Transformers need glasses! Information over-squashing in language tasks

0
Sign in to get full access
Overview
• This paper explores the phenomenon of "information over-squashing" in language models, particularly Transformer-based models. • The authors investigate how Transformers can lose important information during the encoding and decoding process, which can degrade their performance on various language tasks. • The paper proposes a method to mitigate this issue by incorporating an additional "attention layer" that helps the model maintain more relevant information.
Plain English Explanation
Language models, like the ones used in chatbots and text generation, are powerful tools that can generate human-like text. However, these models can sometimes struggle to fully capture the nuances and context of language. This paper looks at a specific issue called "information over-squashing" that can happen in Transformer-based language models.
Transformers are a type of neural network that have become very popular for language tasks. They work by breaking down text into smaller pieces and then processing those pieces through multiple "attention" layers. The idea is that the model can focus on the most important parts of the text to generate its output.
Unfortunately, the way Transformers process information can sometimes lead to important details being "squashed" or lost in the process. This can cause the model to miss key context or make mistakes in its generated text. The researchers in this paper propose a potential solution to this problem by adding an extra "attention layer" to the Transformer architecture. This extra layer helps the model retain more of the original information, which can improve its performance on various language tasks.
The paper provides technical details on the proposed architecture and presents experiments demonstrating its effectiveness. Overall, this research highlights an important challenge in language modeling and suggests a way to address it, which could lead to more robust and capable language AI systems.
Technical Explanation
The paper explores the phenomenon of "information over-squashing" in Transformer-based language models. Transformers work by breaking down text into smaller pieces and processing them through multiple "attention" layers, which allow the model to focus on the most relevant parts of the input. However, the authors hypothesize that this process can lead to important information being lost or "squashed" during the encoding and decoding stages.
To address this issue, the researchers propose a new Transformer architecture that incorporates an additional "attention layer" between the encoder and decoder. This extra layer is designed to help the model maintain more of the original information from the input, rather than losing it as it passes through the network.
The paper presents experiments comparing the performance of the proposed architecture to standard Transformer models on a range of language tasks, including text generation, summarization, and question answering. The results demonstrate that the modified Transformer with the extra attention layer can outperform the baseline models, particularly on tasks that require preserving fine-grained details from the input.
The authors also provide an in-depth analysis of the attention patterns within the models, showing how the additional layer helps the Transformer focus on more relevant information throughout the encoding and decoding process.
Critical Analysis
The paper makes a compelling case for the issue of "information over-squashing" in Transformer-based language models and proposes a promising solution. The experimental results provide strong evidence for the effectiveness of the proposed architecture, and the attention analysis offers valuable insights into how the model is able to better preserve relevant information.
One potential limitation of the research is the scope of the language tasks evaluated. While the authors demonstrate improvements on several common benchmarks, it would be interesting to see how the modified Transformer performs on a wider range of applications, especially those that require more nuanced understanding of language and context.
Additionally, the paper does not delve into the computational and memory overhead of the extra attention layer. Depending on the target use case, the increased complexity of the model may be a concern that needs to be carefully weighed against the performance gains.
Overall, this research makes an important contribution to the understanding and improvement of Transformer-based language models. The findings suggest that addressing information loss is a critical challenge that deserves further exploration, and the proposed solution offers a compelling starting point for future work in this area.
Conclusion
This paper investigates the issue of "information over-squashing" in Transformer-based language models and presents a novel architectural modification to address it. By incorporating an additional attention layer between the encoder and decoder, the authors demonstrate that Transformers can better preserve relevant information from the input, leading to improved performance on a variety of language tasks.
