Deduplicator: When Computation Reuse Meets Load Balancing at the Network Edge

0

Sign in to get full access
Overview
- Deduplicator is a system that aims to improve the efficiency of edge computing by leveraging computation reuse and load balancing.
- It focuses on addressing the challenges of repeated computations and uneven resource utilization at the network edge.
- The paper presents the design, implementation, and evaluation of Deduplicator, demonstrating its benefits in reducing computational overhead and improving overall performance.
Plain English Explanation
Deduplicator is a technology that can make edge computing more efficient. Edge computing refers to processing data closer to the devices that generate it, rather than sending it all the way back to a central server. This can be more efficient, but it also presents some challenges.
One challenge is that the same computations may need to be performed repeatedly, which can waste resources. Deduplicator addresses this by keeping track of computations that have been done before and reusing them when possible, rather than redoing the work.
Another challenge is that the load (the amount of work) on different edge devices can be uneven, with some devices being overloaded while others sit idle. Deduplicator helps balance the load by directing computations to the devices that are best able to handle them.
By addressing these challenges, Deduplicator can make edge computing more efficient and effective, potentially leading to faster response times, lower costs, and reduced energy consumption.
Technical Explanation
Deduplicator operates by maintaining a central cache of previously computed results, which it can use to serve requests without needing to perform the computation again. When a new request comes in, Deduplicator first checks the cache to see if the result is already available. If so, it can simply return the cached result, saving the computational effort.
If the result is not in the cache, Deduplicator must decide which edge device should perform the computation. It does this by considering the current load on each device and selecting the one that is best able to handle the new task. This load balancing helps to ensure that the computational resources at the edge are used efficiently, without any devices becoming overloaded.
The paper describes the design and implementation of Deduplicator, as well as the results of experiments that evaluate its performance. The experiments show that Deduplicator can significantly reduce the computational overhead and improve the overall performance of edge computing applications, compared to approaches that do not leverage computation reuse and load balancing.
Critical Analysis
The paper provides a thorough description of the Deduplicator system and presents convincing experimental results to support its efficacy. However, there are a few potential limitations and areas for further research that could be considered:
-
The paper focuses on a specific set of edge computing use cases and workloads. It would be valuable to understand how well Deduplicator would perform in a broader range of scenarios, such as edge computing for autonomous vehicles or load balancing in distributed systems.
-
The paper does not discuss the potential impact of caching strategies or scheduling algorithms on Deduplicator's performance. These factors could be important in real-world deployments.
-
The authors mention that Deduplicator relies on a centralized cache and load balancing mechanism, which could introduce a single point of failure or scalability concerns. Exploring decentralized approaches may be a fruitful area for future research.
Overall, the Deduplicator system presents a promising approach to improving the efficiency of edge computing, and the paper provides a solid foundation for further developments in this area.
Conclusion
Deduplicator is a novel system that addresses two key challenges in edge computing: the repetition of computations and the uneven distribution of computational load across edge devices. By leveraging computation reuse and intelligent load balancing, Deduplicator can significantly improve the efficiency and performance of edge computing applications.
The paper's experimental results demonstrate the benefits of the Deduplicator approach, showing reductions in computational overhead and enhancements to overall system performance. While the paper focuses on a specific set of use cases, the underlying principles of Deduplicator could have broader applicability in the field of edge computing and distributed systems.
As the demand for edge computing continues to grow, solutions like Deduplicator will play an increasingly important role in ensuring that computational resources are utilized efficiently and effectively at the network edge. This research represents an important step forward in realizing the full potential of edge computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deduplicator: When Computation Reuse Meets Load Balancing at the Network Edge
Md Washik Al Azad, Spyridon Mastorakis
Load balancing has been a fundamental building block of cloud and, more recently, edge computing environments. At the same time, in edge computing environments, prior research has highlighted that applications operate on similar (correlated) data. Based on this observation, prior research has advocated for the direction of computation reuse, where the results of previously executed computational tasks are stored at the edge and are reused (if possible) to satisfy incoming tasks with similar input data, instead of executing incoming tasks from scratch. Both load balancing and computation reuse are critical to the deployment of scalable edge computing environments, yet they are contradictory in nature. In this paper, we propose the Deduplicator, a middlebox that aims to facilitate both load balancing and computation reuse at the edge. The Deduplicator features mechanisms to identify and deduplicate similar tasks offloaded by user devices, collect information about the usage of edge servers' resources, manage the addition of new edge servers and the failures of existing edge servers, and ultimately balance the load imposed on edge servers. Our evaluation results demonstrate that the Deduplicator achieves up to 20% higher percentages of computation reuse compared to several other load balancing approaches, while also effectively balancing the distribution of tasks among edge servers at line rate.
