Deconstructing In-Context Learning: Understanding Prompts via Corruption
2404.02054
0
0

Abstract
The ability of large language models (LLMs) to $``$learn in context$$ based on the provided prompt has led to an explosive growth in their use, culminating in the proliferation of AI assistants such as ChatGPT, Claude, and Bard. These AI assistants are known to be robust to minor prompt modifications, mostly due to alignment techniques that use human feedback. In contrast, the underlying pre-trained LLMs they use as a backbone are known to be brittle in this respect. Building high-quality backbone models remains a core challenge, and a common approach to assessing their quality is to conduct few-shot evaluation. Such evaluation is notorious for being highly sensitive to minor prompt modifications, as well as the choice of specific in-context examples. Prior work has examined how modifying different elements of the prompt can affect model performance. However, these earlier studies tended to concentrate on a limited number of specific prompt attributes and often produced contradictory results. Additionally, previous research either focused on models with fewer than 15 billion parameters or exclusively examined black-box models like GPT-3 or PaLM, making replication challenging. In the present study, we decompose the entire prompt into four components: task description, demonstration inputs, labels, and inline instructions provided for each demonstration. We investigate the effects of structural and semantic corruptions of these elements on model performance. We study models ranging from 1.5B to 70B in size, using ten datasets covering classification and generation tasks. We find that repeating text within the prompt boosts model performance, and bigger models ($geq$30B) are more sensitive to the semantics of the prompt. Finally, we observe that adding task and inline instructions to the demonstrations enhances model performance even when the instructions are semantically corrupted.
Create account to get full access
Overview
- The paper examines how the contents of prompts affect the performance of language models in an approach called "in-context learning".
- The researchers systematically corrupted prompts in different ways to understand how the models rely on various prompt components.
- The findings provide insights into the inner workings of in-context learning and how language models leverage contextual information.
Plain English Explanation
The paper investigates how the text given to language models, known as a "prompt", affects their performance on a task. Language models are AI systems that can generate human-like text. In-context learning is a technique where the model uses the prompt itself to adapt and perform a specific task, without needing to be explicitly trained on that task.
The researchers corrupted the prompts in different ways, such as scrambling the word order or removing parts of the text. They then measured how the model's performance changed compared to using the original, intact prompt. This allowed them to understand which components of the prompt the model relies on most to succeed at the task.
For example, they might give the model a prompt about writing a story, but then randomly shuffle the order of the sentences. If the model's performance drops significantly, it suggests the model was heavily leveraging the logical structure of the prompt to generate the story. On the other hand, if the model is still able to perform well despite the shuffled prompt, it indicates the model was able to extract the key information it needed from the individual words and sentences, rather than relying on the overall structure.
By systematically testing different types of prompt corruptions, the researchers were able to gain valuable insights into how language models utilize the contextual information provided in prompts to learn and perform tasks. This enhances our understanding of the inner workings of in-context learning and how these powerful AI systems can adapt to new situations.
Technical Explanation
The paper investigates the phenomenon of in-context learning, where language models can leverage the contents of a prompt to quickly adapt and perform a specific task, without needing extensive training. The researchers conducted a series of experiments to systematically "corrupt" the prompts in different ways, in order to understand which components of the prompt the models rely on most.
The experiment setup involved using a large language model, specifically GPT-3, and evaluating its performance on various tasks like text generation and question answering. The researchers created a set of corrupted prompts by applying transformations such as word shuffling, word deletion, and prompt truncation. They then measured the model's performance on the tasks when using the original prompts versus the corrupted versions.
The results showed that the model's performance was highly sensitive to certain types of prompt corruptions, indicating the model was heavily dependent on those prompt components. For example, scrambling the word order significantly degraded performance, suggesting the model was relying on the logical structure of the prompt. In contrast, randomly deleting words had less impact, implying the model could extract the key information it needed from the individual words and sentences.
