Enhancing Vision Models for Text-Heavy Content Understanding and Interaction
2405.20906
0
0
👀
Abstract
Interacting and understanding with text heavy visual content with multiple images is a major challenge for traditional vision models. This paper is on enhancing vision models' capability to comprehend or understand and learn from images containing a huge amount of textual information from the likes of textbooks and research papers which contain multiple images like graphs, etc and tables in them with different types of axes and scales. The approach involves dataset preprocessing, fine tuning which is by using instructional oriented data and evaluation. We also built a visual chat application integrating CLIP for image encoding and a model from the Massive Text Embedding Benchmark which is developed to consider both textual and visual inputs. An accuracy of 96.71% was obtained. The aim of the project is to increase and also enhance the advance vision models' capabilities in understanding complex visual textual data interconnected data, contributing to multimodal AI.
Create account to get full access
Overview
- This paper explores how to enhance vision models' ability to understand and learn from images containing a large amount of textual information, such as those found in textbooks and research papers.
- The approach involves dataset preprocessing, fine-tuning using instructional data, and evaluation.
- The researchers also built a visual chat application that integrates CLIP for image encoding and a model from the Massive Text Embedding Benchmark to handle both textual and visual inputs.
- The goal is to increase and enhance advanced vision models' capabilities in understanding complex, interconnected visual-textual data, contributing to the development of multimodal AI.
Plain English Explanation
Traditional vision models often struggle to comprehend images that contain a significant amount of textual information, such as those found in textbooks and research papers. These types of images often include various elements like graphs, tables with different axes and scales, and other complex visual-textual content.
To address this challenge, the researchers in this paper developed an approach to enhance vision models' ability to understand and learn from these types of images. They first preprocessed the dataset, then fine-tuned the models using instructional data. This helped the models better grasp the relationship between the textual and visual elements in the images.
The researchers also built a visual chat application that integrates CLIP, a powerful image encoding model, with a model from the Massive Text Embedding Benchmark. This allows the application to handle both textual and visual inputs, enabling more natural and intuitive interactions.
The goal of this work is to significantly improve the capabilities of advanced vision models in understanding and making sense of complex, interconnected visual-textual data. This is an important step towards developing more robust and versatile multimodal AI systems that can better understand and interact with the world around them.
Technical Explanation
The key elements of this paper include:
-
Dataset Preprocessing: The researchers preprocessed the dataset to ensure the vision models could effectively handle the textual and visual information in the images.
-
Fine-Tuning with Instructional Data: The models were fine-tuned using instructional-oriented data, which helped them learn to better understand the relationship between the textual and visual elements in the images.
-
Evaluation: The researchers evaluated the performance of their approach, achieving an accuracy of 96.71%.
-
Visual Chat Application: The researchers built a visual chat application that integrates CLIP for image encoding and a model from the Massive Text Embedding Benchmark to handle both textual and visual inputs.
The key insights from this research include the importance of dataset preprocessing and fine-tuning for enhancing vision models' understanding of complex visual-textual data. The development of the visual chat application demonstrates the practical applications of this approach in building more natural and intuitive multimodal AI systems.
Critical Analysis
The paper acknowledges the limitations of traditional vision models in comprehending images with a high volume of textual information. However, the researchers do not provide detailed information about the specific challenges or failure modes of these models when faced with such complex visual-textual data.
While the proposed approach achieves a high accuracy of 96.71%, the researchers do not discuss the potential biases or generalization issues that may arise when applying the model to a wider range of visual-textual content. Further research could explore the model's performance on more diverse datasets or in real-world applications.
Additionally, the paper does not delve into the computational and resource requirements of the fine-tuning process or the visual chat application. This information could be valuable for researchers and practitioners interested in implementing similar approaches in their own work.
Overall, the research presented in this paper represents a significant step forward in enhancing vision models' capabilities in understanding complex, interconnected visual-textual data. Future studies could build on these findings to further explore the challenges and opportunities in developing more robust and versatile multimodal AI systems.
Conclusion
This paper addresses a critical challenge in the field of computer vision: the ability of traditional vision models to comprehend images containing a significant amount of textual information, such as those found in textbooks and research papers. The researchers developed an approach that involves dataset preprocessing, fine-tuning with instructional data, and the creation of a visual chat application that integrates CLIP and a model from the Massive Text Embedding Benchmark.