Read more5/7/2024

0
ReStorEdge: An edge computing system with reuse semantics
Adrian-Cristian Nicolaescu (University College London), Spyridon Mastorakis (University of Notre Dame), Md Washik Al Azad (University of Notre Dame), David Griffin (University College London), Miguel Rio (University College London)
This paper investigates an edge computing system where requests are processed by a set of replicated edge servers. We investigate a class of applications where similar queries produce identical results. To reduce processing overhead on the edge servers we store the results of previous computations and return them when new queries are sufficiently similar to earlier ones that produced the results, avoiding the necessity of processing every new query. We implement a similarity-based data classification system, which we evaluate based on real-world datasets of images and voice queries. We evaluate a range of orchestration strategies to distribute queries and cached results between edge nodes and show that the throughput of queries over a system of distributed edge nodes can be increased by 25-33%, increasing its capacity for higher workloads.
Read more5/29/2024
0
Decentralized Task Offloading and Load-Balancing for Mobile Edge Computing in Dense Networks
Mariam Yahya, Alexander Conzelmann, Setareh Maghsudi
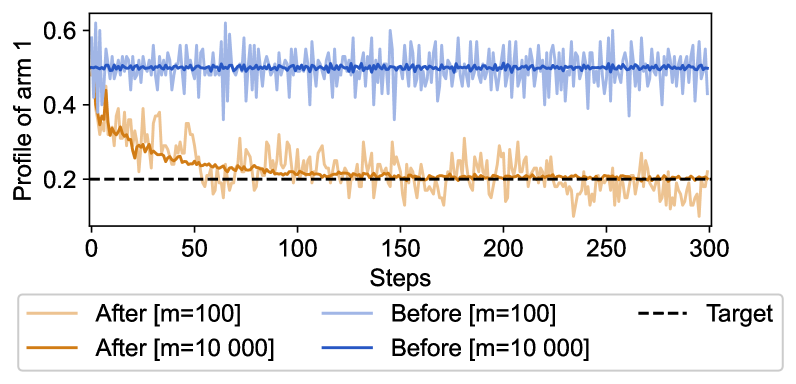
We study the problem of decentralized task offloading and load-balancing in a dense network with numerous devices and a set of edge servers. Solving this problem optimally is complicated due to the unknown network information and random task sizes. The shared network resources also influence the users' decisions and resource distribution. Our solution combines the mean field multi-agent multi-armed bandit (MAB) game with a load-balancing technique that adjusts the servers' rewards to achieve a target population profile despite the distributed user decision-making. Numerical results demonstrate the efficacy of our approach and the convergence to the target load distribution.