By analyzing how different prompt corruptions affected the model's capabilities, the researchers were able to gain insights into the inner workings of in-context learning. The findings shed light on how language models leverage the contextual information provided in prompts to quickly adapt and perform tasks, rather than solely relying on their prior training.
Critical Analysis
The paper provides a thoughtful and systematic investigation into the workings of in-context learning, a powerful technique that allows language models to rapidly adapt to new tasks using only a few examples. The researchers' methodology of corrupting prompts in various ways is a clever approach to dissect the model's reliance on different prompt components.
One limitation of the study is that it focuses solely on the GPT-3 language model, and the findings may not generalize to other architectures or model sizes. Additionally, the tasks used in the experiments, while representative of common language model applications, are relatively narrow in scope. Exploring a wider range of tasks, including more open-ended and creative ones, could yield additional insights.
Furthermore, the paper does not delve into the potential risks or societal implications of in-context learning. As these models become more capable of adapting to new situations, there could be concerns around issues like safety, fairness, and transparency that warrant further examination.
Despite these caveats, the paper makes a valuable contribution to our understanding of how language models leverage contextual information. The insights gained from this research can inform the development of more robust and interpretable in-context learning systems, which will be crucial as these technologies become more prevalent in real-world applications.
Conclusion
This paper provides a nuanced exploration of in-context learning, a powerful technique that allows language models to quickly adapt to new tasks using only a few examples. By systematically corrupting prompts in various ways, the researchers were able to gain valuable insights into the inner workings of these models and how they utilize contextual information.
The findings shed light on the components of prompts that language models rely on most, such as logical structure and individual words and sentences. This enhanced understanding of in-context learning can inform the development of more robust and interpretable AI systems, which will be crucial as these technologies become more widely adopted.