The key contribution of this work is the substantial improvement in vision models' understanding of complex, interconnected visual-textual data. This advancement represents an important step towards the development of more robust and versatile multimodal AI systems that can better interact with and make sense of the world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
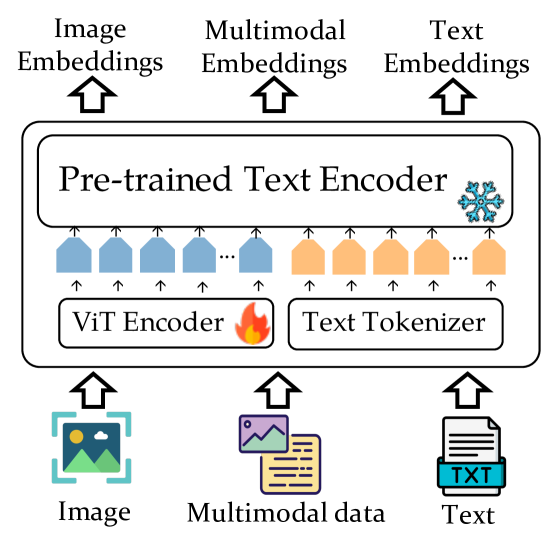
VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval
Junjie Zhou, Zheng Liu, Shitao Xiao, Bo Zhao, Yongping Xiong
0
0
Multi-modal retrieval becomes increasingly popular in practice. However, the existing retrievers are mostly text-oriented, which lack the capability to process visual information. Despite the presence of vision-language models like CLIP, the current methods are severely limited in representing the text-only and image-only data. In this work, we present a new embedding model VISTA for universal multi-modal retrieval. Our work brings forth threefold technical contributions. Firstly, we introduce a flexible architecture which extends a powerful text encoder with the image understanding capability by introducing visual token embeddings. Secondly, we develop two data generation strategies, which bring high-quality composed image-text to facilitate the training of the embedding model. Thirdly, we introduce a multi-stage training algorithm, which first aligns the visual token embedding with the text encoder using massive weakly labeled data, and then develops multi-modal representation capability using the generated composed image-text data. In our experiments, VISTA achieves superior performances across a variety of multi-modal retrieval tasks in both zero-shot and supervised settings. Our model, data, and source code are available at https://github.com/FlagOpen/FlagEmbedding.
6/7/2024
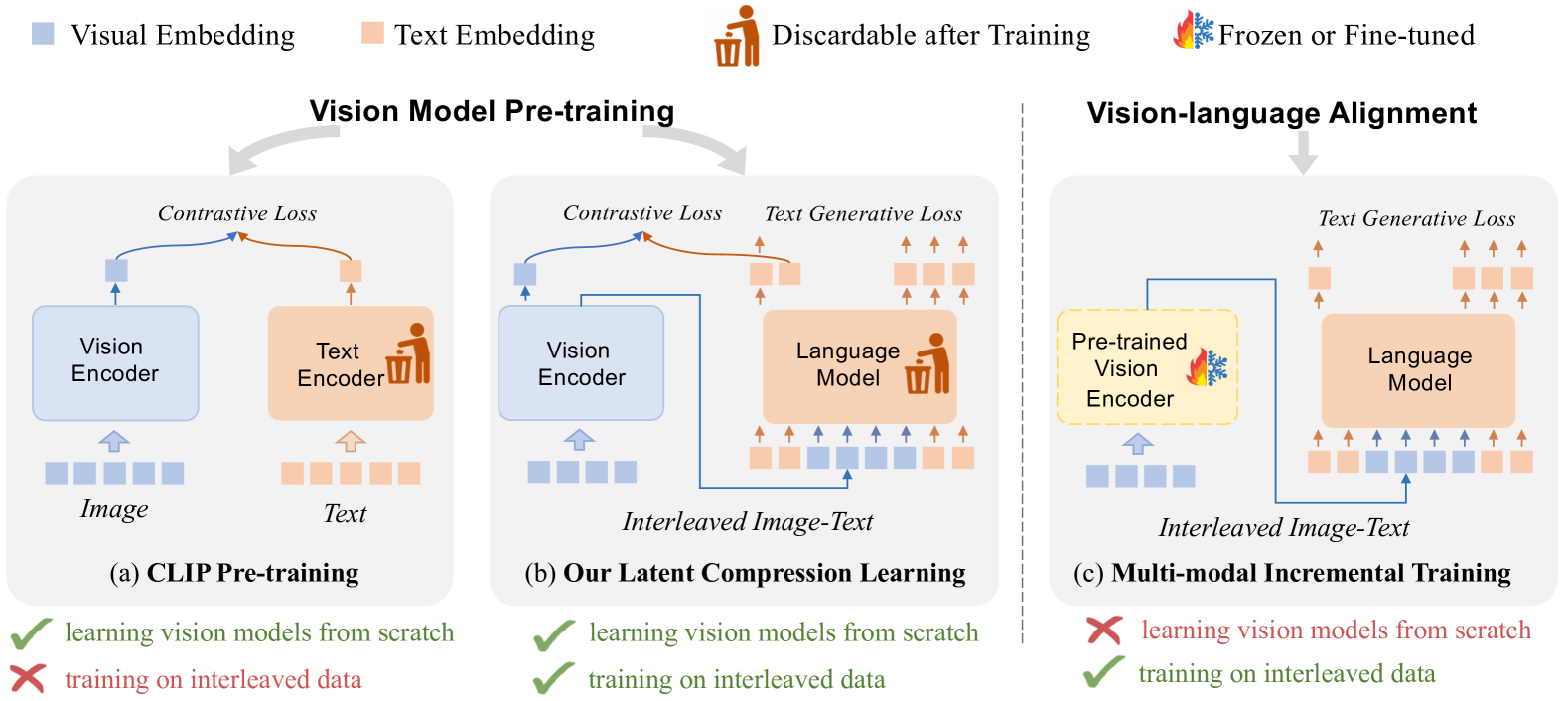
Vision Model Pre-training on Interleaved Image-Text Data via Latent Compression Learning
Chenyu Yang, Xizhou Zhu, Jinguo Zhu, Weijie Su, Junjie Wang, Xuan Dong, Wenhai Wang, Lewei Lu, Bin Li, Jie Zhou, Yu Qiao, Jifeng Dai
0
0
Recently, vision model pre-training has evolved from relying on manually annotated datasets to leveraging large-scale, web-crawled image-text data. Despite these advances, there is no pre-training method that effectively exploits the interleaved image-text data, which is very prevalent on the Internet. Inspired by the recent success of compression learning in natural language processing, we propose a novel vision model pre-training method called Latent