a decentralized setting, even with the challenges posed by the non-convex and non-smooth sparse penalties.
Technical Explanation
The key technical contributions of this paper are:
-
Decentralized Optimization Framework: The researchers formulate the quantile regression problem with non-convex and non-smooth sparse penalties in a distributed setting, where the data and computations are divided across multiple nodes in a network.
-
Decentralized Smoothing ADMM (DS-ADMM) Algorithm: To solve the problem, the researchers develop the DS-ADMM algorithm, which combines ADMM with a smoothing technique to handle the non-convex and non-smooth sparse penalties.
-
Convergence Analysis: The researchers provide a theoretical analysis of the convergence properties of the DS-ADMM algorithm, showing that it can converge to a stationary point of the original non-convex problem.
-
Experiments: The researchers evaluate the performance of the DS-ADMM algorithm on both synthetic and real-world datasets, comparing it to several baseline methods. The results demonstrate the effectiveness of the proposed approach.
The key technical insights from this paper are:
-
Leveraging ADMM: By using the ADMM framework, the researchers can decompose the original non-convex and non-smooth optimization problem into smaller, more tractable subproblems that can be solved efficiently in a distributed setting.
-
Smoothing Technique: The researchers apply a smoothing technique to the non-convex and non-smooth sparse penalties, which makes them easier to optimize while still preserving their essential properties.
-
Convergence Guarantees: The theoretical analysis shows that the DS-ADMM algorithm can converge to a stationary point of the original non-convex problem, despite the challenges posed by the non-convex and non-smooth sparse penalties.
Critical Analysis
The researchers have made a solid contribution by developing a decentralized algorithm that can effectively solve quantile regression problems with non-convex and non-smooth sparse penalties. However, there are a few potential limitations and areas for further research:
-
Sensitivity to Hyperparameters: The DS-ADMM algorithm relies on several hyperparameters, such as the smoothing parameter and the ADMM penalty parameter. The performance of the algorithm may be sensitive to the choice of these hyperparameters, which could make it challenging to apply in practice.
-
Communication Overhead: In a decentralized setting, the nodes in the network need to communicate with each other to coordinate the optimization process. This communication overhead could be a limiting factor, especially in large-scale distributed systems with high-latency or low-bandwidth connections.
-
Heterogeneous Data and Systems: The paper assumes that the data and computational resources are evenly distributed across the nodes in the network. In real-world scenarios, the data and computational capabilities may be more heterogeneous, which could pose additional challenges for the algorithm.
-
Broader Applicability: While the paper focuses on quantile regression with non-convex and non-smooth sparse penalties, the techniques developed here could potentially be extended to other types of non-convex optimization problems in distributed learning settings.
Overall, the DS-ADMM algorithm presented in this paper represents an important step forward in the field of decentralized optimization for machine learning, and the researchers have made a valuable contribution. However, as with any research, there are still opportunities for further improvements and extensions to address the limitations mentioned above.
Conclusion
This paper introduces the Decentralized Smoothing ADMM (DS-ADMM) algorithm, which is designed to solve quantile regression problems with non-convex and non-smooth sparse penalties in a distributed learning setting. The key innovations of the DS-ADMM algorithm are its use of ADMM to decompose the optimization problem and a smoothing technique to handle the non-convex and non-smooth sparse penalties.
The researchers provide a theoretical analysis of the convergence properties of the DS-ADMM algorithm and demonstrate its effectiveness through experiments on both synthetic and real-world datasets. While the algorithm has some potential limitations, such as sensitivity to hyperparameters and communication overhead, it represents an important advance in the field of decentralized optimization for machine learning.
The techniques developed in this paper could have significant implications for a wide range of applications, from healthcare and finance to transportation and smart city management, where distributed data and computation are the norm. By enabling efficient and robust optimization in these decentralized settings, the DS-ADMM algorithm has the potential to unlock new opportunities for machine learning-powered decision-making and insights.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Decentralized Smoothing ADMM for Quantile Regression with Non-Convex Sparse Penalties
Reza Mirzaeifard, Diyako Ghaderyan, Stefan Werner
In the rapidly evolving internet-of-things (IoT) ecosystem, effective data analysis techniques are crucial for handling distributed data generated by sensors. Addressing the limitations of existing methods, such as the sub-gradient approach, which fails to distinguish between active and non-active coefficients effectively, this paper introduces the decentralized smoothing alternating direction method of multipliers (DSAD) for penalized quantile regression. Our method leverages non-convex sparse penalties like the minimax concave penalty (MCP) and smoothly clipped absolute deviation (SCAD), improving the identification and retention of significant predictors. DSAD incorporates a total variation norm within a smoothing ADMM framework, achieving consensus among distributed nodes and ensuring uniform model performance across disparate data sources. This approach overcomes traditional convergence challenges associated with non-convex penalties in decentralized settings. We present theoretical proofs and extensive simulation results to validate the effectiveness of the DSAD, demonstrating its superiority in achieving reliable convergence and enhancing estimation accuracy compared with prior methods.
