Decentralized Stochastic Subgradient Methods for Nonsmooth Nonconvex Optimization
2403.11565
0
0
Abstract
In this paper, we concentrate on decentralized optimization problems with nonconvex and nonsmooth objective functions, especially on the decentralized training of nonsmooth neural networks. We introduce a unified framework to analyze the global convergence of decentralized stochastic subgradient-based methods. We prove the global convergence of our proposed framework under mild conditions, by establishing that the generated sequence asymptotically approximates the trajectories of its associated differential inclusion. Furthermore, we establish that our proposed framework covers a wide range of existing efficient decentralized subgradient-based methods, including decentralized stochastic subgradient descent (DSGD), DSGD with gradient-tracking technique (DSGD-T), and DSGD with momentum (DSGD-M). In addition, we introduce the sign map to regularize the update directions in DSGD-M, and show it is enclosed in our proposed framework. Consequently, our convergence results establish, for the first time, global convergence of these methods when applied to nonsmooth nonconvex objectives. Preliminary numerical experiments demonstrate that our proposed framework yields highly efficient decentralized subgradient-based methods with convergence guarantees in the training of nonsmooth neural networks.
Create account to get full access
Overview
- This paper presents a decentralized stochastic subgradient method for optimizing nonsmooth and nonconvex functions.
- The method allows multiple agents to collaboratively solve an optimization problem in a decentralized manner, without a central coordinator.
- The authors provide theoretical guarantees on the convergence of the method and demonstrate its effectiveness on several numerical experiments.
Plain English Explanation
In many real-world optimization problems, the objective function is not smooth or convex, which makes it challenging to find the optimal solution. This paper proposes a decentralized approach to solving these types of nonsmooth and nonconvex optimization problems.
The key idea is to have multiple "agents" (e.g., devices, sensors, or computational nodes) work together to find the optimal solution, without the need for a central coordinator. Each agent maintains its own copy of the solution and communicates with its neighbors to update its solution. This decentralized approach can be more efficient and robust than a centralized approach, especially when the problem is large-scale or the agents are geographically distributed.
The authors develop a stochastic subgradient method that allows the agents to iteratively improve their solutions by using noisy or approximate information about the objective function. They also provide theoretical guarantees on the convergence of the method, meaning they can prove that the agents will eventually find a good solution to the problem.
To make the method more practical, the authors also consider the case where the objective function is nonconvex, which is a more general and challenging setting. They show that their method can still converge to a stationary point of the nonconvex objective function.
The authors validate their approach through numerical experiments, demonstrating its effectiveness on several benchmark problems. This research could have important applications in areas like distributed sensor networks, machine learning, and resource allocation, where decentralized optimization is crucial.
Technical Explanation
The paper presents a decentralized stochastic subgradient method for solving nonsmooth and nonconvex optimization problems. The authors consider the following optimization problem:
min_x f(x)
where f(x) is a nonsmooth and nonconvex function.
The key idea is to have multiple agents collaborate to solve this problem in a decentralized manner. Each agent maintains its own copy of the solution vector x and communicates with its neighbors to update its solution. The authors develop a decentralized stochastic subgradient method, where each agent uses noisy or approximate information about the subgradient of the objective function to update its solution.
The authors provide theoretical guarantees on the convergence of the proposed method. Specifically, they show that the iterates of the agents converge to a stationary point of the nonsmooth and nonconvex objective function f(x). This is a stronger result than previous work on decentralized optimization, which typically only guaranteed convergence to a local minimum.
To achieve this, the authors leverage tools from nonsmooth optimization, such as the Clarke subdifferential, and carefully design the stepsize and consensus parameters of the algorithm.
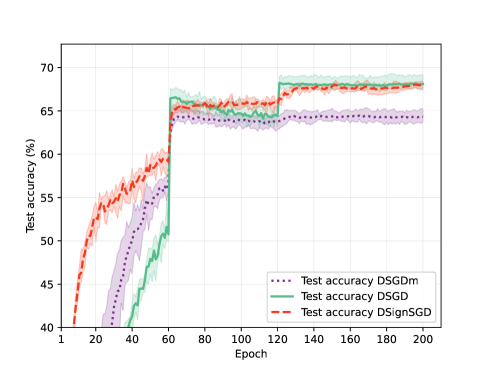
The authors validate their approach through numerical experiments on several benchmark problems, including nonsmooth and nonconvex functions. They demonstrate that the proposed method outperforms existing decentralized optimization algorithms, especially in terms of convergence speed and generalization guarantees.
Critical Analysis
The paper makes a significant contribution to the field of decentralized optimization, as it addresses the challenging case of nonsmooth and nonconvex objective functions. The theoretical guarantees provided by the authors are quite strong, as they show convergence to stationary points of the objective function, which is a more general result than convergence to local minima.
However, the paper also has some limitations. The analysis assumes that the agents have access to unbiased and bounded stochastic subgradients of the objective function, which may not always be the case in practice. Furthermore, the method requires the agents to know the network topology and the consensus parameters a priori, which may be difficult to obtain in some applications.