Compression Learning (LCL) for interleaved image-text data. This method performs latent compression learning by maximizing the mutual information between the inputs and outputs of a causal attention model. The training objective can be decomposed into two basic tasks: 1) contrastive learning between visual representation and preceding context, and 2) generating subsequent text based on visual representation. Our experiments demonstrate that our method not only matches the performance of CLIP on paired pre-training datasets (e.g., LAION), but can also leverage interleaved pre-training data (e.g., MMC4) to learn robust visual representation from scratch, showcasing the potential of vision model pre-training with interleaved image-text data. Code is released at https://github.com/OpenGVLab/LCL.
6/12/2024
🤿
Advanced Multimodal Deep Learning Architecture for Image-Text Matching
Jinyin Wang, Haijing Zhang, Yihao Zhong, Yingbin Liang, Rongwei Ji, Yiru Cang
0
0
Image-text matching is a key multimodal task that aims to model the semantic association between images and text as a matching relationship. With the advent of the multimedia information age, image, and text data show explosive growth, and how to accurately realize the efficient and accurate semantic correspondence between them has become the core issue of common concern in academia and industry. In this study, we delve into the limitations of current multimodal deep learning models in processing image-text pairing tasks. Therefore, we innovatively design an advanced multimodal deep learning architecture, which combines the high-level abstract representation ability of deep neural networks for visual information with the advantages of natural language processing models for text semantic understanding. By introducing a novel cross-modal attention mechanism and hierarchical feature fusion strategy, the model achieves deep fusion and two-way interaction between image and text feature space. In addition, we also optimize the training objectives and loss functions to ensure that the model can better map the potential association structure between images and text during the learning process. Experiments show that compared with existing image-text matching models, the optimized new model has significantly improved performance on a series of benchmark data sets. In addition, the new model also shows excellent generalization and robustness on large and diverse open scenario datasets and can maintain high matching performance even in the face of previously unseen complex situations.