Read more8/12/2024

0
Federated Smoothing Proximal Gradient for Quantile Regression with Non-Convex Penalties
Reza Mirzaeifard, Diyako Ghaderyan, Stefan Werner
Distributed sensors in the internet-of-things (IoT) generate vast amounts of sparse data. Analyzing this high-dimensional data and identifying relevant predictors pose substantial challenges, especially when data is preferred to remain on the device where it was collected for reasons such as data integrity, communication bandwidth, and privacy. This paper introduces a federated quantile regression algorithm to address these challenges. Quantile regression provides a more comprehensive view of the relationship between variables than mean regression models. However, traditional approaches face difficulties when dealing with nonconvex sparse penalties and the inherent non-smoothness of the loss function. For this purpose, we propose a federated smoothing proximal gradient (FSPG) algorithm that integrates a smoothing mechanism with the proximal gradient framework, thereby enhancing both precision and computational speed. This integration adeptly handles optimization over a network of devices, each holding local data samples, making it particularly effective in federated learning scenarios. The FSPG algorithm ensures steady progress and reliable convergence in each iteration by maintaining or reducing the value of the objective function. By leveraging nonconvex penalties, such as the minimax concave penalty (MCP) and smoothly clipped absolute deviation (SCAD), the proposed method can identify and preserve key predictors within sparse models. Comprehensive simulations validate the robust theoretical foundations of the proposed algorithm and demonstrate improved estimation precision and reliable convergence.
Read more8/14/2024
🔍
0
A GPU-Accelerated Bi-linear ADMM Algorithm for Distributed Sparse Machine Learning
Alireza Olama, Andreas Lundell, Jan Kronqvist, Elham Ahmadi, Eduardo Camponogara
This paper introduces the Bi-linear consensus Alternating Direction Method of Multipliers (Bi-cADMM), aimed at solving large-scale regularized Sparse Machine Learning (SML) problems defined over a network of computational nodes. Mathematically, these are stated as minimization problems with convex local loss functions over a global decision vector, subject to an explicit $ell_0$ norm constraint to enforce the desired sparsity. The considered SML problem generalizes different sparse regression and classification models, such as sparse linear and logistic regression, sparse softmax regression, and sparse support vector machines. Bi-cADMM leverages a bi-linear consensus reformulation of the original non-convex SML problem and a hierarchical decomposition strategy that divides the problem into smaller sub-problems amenable to parallel computing. In Bi-cADMM, this decomposition strategy is based on a two-phase approach. Initially, it performs a sample decomposition of the data and distributes local datasets across computational nodes. Subsequently, a delayed feature decomposition of the data is conducted on Graphics Processing Units (GPUs) available to each node. This methodology allows Bi-cADMM to undertake computationally intensive data-centric computations on GPUs, while CPUs handle more cost-effective computations. The proposed algorithm is implemented within an open-source Python package called Parallel Sparse Fitting Toolbox (PsFiT), which is publicly available. Finally, computational experiments demonstrate the efficiency and scalability of our algorithm through numerical benchmarks across various SML problems featuring distributed datasets.
Read more6/27/2024
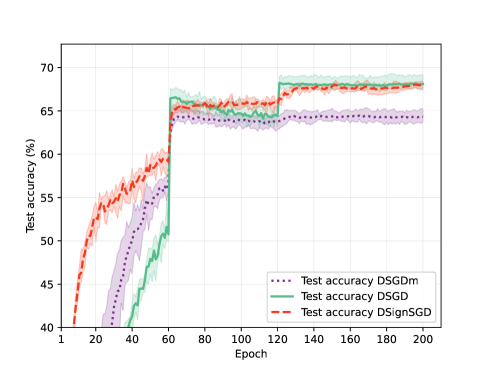
0
Decentralized Stochastic Subgradient Methods for Nonsmooth Nonconvex Optimization
Siyuan Zhang, Nachuan Xiao, Xin Liu
In this paper, we concentrate on decentralized optimization problems with nonconvex and nonsmooth objective functions, especially on the decentralized training of nonsmooth neural networks. We introduce a unified framework to analyze the global convergence of decentralized stochastic subgradient-based methods. We prove the global convergence of our proposed framework under mild conditions, by establishing that the generated sequence asymptotically approximates the trajectories of its associated differential inclusion. Furthermore, we establish that our proposed framework covers a wide range of existing efficient decentralized subgradient-based methods, including decentralized stochastic subgradient descent (DSGD), DSGD with gradient-tracking technique (DSGD-T), and DSGD with momentum (DSGD-M). In addition, we introduce the sign map to regularize the update directions in DSGD-M, and show it is enclosed in our proposed framework. Consequently, our convergence results establish, for the first time, global convergence of these methods when applied to nonsmooth nonconvex objectives. Preliminary numerical experiments demonstrate that our proposed framework yields highly efficient decentralized subgradient-based methods with convergence guarantees in the training of nonsmooth neural networks.
Read more6/28/2024