Decoding Style: Efficient Fine-Tuning of LLMs for Image-Guided Outfit Recommendation with Preference

0
Sign in to get full access
Overview
- This paper presents a method for efficiently fine-tuning large language models (LLMs) for image-guided outfit recommendation with user preference feedback.
- The proposed approach, called "Decoding Style," leverages direct feedback optimization to personalize the LLM for each user's fashion preferences.
- The method aims to enable more accurate and personalized "Complete the Look" recommendations, where the model suggests items to complement a given outfit.
Plain English Explanation
The paper introduces a way to customize large language models (LLMs) to provide better outfit recommendations for individual users. LLMs are powerful AI systems that can understand and generate human language, but they are often trained on general data and may not capture each person's unique fashion preferences.
The "Decoding Style" approach allows the LLM to be efficiently fine-tuned, or adjusted, based on feedback from the user. When the user provides feedback on recommended outfits, the model can learn their personal style preferences and make more personalized suggestions in the future.
For example, if the user consistently rejects recommendations with certain color schemes or clothing styles, the model can adapt to avoid those and instead suggest items the user is more likely to enjoy. This "Complete the Look" functionality aims to help users find outfits they'll love by leveraging the user's own preferences.
Technical Explanation
The paper proposes a method called "Decoding Style" that enables efficient fine-tuning of LLMs for image-guided outfit recommendation with user preference feedback. The key components are:
-
Fine-Tuning with Direct Feedback Optimization: The LLM is fine-tuned using a direct feedback optimization approach, where the model parameters are updated to maximize the likelihood of the user's preferred items in the recommended outfits.
-
Personalized Recommendation: The fine-tuned LLM is used to generate "Complete the Look" recommendations, where the model suggests items to complement a given outfit in a personalized way for each user.
-
Multimodal Representation Learning: The model learns a joint representation of images and text, allowing it to reason about fashion items and outfits in a multimodal way.
The authors evaluate their approach on a large-scale fashion dataset and demonstrate that "Decoding Style" can efficiently fine-tune LLMs to provide more accurate and personalized outfit recommendations compared to baseline methods.
Critical Analysis
The paper presents a novel and promising approach for personalizing LLMs for fashion recommendation tasks. However, some potential limitations and areas for further research are:
-
Generalization to New Users: The paper focuses on fine-tuning the LLM for individual users, but it's unclear how well the model would generalize to new users with different fashion preferences.
-
Scalability: The fine-tuning process may be computationally intensive, and it's important to consider the scalability of the approach as the number of users grows.
-
Interpretability: The paper does not provide much insight into the specific fashion-related knowledge the LLM learns during fine-tuning. Improving the interpretability of the model's decision-making could be valuable.
-
Ethical Considerations: Personalized recommendation systems can raise privacy and fairness concerns, which the paper does not address in depth. Careful consideration of these issues is crucial for real-world deployment.
Conclusion
This paper presents an innovative approach, "Decoding Style," for efficiently fine-tuning LLMs to provide personalized and accurate outfit recommendations. By leveraging direct feedback optimization, the method allows the LLM to adapt to each user's unique fashion preferences, enabling more "Complete the Look" recommendations that users are likely to enjoy.