6/24/2024
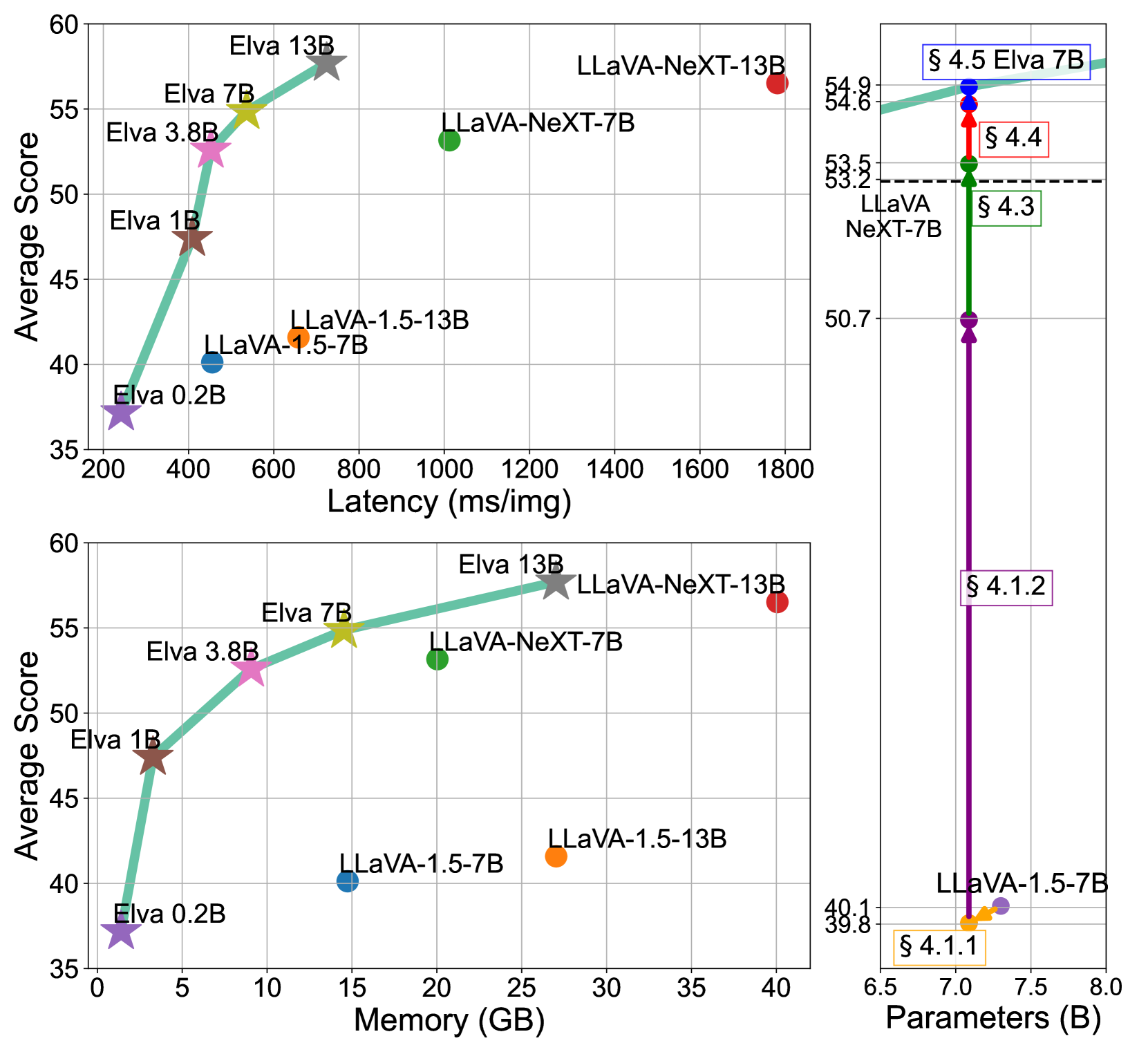
On Efficient Language and Vision Assistants for Visually-Situated Natural Language Understanding: What Matters in Reading and Reasoning
Geewook Kim, Minjoon Seo
0
0
Recent advancements in language and vision assistants have showcased impressive capabilities but suffer from a lack of transparency, limiting broader research and reproducibility. While open-source models handle general image tasks effectively, they face challenges with the high computational demands of complex visually-situated text understanding. Such tasks often require increased token inputs and large vision modules to harness high-resolution information. Striking a balance between model size and data importance remains an open question. This study aims to redefine the design of vision-language models by identifying key components and creating efficient models with constrained inference costs. By strategically formulating datasets, optimizing vision modules, and enhancing supervision techniques, we achieve significant improvements in inference throughput while maintaining high performance. Extensive experiments across models ranging from 160M to 13B parameters offer insights into model optimization. We will fully open-source our codebase, models, and datasets at https://github.com/naver-ai/elva .
6/18/2024