Read more7/2/2024
0
When `Computing follows Vehicles': Decentralized Mobility-Aware Resource Allocation in the Edge-to-Cloud Continuum
Zeinab Nezami, Emmanouil Chaniotakis, Evangelos Pournaras
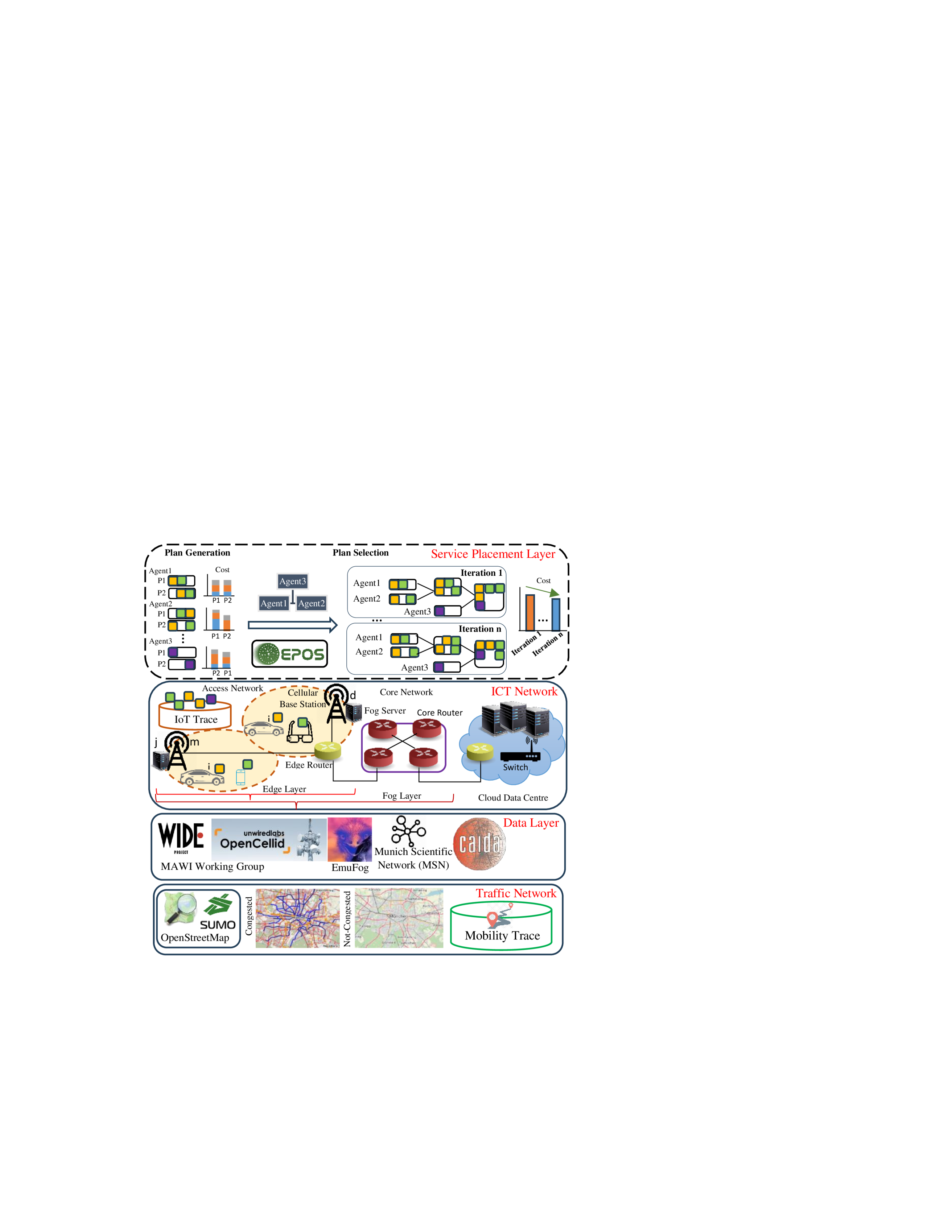
The transformation of smart mobility is unprecedented--Autonomous, shared and electric connected vehicles, along with the urgent need to meet ambitious net-zero targets by shifting to low-carbon transport modalities result in new traffic patterns and requirements for real-time computation at large-scale, for instance, augmented reality applications. The cloud computing paradigm can neither respond to such low-latency requirements nor adapt resource allocation to such dynamic spatio-temporal service requests. This paper addresses this grand challenge by introducing a novel decentralized optimization framework for mobility-aware edge-to-cloud resource allocation, service offloading, provisioning and load-balancing. In contrast to related work, this framework comes with superior efficiency and cost-effectiveness under evaluation in real-world traffic settings and mobility datasets. This breakthrough capability of 'computing follows vehicles' proves able to reduce utilization variance by more than 40 times, while preventing service deadline violations by 14%-34%.
Read more5/7/2024