The technical insights and experimental results suggest that this approach could have significant implications for the development of advanced fashion recommendation systems, which could in turn enhance the shopping experience for consumers. However, further research is needed to address potential limitations and ensure the responsible development of such systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Decoding Style: Efficient Fine-Tuning of LLMs for Image-Guided Outfit Recommendation with Preference
Najmeh Forouzandehmehr, Nima Farrokhsiar, Ramin Giahi, Evren Korpeoglu, Kannan Achan
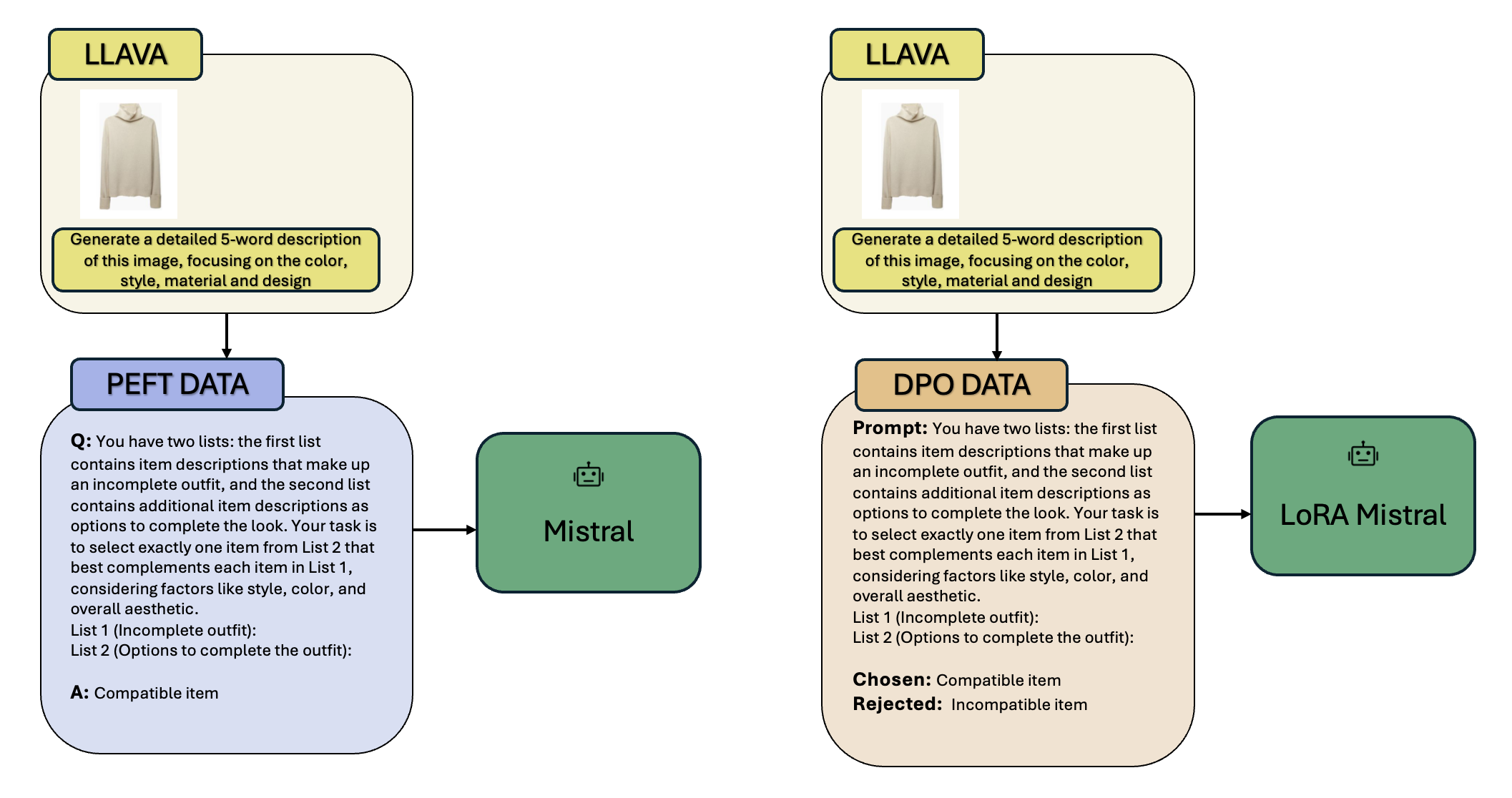
Personalized outfit recommendation remains a complex challenge, demanding both fashion compatibility understanding and trend awareness. This paper presents a novel framework that harnesses the expressive power of large language models (LLMs) for this task, mitigating their black box and static nature through fine-tuning and direct feedback integration. We bridge the item visual-textual gap in items descriptions by employing image captioning with a Multimodal Large Language Model (MLLM). This enables the LLM to extract style and color characteristics from human-curated fashion images, forming the basis for personalized recommendations. The LLM is efficiently fine-tuned on the open-source Polyvore dataset of curated fashion images, optimizing its ability to recommend stylish outfits. A direct preference mechanism using negative examples is employed to enhance the LLM's decision-making process. This creates a self-enhancing AI feedback loop that continuously refines recommendations in line with seasonal fashion trends. Our framework is evaluated on the Polyvore dataset, demonstrating its effectiveness in two key tasks: fill-in-the-blank, and complementary item retrieval. These evaluations underline the framework's ability to generate stylish, trend-aligned outfit suggestions, continuously improving through direct feedback. The evaluation results demonstrated that our proposed framework significantly outperforms the base LLM, creating more cohesive outfits. The improved performance in these tasks underscores the proposed framework's potential to enhance the shopping experience with accurate suggestions, proving its effectiveness over the vanilla LLM based outfit generation.
