Decouple Graph Neural Networks: Train Multiple Simple GNNs Simultaneously Instead of One
2304.10126
0
0
🧠
Abstract
Graph neural networks (GNN) suffer from severe inefficiency. It is mainly caused by the exponential growth of node dependency with the increase of layers. It extremely limits the application of stochastic optimization algorithms so that the training of GNN is usually time-consuming. To address this problem, we propose to decouple a multi-layer GNN as multiple simple modules for more efficient training, which is comprised of classical forward training (FT)and designed backward training (BT). Under the proposed framework, each module can be trained efficiently in FT by stochastic algorithms without distortion of graph information owing to its simplicity. To avoid the only unidirectional information delivery of FT and sufficiently train shallow modules with the deeper ones, we develop a backward training mechanism that makes the former modules perceive the latter modules. The backward training introduces the reversed information delivery into the decoupled modules as well as the forward information delivery. To investigate how the decoupling and greedy training affect the representational capacity, we theoretically prove that the error produced by linear modules will not accumulate on unsupervised tasks in most cases. The theoretical and experimental results show that the proposed framework is highly efficient with reasonable performance.
Create account to get full access
Overview
- Graph neural networks (GNNs) suffer from severe inefficiency due to exponential growth of node dependency with increasing layers
- This limits the use of stochastic optimization algorithms, making GNN training time-consuming
- The proposed framework decouples a multi-layer GNN into multiple simple modules for more efficient training
Plain English Explanation
Graph neural networks (GNNs) are a type of machine learning model that operate on graph-structured data, like social networks or transportation networks. However, GNNs have a major problem - as you add more "layers" to the model, the amount of information it needs to keep track of grows exponentially. This makes the models very slow to train, especially when using common optimization techniques like stochastic gradient descent.
To address this issue, the researchers propose a new way to train GNNs. Instead of training the whole model at once, they split it into smaller, simpler "modules" that can be trained more efficiently. Each module only has to learn a small part of the overall task, so it doesn't get bogged down by the exponential complexity.
The key innovation is that they don't just train these modules one after the other in a straight line. They also develop a "backward training" process where the later, deeper modules provide feedback to the earlier, shallower modules. This helps the shallow modules learn better, without losing the benefits of the modular, efficient training approach.
Technical Explanation
The proposed framework decouples a multi-layer GNN model into multiple simple modules, each of which can be trained efficiently using stochastic optimization algorithms. This is achieved through a two-part training process:
-
Forward Training (FT): Each module is trained independently in a forward direction, leveraging the simplicity of the individual modules to enable efficient training using stochastic methods without distorting the underlying graph information.
-
Backward Training (BT): To address the unidirectional information flow of FT and to sufficiently train the shallower modules, the researchers develop a backward training mechanism. This introduces reversed information delivery between the modules, allowing the shallower modules to perceive and learn from the deeper modules.
To analyze the impact of this decoupling and greedy training approach on the model's representational capacity, the paper provides a theoretical analysis. It proves that in most cases, the error produced by the linear modules will not accumulate on unsupervised tasks.
The proposed framework is shown to be highly efficient in training GNNs, while maintaining reasonable performance. This addresses the key challenge of the exponential growth of node dependency that limits the use of stochastic optimization in traditional GNN training.
Critical Analysis
The paper presents a novel and promising approach to training GNNs more efficiently. The key strength is the modular training framework, which avoids the exponential complexity issues that plague traditional GNN training. The backward training mechanism is also an interesting innovation to better integrate the different modules.
However, the paper does not extensively explore the limitations or potential drawbacks of this approach. For example, it is unclear how well the framework would scale to very large or complex graphs, or how it would perform on supervised tasks compared to end-to-end GNN training.
Additionally, the theoretical analysis focuses on unsupervised tasks, leaving open questions about the model's representational capacity and error accumulation for supervised learning scenarios. Further research may be needed to fully understand the tradeoffs and boundaries of this decoupled training approach.
Overall, the proposed framework represents a valuable contribution to improving the efficiency of GNN training, but there is still room for deeper exploration of its capabilities and limitations.
Conclusion
This paper introduces an efficient training framework for graph neural networks that decouples the model into simpler, modular components. By breaking down the exponential complexity of traditional GNN training, the framework enables the use of stochastic optimization algorithms, making the training process much faster.