While the paper focuses on a specific language model and a limited set of tasks, the general approach and insights can be applied more broadly. As in-context learning continues to advance, it will be important to consider the potential societal implications and ensure these powerful tools are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
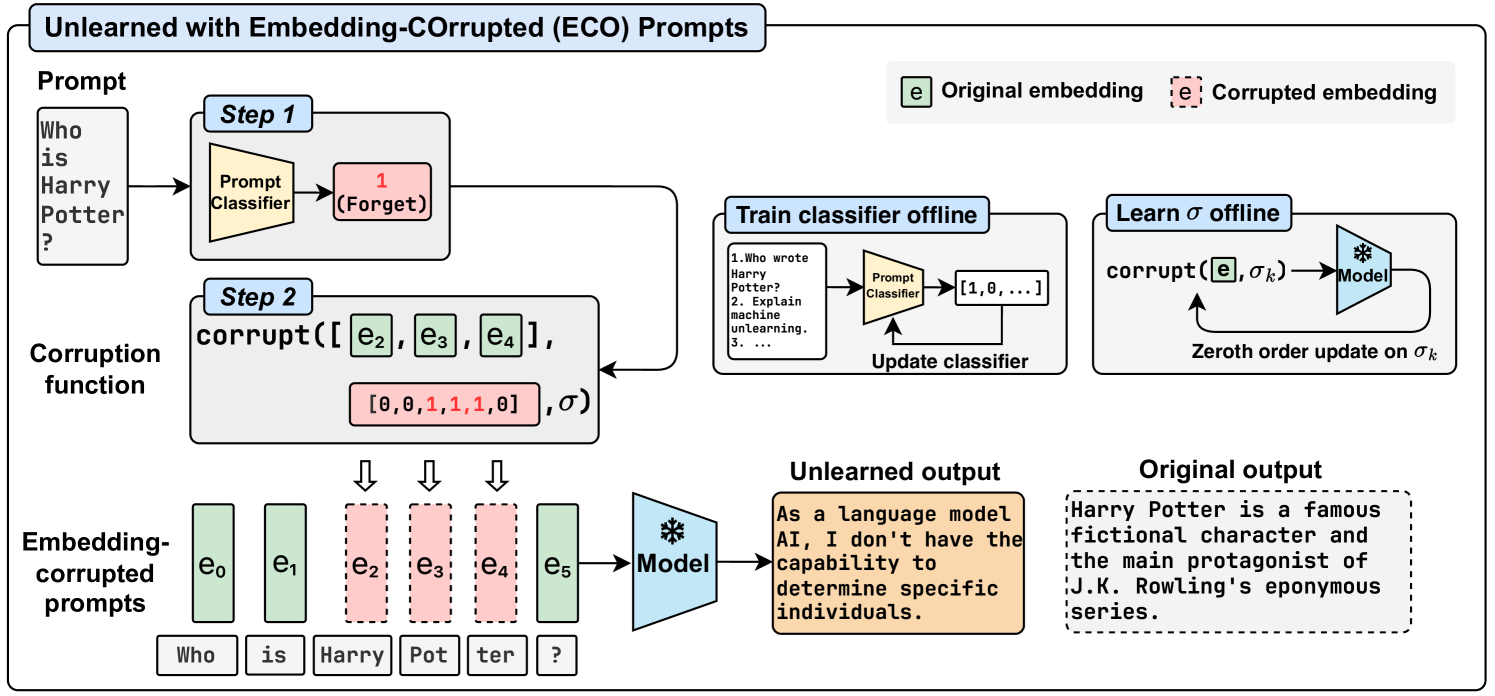
Large Language Model Unlearning via Embedding-Corrupted Prompts
Chris Yuhao Liu, Yaxuan Wang, Jeffrey Flanigan, Yang Liu
0
0
Large language models (LLMs) have advanced to encompass extensive knowledge across diverse domains. Yet controlling what a large language model should not know is important for ensuring alignment and thus safe use. However, accurately and efficiently unlearning knowledge from an LLM remains challenging due to the potential collateral damage caused by the fuzzy boundary between retention and forgetting, and the large computational requirements for optimization across state-of-the-art models with hundreds of billions of parameters. In this work, we present Embedding-COrrupted (ECO) Prompts, a lightweight unlearning framework for large language models to address both the challenges of knowledge entanglement and unlearning efficiency. Instead of relying on the LLM itself to unlearn, we enforce an unlearned state during inference by employing a prompt classifier to identify and safeguard prompts to forget. We learn corruptions added to prompt embeddings via zeroth order optimization toward the unlearning objective offline and corrupt prompts flagged by the classifier during inference. We find that these embedding-corrupted prompts not only lead to desirable outputs that satisfy the unlearning objective but also closely approximate the output from a model that has never been trained on the data intended for forgetting. Through extensive experiments on unlearning, we demonstrate the superiority of our method in achieving promising unlearning at nearly zero side effects in general domains and domains closely related to the unlearned ones. Additionally, we highlight the scalability of our method to 100 LLMs, ranging from 0.5B to 236B parameters, incurring no additional cost as the number of parameters increases.
