Harnessing Multimodal Large Language Models for Multimodal Sequential Recommendation

0

Sign in to get full access
Overview
- Examines the use of multimodal large language models (LLMs) for multimodal sequential recommendation
- Proposes a framework called NoteLLM-2 that leverages LLMs to capture cross-modal relationships and user preferences
- Conducts experiments on various benchmarks to demonstrate the effectiveness of the proposed approach
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. Researchers have explored using LLMs for sequential recommendation, where the goal is to suggest the next item a user might want based on their past interactions.
This paper takes the idea a step further by using multimodal LLMs, which can process not just text, but also other data like images and videos. The researchers developed a framework called NoteLLM-2 that allows these multimodal LLMs to capture the relationships between different types of content and user preferences.
The key idea is to use the LLM to understand the context and content of the items a user interacts with, and then leverage that understanding to make more personalized recommendations as the user's interests evolve over time. For example, if a user consistently engages with cooking-related content, the system can pick up on that and suggest related recipes, kitchen gadgets, or cooking shows.
The researchers evaluated their approach on various benchmarks and found that it outperformed other state-of-the-art methods for multimodal sequential recommendation. This suggests that harnessing the power of multimodal LLMs can be a promising direction for building more intelligent and personalized recommendation systems.
Technical Explanation
The paper proposes a framework called NoteLLM-2 that leverages multimodal large language models (LLMs) for multimodal sequential recommendation. The core idea is to use the LLM to capture the cross-modal relationships between different types of content (e.g., text, images, videos) as well as the user's evolving preferences over time.
The framework consists of three key components:
- Multimodal Feature Extraction: The LLM is used to extract features from the various modalities (text, images, etc.) associated with each item in the recommendation system.
- Cross-Modal Fusion: The extracted features are then combined using a cross-modal fusion module to capture the relationships between the different modalities.
- Sequence Modeling: The fused features are then fed into a sequence modeling module (e.g., transformer) to capture the user's evolving preferences over time.
The researchers conducted experiments on several benchmark datasets and compared their approach to other state-of-the-art methods for multimodal sequential recommendation. The results showed that NoteLLM-2 outperformed the baselines, demonstrating the effectiveness of leveraging multimodal LLMs for this task.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed NoteLLM-2 framework. The authors acknowledge some potential limitations, such as the computational complexity of using large language models and the need to explore alternative fusion and sequence modeling techniques.
One area that could be further explored is the interpretability of the model's recommendations. While the LLM-based approach may lead to improved performance, it can also make the decision-making process more opaque. Investigating ways to increase the transparency and explainability of the recommendations could be a valuable direction for future research.
Additionally, the paper focuses on evaluating the framework on standard benchmark datasets. It would be interesting to see how NoteLLM-2 performs in real-world, deployed recommendation systems, where the data and user interactions may be more complex and noisy.
Conclusion
This paper demonstrates the potential of using multimodal large language models for multimodal sequential recommendation. The proposed NoteLLM-2 framework leverages the rich, cross-modal understanding of LLMs to capture user preferences and make more personalized recommendations as the user's interests evolve over time.
The promising results suggest that harnessing the power of multimodal LLMs could be a fruitful direction for building more intelligent and effective recommendation systems. As the field of large language models continues to advance, integrating these powerful AI systems into recommendation workflows could lead to significant improvements in user experience and engagement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Harnessing Multimodal Large Language Models for Multimodal Sequential Recommendation
Yuyang Ye, Zhi Zheng, Yishan Shen, Tianshu Wang, Hengruo Zhang, Peijun Zhu, Runlong Yu, Kai Zhang, Hui Xiong
Recent advances in Large Language Models (LLMs) have demonstrated significant potential in the field of Recommendation Systems (RSs). Most existing studies have focused on converting user behavior logs into textual prompts and leveraging techniques such as prompt tuning to enable LLMs for recommendation tasks. Meanwhile, research interest has recently grown in multimodal recommendation systems that integrate data from images, text, and other sources using modality fusion techniques. This introduces new challenges to the existing LLM-based recommendation paradigm which relies solely on text modality information. Moreover, although Multimodal Large Language Models (MLLMs) capable of processing multi-modal inputs have emerged, how to equip MLLMs with multi-modal recommendation capabilities remains largely unexplored. To this end, in this paper, we propose the Multimodal Large Language Model-enhanced Multimodaln Sequential Recommendation (MLLM-MSR) model. To capture the dynamic user preference, we design a two-stage user preference summarization method. Specifically, we first utilize an MLLM-based item-summarizer to extract image feature given an item and convert the image into text. Then, we employ a recurrent user preference summarization generation paradigm to capture the dynamic changes in user preferences based on an LLM-based user-summarizer. Finally, to enable the MLLM for multi-modal recommendation task, we propose to fine-tune a MLLM-based recommender using Supervised Fine-Tuning (SFT) techniques. Extensive evaluations across various datasets validate the effectiveness of MLLM-MSR, showcasing its superior ability to capture and adapt to the evolving dynamics of user preferences.
