Deep Clustering of Tabular Data by Weighted Gaussian Distribution Learning

0
🤿
Sign in to get full access
Overview
- This paper presents a new deep clustering method called Gaussian Cluster Embedding in Autoencoder Latent Space (G-CEALS) for tabular data.
- Tabular data with heterogeneous features pose unique challenges for representation learning, where deep learning has not yet surpassed traditional machine learning approaches.
- G-CEALS is an unsupervised deep clustering framework that learns the parameters of multivariate Gaussian cluster distributions by iteratively updating individual cluster weights.
- The method outperforms nine state-of-the-art clustering techniques on 16 tabular datasets, substantially improving on traditional K-means and Gaussian Mixture Model (GMM) clustering.
Plain English Explanation
Deep learning methods have primarily been used for supervised learning tasks on image or text data, with limited applications to clustering problems. In contrast, tabular data (like spreadsheets or databases) with diverse features pose unique challenges that deep learning has not yet solved as effectively as traditional machine learning approaches.
To address this gap, the researchers developed a new deep clustering method called G-CEALS for tabular data. G-CEALS is an unsupervised framework that learns the parameters of Gaussian cluster distributions by iteratively updating the weights of individual clusters. This allows the model to discover meaningful groupings within the tabular data.
When tested on 16 different tabular datasets, G-CEALS outperformed 9 other state-of-the-art clustering techniques. It substantially improved on the performance of standard methods like K-means and Gaussian Mixture Models, which are still commonly used for clustering tabular data.
The researchers argue that developing computationally efficient and high-performing deep clustering frameworks like G-CEALS is crucial to unlocking the full benefits of deep learning on tabular data, going beyond what traditional machine learning can achieve. This could enable a wide range of new applications and insights from complex datasets.
Technical Explanation
The G-CEALS method is an unsupervised deep clustering framework designed specifically for tabular data with heterogeneous features. It learns to model the parameters of multivariate Gaussian cluster distributions by iteratively updating the individual cluster weights in the latent space of an autoencoder neural network.
The autoencoder first encodes the input tabular data into a lower-dimensional latent representation. G-CEALS then initializes a set of Gaussian cluster centroids in this latent space and alternates between (1) assigning data points to the nearest cluster centroid and (2) updating the cluster parameters to better fit the assigned data points.
This iterative process allows G-CEALS to discover meaningful groupings or clusters within the tabular data, leveraging the autoencoder's ability to learn robust latent representations. The researchers evaluated G-CEALS on 16 diverse tabular datasets and found that it outperformed 9 state-of-the-art clustering methods, including traditional approaches like K-means and Gaussian Mixture Models.
G-CEALS achieved average rank orderings of 2.9 (±1.7) and 2.8 (±1.7) for clustering accuracy and adjusted Rand index (ARI) scores, respectively, indicating its strong performance relative to the baselines. This suggests that deep clustering frameworks like G-CEALS can substantially improve on traditional machine learning techniques for tabular data, opening up new possibilities for deriving insights from complex, heterogeneous datasets.
Critical Analysis
The researchers acknowledge that while G-CEALS demonstrates promising results, there are still opportunities for further improvement and exploration. For example, the paper does not investigate the scalability of the method to very large tabular datasets or its robustness to noisy or missing data, which are common challenges in real-world tabular data applications.
Additionally, the paper does not provide much insight into the types of tabular data where G-CEALS is likely to excel or underperform compared to other clustering approaches. A more detailed analysis of the characteristics of the datasets and the clustering results could help users better understand the method's strengths and limitations.
Furthermore, the researchers do not discuss potential biases or fairness considerations that may arise when applying G-CEALS to sensitive domains, such as healthcare or finance. As deep learning methods become more widely adopted, it is crucial to consider these ethical implications.
Despite these limitations, the G-CEALS method represents an important step forward in developing deep learning techniques for tabular data clustering, an area that has historically been dominated by traditional machine learning approaches. Continuing research in this direction, as suggested by the authors, could yield further advancements and unlock new applications for deep learning on complex, heterogeneous datasets.
Conclusion
This paper presents a novel deep clustering method called G-CEALS that addresses the unique challenges of tabular data with heterogeneous features. By learning the parameters of multivariate Gaussian cluster distributions in the latent space of an autoencoder, G-CEALS is able to outperform a range of state-of-the-art clustering techniques on 16 diverse tabular datasets.
The researchers argue that developing computationally efficient and high-performing deep clustering frameworks like G-CEALS is crucial to realizing the full potential of deep learning for tabular data applications, going beyond the capabilities of traditional machine learning approaches. As the volume and complexity of tabular data continue to grow, tools like G-CEALS could enable new insights and discoveries across a wide range of domains.
While the paper identifies some opportunities for further research and development, the G-CEALS method represents an important step forward in advancing the field of deep learning for tabular data clustering. As the technology continues to evolve, it will be exciting to see how it can be leveraged to unlock the hidden value within complex, heterogeneous datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Deep Clustering of Tabular Data by Weighted Gaussian Distribution Learning
Shourav B. Rabbani, Ivan V. Medri, Manar D. Samad
Deep learning methods are primarily proposed for supervised learning of images or text with limited applications to clustering problems. In contrast, tabular data with heterogeneous features pose unique challenges in representation learning, where deep learning has yet to replace traditional machine learning. This paper addresses these challenges in developing one of the first deep clustering methods for tabular data: Gaussian Cluster Embedding in Autoencoder Latent Space (G-CEALS). G-CEALS is an unsupervised deep clustering framework for learning the parameters of multivariate Gaussian cluster distributions by iteratively updating individual cluster weights. The G-CEALS method presents average rank orderings of 2.9(1.7) and 2.8(1.7) based on clustering accuracy and adjusted Rand index (ARI) scores on sixteen tabular data sets, respectively, and outperforms nine state-of-the-art clustering methods. G-CEALS substantially improves clustering performance compared to traditional K-means and GMM, which are still de facto methods for clustering tabular data. Similar computationally efficient and high-performing deep clustering frameworks are imperative to reap the myriad benefits of deep learning on tabular data over traditional machine learning.
