Decomposing and Interpreting Image Representations via Text in ViTs Beyond CLIP

0
Sign in to get full access
Overview
• This paper proposes a new approach for decomposing and interpreting image representations in Vision Transformers (ViTs) beyond the CLIP model.
• The researchers develop techniques to better understand how ViTs process and represent images using text-based probing.
• The findings offer insights into the inner workings of ViTs and suggest ways to improve their interpretability and performance, particularly on tasks involving text-heavy content.
Plain English Explanation
Vision Transformers (ViTs) are a type of deep learning model that are used to process and understand images. They work by breaking an image down into smaller pieces, called "patches," and then processing those patches through a series of layers to generate a representation of the entire image.
However, it can be challenging to understand exactly how ViTs arrive at their representations of images. This paper proposes a new approach for "decomposing" and "interpreting" the representations that ViTs generate, using text-based probing techniques.
The researchers develop methods to better understand which parts of an image ViTs focus on and how they relate those image parts to textual concepts. This provides valuable insights into the inner workings of ViTs and suggests ways to improve their interpretability and performance, especially on tasks involving text-heavy content.
For example, the paper shows how ViTs can sometimes misinterpret the meaning of text in an image, and proposes ways to refine their text understanding capabilities. [internal link: https://aimodels.fyi/papers/arxiv/refining-skewed-perceptions-vision-language-models-through]
Overall, this research represents an important step forward in making ViTs and other complex vision models more transparent and understandable. By shedding light on how these models process and represent images, it opens the door to further advancements in [internal link: https://aimodels.fyi/papers/arxiv/enhancing-vision-models-text-heavy-content-understanding] and [internal link: https://aimodels.fyi/papers/arxiv/llm-based-hierarchical-concept-decomposition-interpretable-fine] vision-language AI.
Technical Explanation
The paper introduces a new approach for decomposing and interpreting the image representations learned by Vision Transformers (ViTs). The key technical contributions include:
-
Text-based Probing: The researchers develop techniques to probe the internal representations of ViTs using textual concepts. This allows them to understand which parts of an image the model is focusing on and how it associates those image regions with specific textual descriptions.
-
Concept Decomposition: The paper presents a method for hierarchically decomposing the learned image representations into progressively more fine-grained textual concepts. This provides a detailed, interpretable account of how ViTs process images. [internal link: https://aimodels.fyi/papers/arxiv/llm-based-hierarchical-concept-decomposition-interpretable-fine]
-
Performance Evaluation: The researchers evaluate their proposed techniques on a variety of vision-language tasks, including image classification and captioning. They demonstrate that the interpretability insights can be used to refine and improve ViT performance, especially on text-heavy content. [internal link: https://aimodels.fyi/papers/arxiv/vitamin-designing-scalable-vision-models-vision-language]
-
Model Comparisons: The paper compares the interpretability of ViTs to that of the CLIP model, a prominent vision-language system. The findings suggest that ViTs offer advantages in terms of their ability to decompose and explain their image representations.
Overall, this work provides a valuable new toolkit for understanding and enhancing the inner workings of ViTs, with applications in areas such as [internal link: https://aimodels.fyi/papers/arxiv/interpreting-clips-image-representation-via-text-based] and [internal link: https://aimodels.fyi/papers/arxiv/refining-skewed-perceptions-vision-language-models-through] vision-language AI.
Critical Analysis
The paper presents a compelling approach for decomposing and interpreting ViT representations, but it also acknowledges several important caveats and limitations:
-
Generalization Concerns: While the techniques demonstrate strong performance on the evaluated tasks, the researchers note that the interpretability insights may not generalize well to more complex or diverse datasets and real-world applications.
-
Computational Overhead: The hierarchical concept decomposition process can be computationally intensive, potentially limiting its scalability to larger models and datasets.
-
Alignment with Human Reasoning: The paper discusses the challenge of ensuring that the decomposed textual concepts truly align with human intuitions and reasoning about image content.
-
Potential Biases: As with any machine learning model, the ViTs studied may exhibit biases and blindspots in their understanding of images, which could be difficult to fully capture and address through the proposed interpretability techniques.
-
Dependence on Text Corpora: The effectiveness of the text-based probing methods relies heavily on the quality and coverage of the textual corpora used to train the language models. Limitations in these resources could constrain the interpretability insights.
Overall, the paper represents an important step forward in the quest for more transparent and interpretable vision-language AI systems. However, the researchers acknowledge that further work is needed to address the limitations and fully unlock the potential of these techniques in real-world applications.