Read more8/21/2024
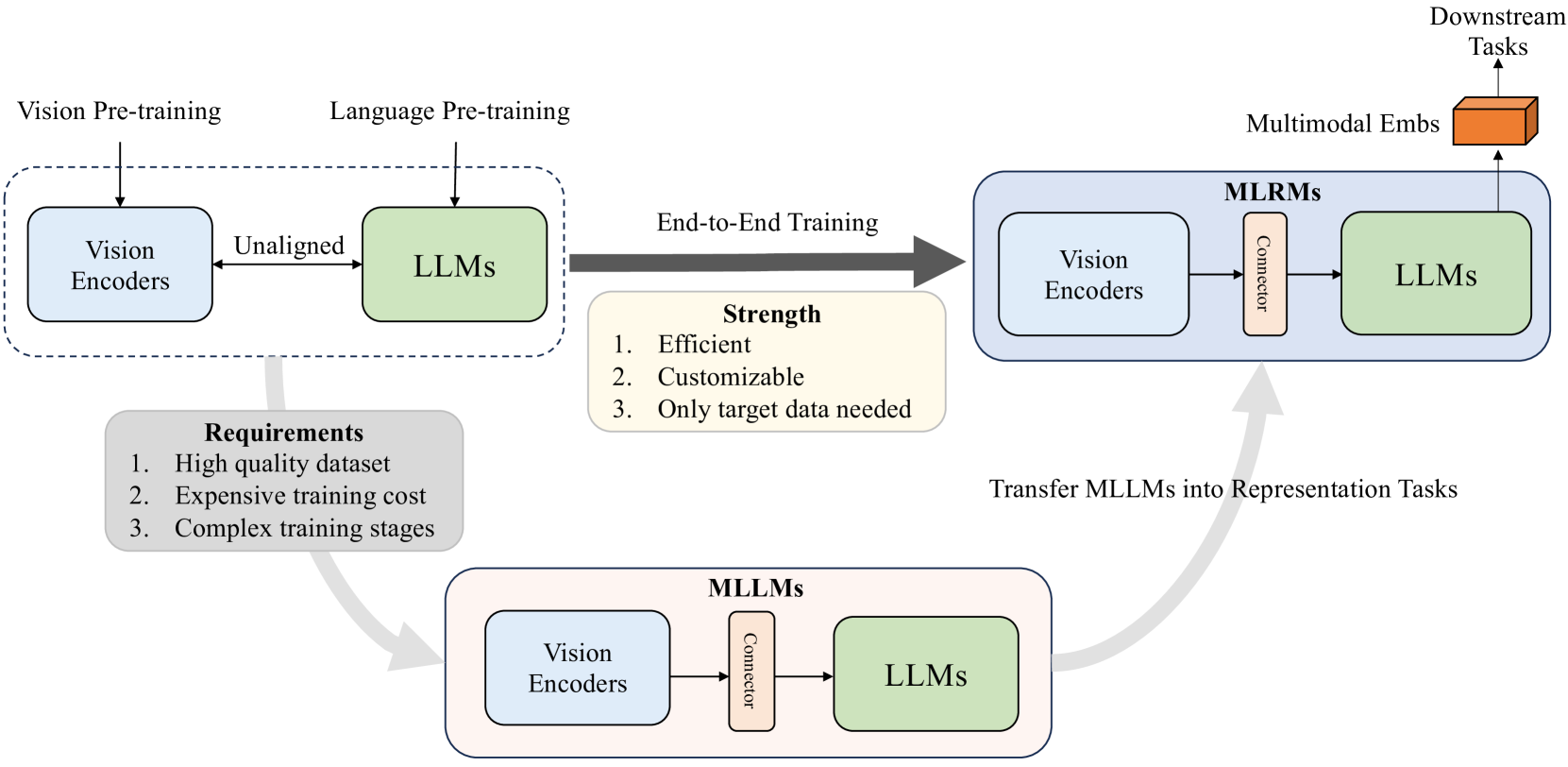
0
NoteLLM-2: Multimodal Large Representation Models for Recommendation
Chao Zhang, Haoxin Zhang, Shiwei Wu, Di Wu, Tong Xu, Yan Gao, Yao Hu, Enhong Chen
Large Language Models (LLMs) have demonstrated exceptional text understanding. Existing works explore their application in text embedding tasks. However, there are few works utilizing LLMs to assist multimodal representation tasks. In this work, we investigate the potential of LLMs to enhance multimodal representation in multimodal item-to-item (I2I) recommendations. One feasible method is the transfer of Multimodal Large Language Models (MLLMs) for representation tasks. However, pre-training MLLMs usually requires collecting high-quality, web-scale multimodal data, resulting in complex training procedures and high costs. This leads the community to rely heavily on open-source MLLMs, hindering customized training for representation scenarios. Therefore, we aim to design an end-to-end training method that customizes the integration of any existing LLMs and vision encoders to construct efficient multimodal representation models. Preliminary experiments show that fine-tuned LLMs in this end-to-end method tend to overlook image content. To overcome this challenge, we propose a novel training framework, NoteLLM-2, specifically designed for multimodal representation. We propose two ways to enhance the focus on visual information. The first method is based on the prompt viewpoint, which separates multimodal content into visual content and textual content. NoteLLM-2 adopts the multimodal In-Content Learning method to teach LLMs to focus on both modalities and aggregate key information. The second method is from the model architecture, utilizing a late fusion mechanism to directly fuse visual information into textual information. Extensive experiments have been conducted to validate the effectiveness of our method.
Read more5/28/2024
💬
1
A Survey on Large Language Models for Recommendation
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, Enhong Chen
Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.
Read more6/19/2024
💬
0
Large Language Models Enhanced Sequential Recommendation for Long-tail User and Item
Qidong Liu, Xian Wu, Xiangyu Zhao, Yejing Wang, Zijian Zhang, Feng Tian, Yefeng Zheng
Sequential recommendation systems (SRS) serve the purpose of predicting users' subsequent preferences based on their past interactions and have been applied across various domains such as e-commerce and social networking platforms. However, practical SRS encounters challenges due to the fact that most users engage with only a limited number of items, while the majority of items are seldom consumed. These challenges, termed as the long-tail user and long-tail item dilemmas, often create obstacles for traditional SRS methods. Mitigating these challenges is crucial as they can significantly impact user satisfaction and business profitability. While some research endeavors have alleviated these issues, they still grapple with issues such as seesaw or noise stemming from the scarcity of interactions. The emergence of large language models (LLMs) presents a promising avenue to address these challenges from a semantic standpoint. In this study, we introduce the Large Language Models Enhancement framework for Sequential Recommendation (LLM-ESR), which leverages semantic embeddings from LLMs to enhance SRS performance without increasing computational overhead. To combat the long-tail item challenge, we propose a dual-view modeling approach that fuses semantic information from LLMs with collaborative signals from traditional SRS. To address the long-tail user challenge, we introduce a retrieval augmented self-distillation technique to refine user preference representations by incorporating richer interaction data from similar users. Through comprehensive experiments conducted on three authentic datasets using three widely used SRS models, our proposed enhancement framework demonstrates superior performance compared to existing methodologies.
Read more6/3/2024