The insights and techniques described in this work have the potential to enhance the capabilities of language AI systems, enabling them to better capture the nuances and contextual details that are essential for natural language understanding and generation. As the field of language modeling continues to advance, addressing challenges like information loss will be critical for developing more robust and versatile AI assistants, writing tools, and other applications that rely on human-like text processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Transformers need glasses! Information over-squashing in language tasks
Federico Barbero, Andrea Banino, Steven Kapturowski, Dharshan Kumaran, Jo~ao G. M. Ara'ujo, Alex Vitvitskyi, Razvan Pascanu, Petar Veliv{c}kovi'c
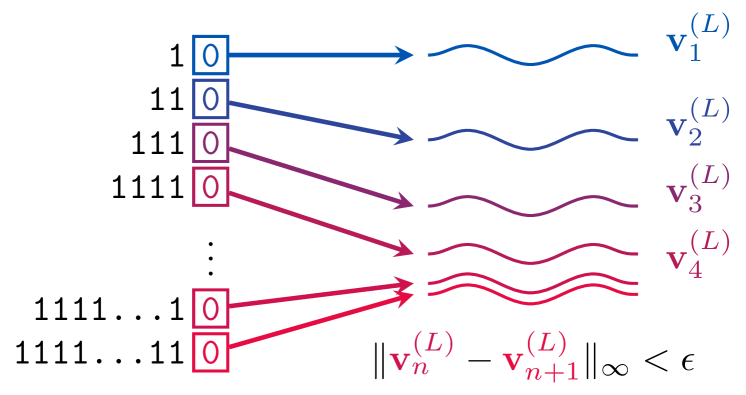
We study how information propagates in decoder-only Transformers, which are the architectural backbone of most existing frontier large language models (LLMs). We rely on a theoretical signal propagation analysis -- specifically, we analyse the representations of the last token in the final layer of the Transformer, as this is the representation used for next-token prediction. Our analysis reveals a representational collapse phenomenon: we prove that certain distinct sequences of inputs to the Transformer can yield arbitrarily close representations in the final token. This effect is exacerbated by the low-precision floating-point formats frequently used in modern LLMs. As a result, the model is provably unable to respond to these sequences in different ways -- leading to errors in, e.g., tasks involving counting or copying. Further, we show that decoder-only Transformer language models can lose sensitivity to specific tokens in the input, which relates to the well-known phenomenon of over-squashing in graph neural networks. We provide empirical evidence supporting our claims on contemporary LLMs. Our theory also points to simple solutions towards ameliorating these issues.
Read more6/7/2024
💬
0
Transformers Get Stable: An End-to-End Signal Propagation Theory for Language Models
Akhil Kedia, Mohd Abbas Zaidi, Sushil Khyalia, Jungho Jung, Harshith Goka, Haejun Lee
In spite of their huge success, transformer models remain difficult to scale in depth. In this work, we develop a unified signal propagation theory and provide formulae that govern the moments of the forward and backward signal through the transformer model. Our framework can be used to understand and mitigate vanishing/exploding gradients, rank collapse, and instability associated with high attention scores. We also propose DeepScaleLM, an initialization and scaling scheme that conserves unit output/gradient moments throughout the model, enabling the training of very deep models with 1000 layers. We find that transformer models could be much deeper - our deep models with fewer parameters outperform shallow models in Language Modeling, Speech Translation, and Image Classification, across encoder-only, decoder-only and encoder-decoder variants, for both Pre-LN and Post-LN transformers, for multiple datasets and model sizes. These improvements also translate into improved performance on downstream Question Answering tasks and improved robustness for Image Classification.
Read more7/19/2024
2
A Primer on the Inner Workings of Transformer-based Language Models
Javier Ferrando, Gabriele Sarti, Arianna Bisazza, Marta R. Costa-juss`a
The rapid progress of research aimed at interpreting the inner workings of advanced language models has highlighted a need for contextualizing the insights gained from years of work in this area. This primer provides a concise technical introduction to the current techniques used to interpret the inner workings of Transformer-based language models, focusing on the generative decoder-only architecture. We conclude by presenting a comprehensive overview of the known internal mechanisms implemented by these models, uncovering connections across popular approaches and active research directions in this area.
Read more5/3/2024
🏷️
0
Towards smallers, faster decoder-only transformers: Architectural variants and their implications
Sathya Krishnan Suresh, Shunmugapriya P
Research on Large Language Models (LLMs) has recently seen exponential growth, largely focused on transformer-based architectures, as introduced by [1] and further advanced by the decoder-only variations in [2]. Contemporary studies typically aim to improve model capabilities by increasing both the architecture's complexity and the volume of training data. However, research exploring how to reduce model sizes while maintaining performance is limited. This study introduces three modifications to the decoder-only transformer architecture: ParallelGPT (p-gpt), LinearlyCompressedGPT (lc-gpt), and ConvCompressedGPT (cc-gpt). These variants achieve comparable performance to conventional architectures in code generation tasks while benefiting from reduced model sizes and faster training times. We open-source the model weights and codebase to support future research and development in this domain.
Read more4/24/2024