Read more9/19/2024
0
NoteLLM-2: Multimodal Large Representation Models for Recommendation
Chao Zhang, Haoxin Zhang, Shiwei Wu, Di Wu, Tong Xu, Yan Gao, Yao Hu, Enhong Chen
Large Language Models (LLMs) have demonstrated exceptional text understanding. Existing works explore their application in text embedding tasks. However, there are few works utilizing LLMs to assist multimodal representation tasks. In this work, we investigate the potential of LLMs to enhance multimodal representation in multimodal item-to-item (I2I) recommendations. One feasible method is the transfer of Multimodal Large Language Models (MLLMs) for representation tasks. However, pre-training MLLMs usually requires collecting high-quality, web-scale multimodal data, resulting in complex training procedures and high costs. This leads the community to rely heavily on open-source MLLMs, hindering customized training for representation scenarios. Therefore, we aim to design an end-to-end training method that customizes the integration of any existing LLMs and vision encoders to construct efficient multimodal representation models. Preliminary experiments show that fine-tuned LLMs in this end-to-end method tend to overlook image content. To overcome this challenge, we propose a novel training framework, NoteLLM-2, specifically designed for multimodal representation. We propose two ways to enhance the focus on visual information. The first method is based on the prompt viewpoint, which separates multimodal content into visual content and textual content. NoteLLM-2 adopts the multimodal In-Content Learning method to teach LLMs to focus on both modalities and aggregate key information. The second method is from the model architecture, utilizing a late fusion mechanism to directly fuse visual information into textual information. Extensive experiments have been conducted to validate the effectiveness of our method.
Read more5/28/2024

0
Harnessing Multimodal Large Language Models for Multimodal Sequential Recommendation
Yuyang Ye, Zhi Zheng, Yishan Shen, Tianshu Wang, Hengruo Zhang, Peijun Zhu, Runlong Yu, Kai Zhang, Hui Xiong
Recent advances in Large Language Models (LLMs) have demonstrated significant potential in the field of Recommendation Systems (RSs). Most existing studies have focused on converting user behavior logs into textual prompts and leveraging techniques such as prompt tuning to enable LLMs for recommendation tasks. Meanwhile, research interest has recently grown in multimodal recommendation systems that integrate data from images, text, and other sources using modality fusion techniques. This introduces new challenges to the existing LLM-based recommendation paradigm which relies solely on text modality information. Moreover, although Multimodal Large Language Models (MLLMs) capable of processing multi-modal inputs have emerged, how to equip MLLMs with multi-modal recommendation capabilities remains largely unexplored. To this end, in this paper, we propose the Multimodal Large Language Model-enhanced Multimodaln Sequential Recommendation (MLLM-MSR) model. To capture the dynamic user preference, we design a two-stage user preference summarization method. Specifically, we first utilize an MLLM-based item-summarizer to extract image feature given an item and convert the image into text. Then, we employ a recurrent user preference summarization generation paradigm to capture the dynamic changes in user preferences based on an LLM-based user-summarizer. Finally, to enable the MLLM for multi-modal recommendation task, we propose to fine-tune a MLLM-based recommender using Supervised Fine-Tuning (SFT) techniques. Extensive evaluations across various datasets validate the effectiveness of MLLM-MSR, showcasing its superior ability to capture and adapt to the evolving dynamics of user preferences.
Read more9/30/2024
💬
0
Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application
Jian Jia, Yipei Wang, Yan Li, Honggang Chen, Xuehan Bai, Zhaocheng Liu, Jian Liang, Quan Chen, Han Li, Peng Jiang, Kun Gai
Contemporary recommender systems predominantly rely on collaborative filtering techniques, employing ID-embedding to capture latent associations among users and items. However, this approach overlooks the wealth of semantic information embedded within textual descriptions of items, leading to suboptimal performance in cold-start scenarios and long-tail user recommendations. Leveraging the capabilities of Large Language Models (LLMs) pretrained on massive text corpus presents a promising avenue for enhancing recommender systems by integrating open-world domain knowledge. In this paper, we propose an Llm-driven knowlEdge Adaptive RecommeNdation (LEARN) framework that synergizes open-world knowledge with collaborative knowledge. We address computational complexity concerns by utilizing pretrained LLMs as item encoders and freezing LLM parameters to avoid catastrophic forgetting and preserve open-world knowledge. To bridge the gap between the open-world and collaborative domains, we design a twin-tower structure supervised by the recommendation task and tailored for practical industrial application. Through offline experiments on the large-scale industrial dataset and online experiments on A/B tests, we demonstrate the efficacy of our approach.
Read more5/8/2024