Conclusion
This paper presents a novel approach for decomposing and interpreting the internal representations of Vision Transformers (ViTs) using text-based probing techniques. The proposed methods provide valuable insights into how ViTs process and understand images, with potential applications in improving their interpretability and performance, particularly on tasks involving text-heavy content.
The key takeaways from this research include:
-
The development of techniques to probe ViT representations using textual concepts, enabling a more granular understanding of their image processing mechanisms.
-
A hierarchical concept decomposition method that offers a detailed, interpretable account of how ViTs associate image regions with textual descriptions.
-
Empirical demonstrations of how the interpretability insights can be leveraged to refine ViT performance on vision-language tasks.
-
A comparative analysis that highlights the advantages of ViTs over the CLIP model in terms of their ability to decompose and explain their image representations.
While the paper acknowledges several important limitations and caveats, it represents a significant advancement in the quest for more transparent and explainable vision-language AI systems. By shedding light on the inner workings of ViTs, this research paves the way for further innovations in [internal link: https://aimodels.fyi/papers/arxiv/enhancing-vision-models-text-heavy-content-understanding] and [internal link: https://aimodels.fyi/papers/arxiv/llm-based-hierarchical-concept-decomposition-interpretable-fine] that could have far-reaching implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Decomposing and Interpreting Image Representations via Text in ViTs Beyond CLIP
Sriram Balasubramanian, Samyadeep Basu, Soheil Feizi
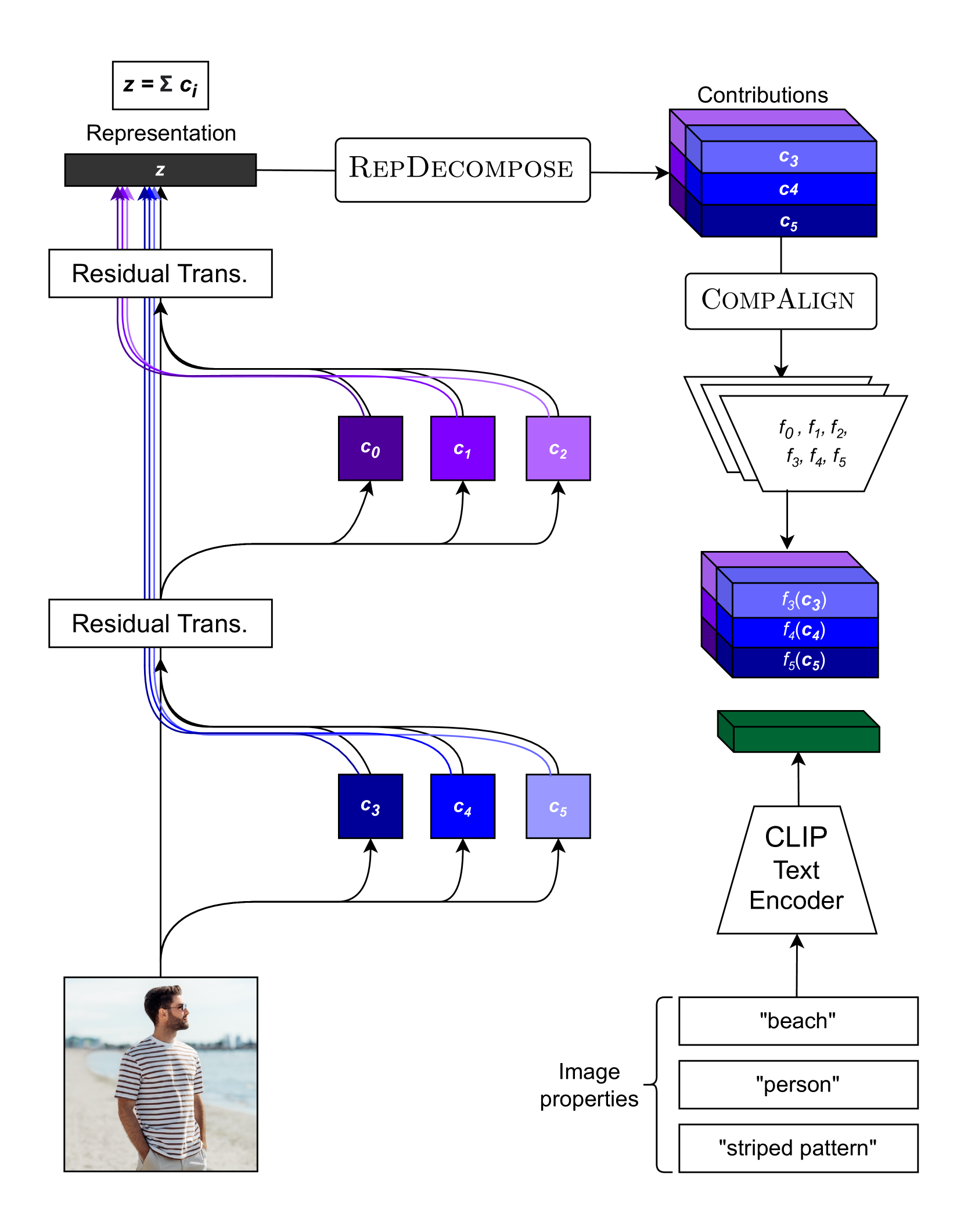
Recent works have explored how individual components of the CLIP-ViT model contribute to the final representation by leveraging the shared image-text representation space of CLIP. These components, such as attention heads and MLPs, have been shown to capture distinct image features like shape, color or texture. However, understanding the role of these components in arbitrary vision transformers (ViTs) is challenging. To this end, we introduce a general framework which can identify the roles of various components in ViTs beyond CLIP. Specifically, we (a) automate the decomposition of the final representation into contributions from different model components, and (b) linearly map these contributions to CLIP space to interpret them via text. Additionally, we introduce a novel scoring function to rank components by their importance with respect to specific features. Applying our framework to various ViT variants (e.g. DeiT, DINO, DINOv2, Swin, MaxViT), we gain insights into the roles of different components concerning particular image features.These insights facilitate applications such as image retrieval using text descriptions or reference images, visualizing token importance heatmaps, and mitigating spurious correlations.
Read more6/4/2024

0
Interpreting CLIP's Image Representation via Text-Based Decomposition
Yossi Gandelsman, Alexei A. Efros, Jacob Steinhardt