The key innovations are the forward and backward training mechanisms, which allow the individual modules to be trained efficiently while still maintaining the representational capacity of the overall model. This addresses a critical limitation of GNNs and opens up new possibilities for applying these powerful machine learning models to a wider range of real-world problems, from binary programming to temporal graph estimation.
While the paper provides a solid theoretical and experimental foundation, further research is needed to fully understand the limitations and boundary conditions of this decoupled training approach. Nevertheless, this work represents an important step forward in making graph neural networks more practical and accessible for a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
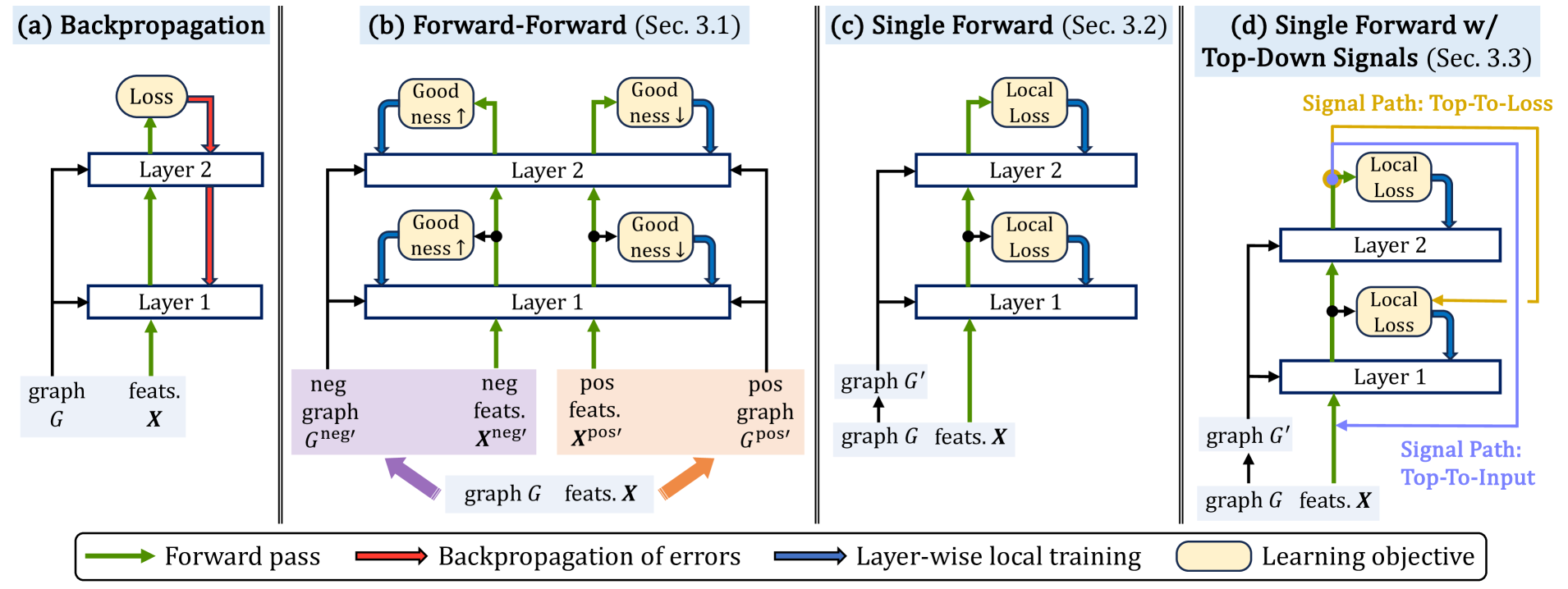
Forward Learning of Graph Neural Networks
Namyong Park, Xing Wang, Antoine Simoulin, Shuai Yang, Grey Yang, Ryan Rossi, Puja Trivedi, Nesreen Ahmed
0
0
Graph neural networks (GNNs) have achieved remarkable success across a wide range of applications, such as recommendation, drug discovery, and question answering. Behind the success of GNNs lies the backpropagation (BP) algorithm, which is the de facto standard for training deep neural networks (NNs). However, despite its effectiveness, BP imposes several constraints, which are not only biologically implausible, but also limit the scalability, parallelism, and flexibility in learning NNs. Examples of such constraints include storage of neural activities computed in the forward pass for use in the subsequent backward pass, and the dependence of parameter updates on non-local signals. To address these limitations, the forward-forward algorithm (FF) was recently proposed as an alternative to BP in the image classification domain, which trains NNs by performing two forward passes over positive and negative data. Inspired by this advance, we propose ForwardGNN in this work, a new forward learning procedure for GNNs, which avoids the constraints imposed by BP via an effective layer-wise local forward training. ForwardGNN extends the original FF to deal with graph data and GNNs, and makes it possible to operate without generating negative inputs (hence no longer forward-forward). Further, ForwardGNN enables each layer to learn from both the bottom-up and top-down signals without relying on the backpropagation of errors. Extensive experiments on real-world datasets show the effectiveness and generality of the proposed forward graph learning framework. We release our code at https://github.com/facebookresearch/forwardgnn.