Read more5/20/2024

0
Deep Feature Embedding for Tabular Data
Yuqian Wu, Hengyi Luo, Raymond S. T. Lee
Tabular data learning has extensive applications in deep learning but its existing embedding techniques are limited in numerical and categorical features such as the inability to capture complex relationships and engineering. This paper proposes a novel deep embedding framework with leverages lightweight deep neural networks to generate effective feature embeddings for tabular data in machine learning research. For numerical features, a two-step feature expansion and deep transformation technique is used to capture copious semantic information. For categorical features, a unique identification vector for each entity is referred by a compact lookup table with a parameterized deep embedding function to uniform the embedding size dimensions, and transformed into a embedding vector using deep neural network. Experiments are conducted on real-world datasets for performance evaluation.
Read more9/2/2024
🤿
0
Interpretable Deep Clustering for Tabular Data
Jonathan Svirsky, Ofir Lindenbaum
Clustering is a fundamental learning task widely used as a first step in data analysis. For example, biologists use cluster assignments to analyze genome sequences, medical records, or images. Since downstream analysis is typically performed at the cluster level, practitioners seek reliable and interpretable clustering models. We propose a new deep-learning framework for general domain tabular data that predicts interpretable cluster assignments at the instance and cluster levels. First, we present a self-supervised procedure to identify the subset of the most informative features from each data point. Then, we design a model that predicts cluster assignments and a gate matrix that provides cluster-level feature selection. Overall, our model provides cluster assignments with an indication of the driving feature for each sample and each cluster. We show that the proposed method can reliably predict cluster assignments in biological, text, image, and physics tabular datasets. Furthermore, using previously proposed metrics, we verify that our model leads to interpretable results at a sample and cluster level. Our code is available at https://github.com/jsvir/idc.
Read more6/11/2024
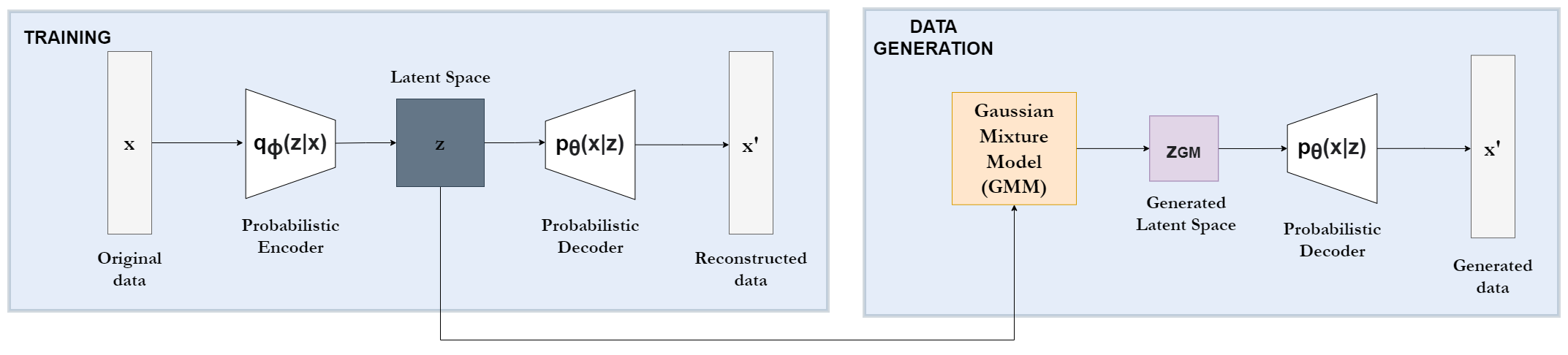
0
An improved tabular data generator with VAE-GMM integration
Patricia A. Apell'aniz, Juan Parras, Santiago Zazo
The rising use of machine learning in various fields requires robust methods to create synthetic tabular data. Data should preserve key characteristics while addressing data scarcity challenges. Current approaches based on Generative Adversarial Networks, such as the state-of-the-art CTGAN model, struggle with the complex structures inherent in tabular data. These data often contain both continuous and discrete features with non-Gaussian distributions. Therefore, we propose a novel Variational Autoencoder (VAE)-based model that addresses these limitations. Inspired by the TVAE model, our approach incorporates a Bayesian Gaussian Mixture model (BGM) within the VAE architecture. This avoids the limitations imposed by assuming a strictly Gaussian latent space, allowing for a more accurate representation of the underlying data distribution during data generation. Furthermore, our model offers enhanced flexibility by allowing the use of various differentiable distributions for individual features, making it possible to handle both continuous and discrete data types. We thoroughly validate our model on three real-world datasets with mixed data types, including two medically relevant ones, based on their resemblance and utility. This evaluation demonstrates significant outperformance against CTGAN and TVAE, establishing its potential as a valuable tool for generating synthetic tabular data in various domains, particularly in healthcare.
Read more4/15/2024