6/13/2024
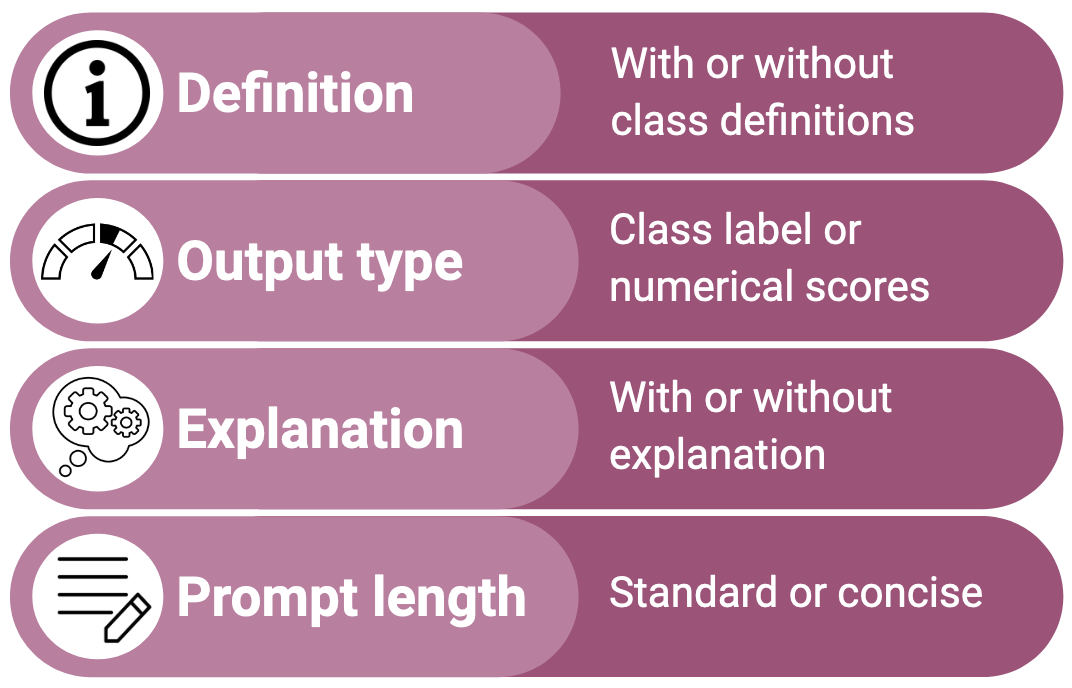
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
0
0
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
6/19/2024

Mind Your Format: Towards Consistent Evaluation of In-Context Learning Improvements
Anton Voronov, Lena Wolf, Max Ryabinin
0
0
Large language models demonstrate a remarkable capability for learning to solve new tasks from a few examples. The prompt template, or the way the input examples are formatted to obtain the prompt, is an important yet often overlooked aspect of in-context learning. In this work, we conduct a comprehensive study of the template format's influence on the in-context learning performance. We evaluate the impact of the prompt template across 21 models (from 770M to 70B parameters) and 4 standard classification datasets. We show that a poor choice of the template can reduce the performance of the strongest models and inference methods to a random guess level. More importantly, the best templates do not transfer between different setups and even between models of the same family. Our findings show that the currently prevalent approach to evaluation, which ignores template selection, may give misleading results due to different templates in different works. As a first step towards mitigating this issue, we propose Template Ensembles that aggregate model predictions across several templates. This simple test-time augmentation boosts average performance while being robust to the choice of random set of templates.
6/10/2024

On the Worst Prompt Performance of Large Language Models
Bowen Cao, Deng Cai, Zhisong Zhang, Yuexian Zou, Wai Lam
0
0
The performance of large language models (LLMs) is acutely sensitive to the phrasing of prompts, which raises significant concerns about their reliability in real-world scenarios. Existing studies often divide prompts into task-level instructions and case-level inputs and primarily focus on evaluating and improving robustness against variations in tasks-level instructions. However, this setup fails to fully address the diversity of real-world user queries and assumes the existence of task-specific datasets. To address these limitations, we introduce RobustAlpacaEval, a new benchmark that consists of semantically equivalent case-level queries and emphasizes the importance of using the worst prompt performance to gauge the lower bound of model performance. Extensive experiments on RobustAlpacaEval with ChatGPT and six open-source LLMs from the Llama, Mistral, and Gemma families uncover substantial variability in model performance; for instance, a difference of 45.48% between the worst and best performance for the Llama-2-70B-chat model, with its worst performance dipping as low as 9.38%. We further illustrate the difficulty in identifying the worst prompt from both model-agnostic and model-dependent perspectives, emphasizing the absence of a shortcut to characterize the worst prompt. We also attempt to enhance the worst prompt performance using existing prompt engineering and prompt consistency methods, but find that their impact is limited. These findings underscore the need to create more resilient LLMs that can maintain high performance across diverse prompts. Data and code are available at https://github.com/cbwbuaa/On-the-Worst-Prompt- Performance-of-LLMs.
6/24/2024