DecoderLens: Layerwise Interpretation of Encoder-Decoder Transformers

0
✅
Sign in to get full access
Overview
- Researchers propose a new method called DecoderLens to interpret the internal workings of encoder-decoder Transformer models.
- DecoderLens allows the decoder to cross-attend to representations from intermediate encoder layers, instead of just the final encoder output.
- The method maps the model's internal vector representations to human-interpretable sequences of words or symbols.
- The researchers apply DecoderLens to models trained on tasks like question answering, logical reasoning, speech recognition, and machine translation.
- DecoderLens reveals specific subtasks that are solved at low or intermediate encoder layers, providing new insights into the information flow within these models.
Plain English Explanation
Transformer models have become very powerful for tasks like language understanding and generation. However, it can be challenging to understand how these complex models work internally. Researchers have developed various "interpretability" methods to try to shed light on the inner workings of Transformers.
In this paper, the researchers propose a new approach called DecoderLens. The key idea is to give the decoder part of the Transformer model the ability to "look" at the representations generated by the intermediate layers of the encoder, not just the final output. This allows the researchers to map the model's internal vector representations to sequences of words or symbols that humans can interpret.
The researchers apply DecoderLens to Transformer models trained on tasks like question answering, logical reasoning, speech recognition, and machine translation. By doing this, they're able to see specific subtasks that the models solve at different layers of the encoder. This provides valuable insights into how information flows through these powerful but complex models.
For example, the DecoderLens method might reveal that the lower encoder layers are focused on basic language understanding, while the higher layers are tackling more complex reasoning. This type of granular insight can help researchers and engineers better understand and improve Transformer-based models.
Technical Explanation
The researchers propose a new interpretability method called DecoderLens to analyze encoder-decoder Transformer models. Typically, these models use the final output of the encoder as the input to the decoder. In contrast, DecoderLens allows the decoder to attend to representations from intermediate encoder layers.
This approach maps the model's internal vector representations to human-interpretable sequences of words or symbols, similar to how the LogitLens method works for decoder-only Transformers. The researchers apply DecoderLens to Transformer models trained on a variety of tasks, including question answering, logical reasoning, speech recognition, and machine translation.
By analyzing the outputs of the DecoderLens, the researchers are able to identify specific subtasks that are solved at different layers of the encoder. For example, they find that lower encoder layers focus on basic language understanding, while higher layers tackle more complex reasoning. This provides valuable insights into the information flow and internal workings of these important model architectures.
Critical Analysis
The researchers acknowledge that DecoderLens is a relatively simple method compared to some more complex interpretability techniques. However, they demonstrate that it is effective at revealing meaningful insights about the inner workings of encoder-decoder Transformer models.
One potential limitation is that the method relies on the ability of the decoder to accurately interpret the intermediate encoder representations. If there are significant mismatches between the encoder and decoder, the DecoderLens outputs may not fully capture the true nature of the encoder's internal processing.
Additionally, the researchers only apply DecoderLens to a limited set of tasks and model architectures. Further research would be needed to understand how well the method generalizes to a broader range of Transformer-based models and applications.
That said, the core idea of giving the decoder access to intermediate encoder representations is a clever and relatively simple approach to model interpretability. The insights gleaned from the DecoderLens experiments provide a valuable contribution to our understanding of how these powerful models function.
Conclusion
The DecoderLens method offers a new way to peek inside the "black box" of encoder-decoder Transformer models. By allowing the decoder to attend to intermediate encoder representations, the researchers are able to map the model's internal vector states to human-interpretable sequences of words or symbols.
Applying DecoderLens to a variety of Transformer-based models and tasks reveals specific subtasks that are solved at different layers of the encoder. This provides valuable insights into the information flow and internal workings of these important models, which can in turn help researchers and engineers better understand and improve them.
While DecoderLens is a relatively simple approach compared to some other interpretability techniques, its effectiveness in uncovering meaningful insights suggests it is a useful tool for analyzing the complex inner workings of Transformer-based architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
0
DecoderLens: Layerwise Interpretation of Encoder-Decoder Transformers
Anna Langedijk, Hosein Mohebbi, Gabriele Sarti, Willem Zuidema, Jaap Jumelet
In recent years, many interpretability methods have been proposed to help interpret the internal states of Transformer-models, at different levels of precision and complexity. Here, to analyze encoder-decoder Transformers, we propose a simple, new method: DecoderLens. Inspired by the LogitLens (for decoder-only Transformers), this method involves allowing the decoder to cross-attend representations of intermediate encoder layers instead of using the final encoder output, as is normally done in encoder-decoder models. The method thus maps previously uninterpretable vector representations to human-interpretable sequences of words or symbols. We report results from the DecoderLens applied to models trained on question answering, logical reasoning, speech recognition and machine translation. The DecoderLens reveals several specific subtasks that are solved at low or intermediate layers, shedding new light on the information flow inside the encoder component of this important class of models.