4/16/2024
📶
Leveraging Temporal Graph Networks Using Module Decoupling
Or Feldman, Chaim Baskin
0
0
Modern approaches for learning on dynamic graphs have adopted the use of batches instead of applying updates one by one. The use of batches allows these techniques to become helpful in streaming scenarios where updates to graphs are received at extreme speeds. Using batches, however, forces the models to update infrequently, which results in the degradation of their performance. In this work, we suggest a decoupling strategy that enables the models to update frequently while using batches. By decoupling the core modules of temporal graph networks and implementing them using a minimal number of learnable parameters, we have developed the Lightweight Decoupled Temporal Graph Network (LDTGN), an exceptionally efficient model for learning on dynamic graphs. LDTG was validated on various dynamic graph benchmarks, providing comparable or state-of-the-art results with significantly higher throughput than previous art. Notably, our method outperforms previous approaches by more than 20% on benchmarks that require rapid model update rates, such as USLegis or UNTrade. The code to reproduce our experiments is available at href{https://orfeld415.github.io/module-decoupling}{this http url}.
6/7/2024
🧠
Unleash Graph Neural Networks from Heavy Tuning
Lequan Lin, Dai Shi, Andi Han, Zhiyong Wang, Junbin Gao
0
0
Graph Neural Networks (GNNs) are deep-learning architectures designed for graph-type data, where understanding relationships among individual observations is crucial. However, achieving promising GNN performance, especially on unseen data, requires comprehensive hyperparameter tuning and meticulous training. Unfortunately, these processes come with high computational costs and significant human effort. Additionally, conventional searching algorithms such as grid search may result in overfitting on validation data, diminishing generalization accuracy. To tackle these challenges, we propose a graph conditional latent diffusion framework (GNN-Diff) to generate high-performing GNNs directly by learning from checkpoints saved during a light-tuning coarse search. Our method: (1) unleashes GNN training from heavy tuning and complex search space design; (2) produces GNN parameters that outperform those obtained through comprehensive grid search; and (3) establishes higher-quality generation for GNNs compared to diffusion frameworks designed for general neural networks.
5/22/2024
🧠
New!Graph in Graph Neural Network
Jiongshu Wang, Jing Yang, Jiankang Deng, Hatice Gunes, Siyang Song
0
0
Existing Graph Neural Networks (GNNs) are limited to process graphs each of whose vertices is represented by a vector or a single value, limited their representing capability to describe complex objects. In this paper, we propose the first GNN (called Graph in Graph Neural (GIG) Network) which can process graph-style data (called GIG sample) whose vertices are further represented by graphs. Given a set of graphs or a data sample whose components can be represented by a set of graphs (called multi-graph data sample), our GIG network starts with a GIG sample generation (GSG) module which encodes the input as a textbf{GIG sample}, where each GIG vertex includes a graph. Then, a set of GIG hidden layers are stacked, with each consisting of: (1) a GIG vertex-level updating (GVU) module that individually updates the graph in every GIG vertex based on its internal information; and (2) a global-level GIG sample updating (GGU) module that updates graphs in all GIG vertices based on their relationships, making the updated GIG vertices become global context-aware. This way, both internal cues within the graph contained in each GIG vertex and the relationships among GIG vertices could be utilized for down-stream tasks. Experimental results demonstrate that our GIG network generalizes well for not only various generic graph analysis tasks but also real-world multi-graph data analysis (e.g., human skeleton video-based action recognition), which achieved the new state-of-the-art results on 13 out of 14 evaluated datasets. Our code is publicly available at https://github.com/wangjs96/Graph-in-Graph-Neural-Network.
7/2/2024