Additionally, the paper does not consider the case where the agents have heterogeneous objective functions or constraints, which is a more realistic setting for many real-world problems. Extending the proposed method to handle such heterogeneous scenarios could be an interesting direction for future research.
Overall, the paper presents a promising approach to decentralized optimization and provides a solid theoretical foundation for further developments in this area.
Conclusion
This paper introduces a decentralized stochastic subgradient method for solving nonsmooth and nonconvex optimization problems. The key contribution is the ability to provide theoretical guarantees on the convergence of the method to stationary points of the objective function, even in the challenging nonconvex setting.
The proposed approach could have significant implications for a wide range of applications, such as distributed sensor networks, machine learning, and resource allocation, where decentralized optimization is crucial. The authors demonstrate the effectiveness of their method through numerical experiments, and the paper provides a strong foundation for future research in this important area of optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
SGD-type Methods with Guaranteed Global Stability in Nonsmooth Nonconvex Optimization
Nachuan Xiao, Xiaoyin Hu, Kim-Chuan Toh
0
0
In this paper, we focus on providing convergence guarantees for variants of the stochastic subgradient descent (SGD) method in minimizing nonsmooth nonconvex functions. We first develop a general framework to establish global stability for general stochastic subgradient methods, where the corresponding differential inclusion admits a coercive Lyapunov function. We prove that, with sufficiently small stepsizes and controlled noises, the iterates asymptotically stabilize around the stable set of its corresponding differential inclusion. Then we introduce a scheme for developing SGD-type methods with regularized update directions for the primal variables. Based on our developed framework, we prove the global stability of our proposed scheme under mild conditions. We further illustrate that our scheme yields variants of SGD-type methods, which enjoy guaranteed convergence in training nonsmooth neural networks. In particular, by employing the sign map to regularize the update directions, we propose a novel subgradient method named the Sign-map Regularized SGD method (SRSGD). Preliminary numerical experiments exhibit the high efficiency of SRSGD in training deep neural networks.
5/15/2024

Developing Lagrangian-based Methods for Nonsmooth Nonconvex Optimization
Nachuan Xiao, Kuangyu Ding, Xiaoyin Hu, Kim-Chuan Toh
0
0
In this paper, we consider the minimization of a nonsmooth nonconvex objective function $f(x)$ over a closed convex subset $mathcal{X}$ of $mathbb{R}^n$, with additional nonsmooth nonconvex constraints $c(x) = 0$. We develop a unified framework for developing Lagrangian-based methods, which takes a single-step update to the primal variables by some subgradient methods in each iteration. These subgradient methods are ``embedded'' into our framework, in the sense that they are incorporated as black-box updates to the primal variables. We prove that our proposed framework inherits the global convergence guarantees from these embedded subgradient methods under mild conditions. In addition, we show that our framework can be extended to solve constrained optimization problems with expectation constraints. Based on the proposed framework, we show that a wide range of existing stochastic subgradient methods, including the proximal SGD, proximal momentum SGD, and proximal ADAM, can be embedded into Lagrangian-based methods. Preliminary numerical experiments on deep learning tasks illustrate that our proposed framework yields efficient variants of Lagrangian-based methods with convergence guarantees for nonconvex nonsmooth constrained optimization problems.
4/16/2024
Random Scaling and Momentum for Non-smooth Non-convex Optimization
Qinzi Zhang, Ashok Cutkosky
0
0
Training neural networks requires optimizing a loss function that may be highly irregular, and in particular neither convex nor smooth. Popular training algorithms are based on stochastic gradient descent with momentum (SGDM), for which classical analysis applies only if the loss is either convex or smooth. We show that a very small modification to SGDM closes this gap: simply scale the update at each time point by an exponentially distributed random scalar. The resulting algorithm achieves optimal convergence guarantees. Intriguingly, this result is not derived by a specific analysis of SGDM: instead, it falls naturally out of a more general framework for converting online convex optimization algorithms to non-convex optimization algorithms.
5/17/2024

Online Optimization Perspective on First-Order and Zero-Order Decentralized Nonsmooth Nonconvex Stochastic Optimization
Emre Sahinoglu, Shahin Shahrampour
0
0
We investigate the finite-time analysis of finding ($delta,epsilon$)-stationary points for nonsmooth nonconvex objectives in decentralized stochastic optimization. A set of agents aim at minimizing a global function using only their local information by interacting over a network. We present a novel algorithm, called Multi Epoch Decentralized Online Learning (ME-DOL), for which we establish the sample complexity in various settings. First, using a recently proposed online-to-nonconvex technique, we show that our algorithm recovers the optimal convergence rate of smooth nonconvex objectives. We then extend our analysis to the nonsmooth setting, building on properties of randomized smoothing and Goldstein-subdifferential sets. We establish the sample complexity of $O(delta^{-1}epsilon^{-3})$, which to the best of our knowledge is the first finite-time guarantee for decentralized nonsmooth nonconvex stochastic optimization in the first-order setting (without weak-convexity), matching its optimal centralized counterpart. We further prove the same rate for the zero-order oracle setting without using variance reduction.
6/4/2024