Read more4/4/2024
0
Transformers need glasses! Information over-squashing in language tasks
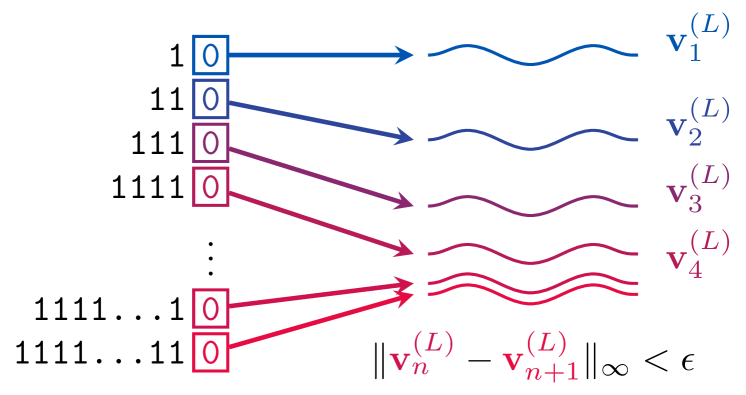
Federico Barbero, Andrea Banino, Steven Kapturowski, Dharshan Kumaran, Jo~ao G. M. Ara'ujo, Alex Vitvitskyi, Razvan Pascanu, Petar Veliv{c}kovi'c
We study how information propagates in decoder-only Transformers, which are the architectural backbone of most existing frontier large language models (LLMs). We rely on a theoretical signal propagation analysis -- specifically, we analyse the representations of the last token in the final layer of the Transformer, as this is the representation used for next-token prediction. Our analysis reveals a representational collapse phenomenon: we prove that certain distinct sequences of inputs to the Transformer can yield arbitrarily close representations in the final token. This effect is exacerbated by the low-precision floating-point formats frequently used in modern LLMs. As a result, the model is provably unable to respond to these sequences in different ways -- leading to errors in, e.g., tasks involving counting or copying. Further, we show that decoder-only Transformer language models can lose sensitivity to specific tokens in the input, which relates to the well-known phenomenon of over-squashing in graph neural networks. We provide empirical evidence supporting our claims on contemporary LLMs. Our theory also points to simple solutions towards ameliorating these issues.
Read more6/7/2024
2
A Primer on the Inner Workings of Transformer-based Language Models
Javier Ferrando, Gabriele Sarti, Arianna Bisazza, Marta R. Costa-juss`a
The rapid progress of research aimed at interpreting the inner workings of advanced language models has highlighted a need for contextualizing the insights gained from years of work in this area. This primer provides a concise technical introduction to the current techniques used to interpret the inner workings of Transformer-based language models, focusing on the generative decoder-only architecture. We conclude by presenting a comprehensive overview of the known internal mechanisms implemented by these models, uncovering connections across popular approaches and active research directions in this area.
Read more5/3/2024

0
Transcoders Find Interpretable LLM Feature Circuits
Jacob Dunefsky, Philippe Chlenski, Neel Nanda
A key goal in mechanistic interpretability is circuit analysis: finding sparse subgraphs of models corresponding to specific behaviors or capabilities. However, MLP sublayers make fine-grained circuit analysis on transformer-based language models difficult. In particular, interpretable features -- such as those found by sparse autoencoders (SAEs) -- are typically linear combinations of extremely many neurons, each with its own nonlinearity to account for. Circuit analysis in this setting thus either yields intractably large circuits or fails to disentangle local and global behavior. To address this we explore transcoders, which seek to faithfully approximate a densely activating MLP layer with a wider, sparsely-activating MLP layer. We successfully train transcoders on language models with 120M, 410M, and 1.4B parameters, and find them to perform at least on par with SAEs in terms of sparsity, faithfulness, and human-interpretability. We then introduce a novel method for using transcoders to perform weights-based circuit analysis through MLP sublayers. The resulting circuits neatly factorize into input-dependent and input-invariant terms. Finally, we apply transcoders to reverse-engineer unknown circuits in the model, and we obtain novel insights regarding the greater-than circuit in GPT2-small. Our results suggest that transcoders can prove effective in decomposing model computations involving MLPs into interpretable circuits. Code is available at https://github.com/jacobdunefsky/transcoder_circuits.
Read more6/19/2024