We investigate the CLIP image encoder by analyzing how individual model components affect the final representation. We decompose the image representation as a sum across individual image patches, model layers, and attention heads, and use CLIP's text representation to interpret the summands. Interpreting the attention heads, we characterize each head's role by automatically finding text representations that span its output space, which reveals property-specific roles for many heads (e.g. location or shape). Next, interpreting the image patches, we uncover an emergent spatial localization within CLIP. Finally, we use this understanding to remove spurious features from CLIP and to create a strong zero-shot image segmenter. Our results indicate that a scalable understanding of transformer models is attainable and can be used to repair and improve models.
Read more4/1/2024
🔍
0
Refining Skewed Perceptions in Vision-Language Models through Visual Representations
Haocheng Dai, Sarang Joshi
Large vision-language models (VLMs), such as CLIP, have become foundational, demonstrating remarkable success across a variety of downstream tasks. Despite their advantages, these models, akin to other foundational systems, inherit biases from the disproportionate distribution of real-world data, leading to misconceptions about the actual environment. Prevalent datasets like ImageNet are often riddled with non-causal, spurious correlations that can diminish VLM performance in scenarios where these contextual elements are absent. This study presents an investigation into how a simple linear probe can effectively distill task-specific core features from CLIP's embedding for downstream applications. Our analysis reveals that the CLIP text representations are often tainted by spurious correlations, inherited in the biased pre-training dataset. Empirical evidence suggests that relying on visual representations from CLIP, as opposed to text embedding, is more practical to refine the skewed perceptions in VLMs, emphasizing the superior utility of visual representations in overcoming embedded biases. Our codes will be available here.
Read more5/24/2024
👀
0
Enhancing Vision Models for Text-Heavy Content Understanding and Interaction
Adithya TG, Adithya SK, Abhinav R Bharadwaj, Abhiram HA, Dr. Surabhi Narayan
Interacting and understanding with text heavy visual content with multiple images is a major challenge for traditional vision models. This paper is on enhancing vision models' capability to comprehend or understand and learn from images containing a huge amount of textual information from the likes of textbooks and research papers which contain multiple images like graphs, etc and tables in them with different types of axes and scales. The approach involves dataset preprocessing, fine tuning which is by using instructional oriented data and evaluation. We also built a visual chat application integrating CLIP for image encoding and a model from the Massive Text Embedding Benchmark which is developed to consider both textual and visual inputs. An accuracy of 96.71% was obtained. The aim of the project is to increase and also enhance the advance vision models' capabilities in understanding complex visual textual data interconnected data, contributing to multimodal AI.
Read more6/3/2024