Deep Instruction Tuning for Segment Anything Model

0

Sign in to get full access
Overview
- This paper explores a technique called "Deep Instruction Tuning" to improve the performance of the Segment Anything Model (SAM), a powerful image segmentation model.
- The researchers demonstrate how fine-tuning SAM with natural language instructions can boost its accuracy and generalization capabilities.
- The paper provides insights into the benefits of leveraging language-based training for visual understanding tasks, which could have broader implications for the field of computer vision.
Plain English Explanation
The Segment Anything Model is a state-of-the-art computer vision system that can identify and outline objects in images with impressive accuracy. In this paper, the researchers explore a technique called "Deep Instruction Tuning" to further improve SAM's performance.
The key idea is to fine-tune the SAM model by training it on a large dataset of natural language instructions paired with corresponding image segmentation tasks. This allows the model to better understand how humans describe and refer to objects in the real world, which can help it generalize and perform better on a wider range of segmentation challenges.
For example, imagine you show the model an image of a kitchen and ask it to "Outline the stove." With standard training, the model may struggle to accurately identify the stove. But by fine-tuning it with many examples of natural language instructions like "Segment the oven" or "Draw a box around the microwave," the model can learn to better interpret and respond to the way humans naturally describe visual concepts.
The researchers demonstrate that this "Deep Instruction Tuning" approach leads to significant improvements in SAM's segmentation accuracy, especially on challenging or unusual images that differ from the model's original training data. This suggests that incorporating language-based learning can be a powerful way to enhance the capabilities of computer vision systems and help them better understand the world the way humans do.
Technical Explanation
The paper proposes a "Deep Instruction Tuning" approach to improve the Segment Anything Model, a state-of-the-art image segmentation model. The key idea is to fine-tune SAM using a large dataset of natural language instructions paired with corresponding image segmentation tasks.
The researchers first pre-train SAM on a diverse dataset of images and instance segmentation masks. They then further fine-tune the model by exposing it to a large corpus of language instructions like "Outline the dog" or "Draw a bounding box around the car." The model learns to associate these natural language cues with the relevant visual features and segmentation outputs.
Through extensive experiments, the authors demonstrate that this "Deep Instruction Tuning" approach leads to significant improvements in SAM's segmentation accuracy, particularly on challenging or unusual images that differ from the model's original training distribution. They also show that the fine-tuned model exhibits better generalization capabilities, allowing it to more effectively handle novel segmentation tasks.
The paper's findings suggest that incorporating language-based learning can be a powerful way to enhance the performance and robustness of computer vision systems. By training models to understand natural human descriptions of visual concepts, it may be possible to unlock new capabilities that go beyond what can be achieved through standard image-only training.
Critical Analysis
The paper presents a compelling approach to improving the Segment Anything Model, but there are a few potential limitations and areas for further research worth considering:
-
Dataset Bias: The effectiveness of the "Deep Instruction Tuning" approach may depend heavily on the quality and diversity of the natural language instruction dataset used for fine-tuning. If the dataset is biased or lacks coverage of certain types of instructions, the model's generalization may be constrained.
-
Computational Overhead: Fine-tuning large neural networks like SAM can be computationally expensive and time-consuming. The authors do not provide a detailed analysis of the training time and resource requirements of their approach, which could be an important practical consideration.
-
Explainability: While the paper demonstrates improved performance, it does not delve deeply into explaining how the language-based fine-tuning influences the model's internal representations and decision-making processes. Gaining a better understanding of the underlying mechanisms could lead to further improvements.
-
Robustness to Adversarial Attacks: The paper does not explore the model's robustness to adversarial attacks or other forms of distribution shift. Ensuring the stability and reliability of segmentation models in the face of such challenges is an important area for future research.
Overall, the paper presents a promising direction for enhancing the capabilities of image segmentation models through language-based learning. Further exploration of the proposed approach, as well as addressing the potential limitations, could lead to even more powerful and versatile computer vision systems.
Conclusion
This paper introduces a "Deep Instruction Tuning" technique to improve the performance of the Segment Anything Model, a state-of-the-art image segmentation system. By fine-tuning SAM with a large dataset of natural language instructions paired with corresponding segmentation tasks, the researchers demonstrate significant gains in accuracy and generalization capabilities.
The findings suggest that incorporating language-based learning can be a powerful way to enhance the understanding and capabilities of computer vision models, enabling them to better interpret the world the way humans do. This work has the potential to unlock new applications and possibilities in the field of image understanding and analysis.
While the paper presents a compelling approach, there are some areas for further exploration, such as the impact of dataset bias, computational overhead, and model explainability. Addressing these challenges could lead to even more robust and versatile segmentation models that can reliably handle a wide range of visual recognition tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deep Instruction Tuning for Segment Anything Model
Xiaorui Huang, Gen Luo, Chaoyang Zhu, Bo Tong, Yiyi Zhou, Xiaoshuai Sun, Rongrong Ji
Recently, Segment Anything Model (SAM) has become a research hotspot in the fields of multimedia and computer vision, which exhibits powerful yet versatile capabilities on various (un) conditional image segmentation tasks. Although SAM can support different types of segmentation prompts, we note that, compared to point- and box-guided segmentations, it performs much worse on text-instructed tasks, e.g., referring image segmentation (RIS). In this paper, we argue that deep text instruction tuning is key to mitigate such shortcoming caused by the shallow fusion scheme in its default light-weight mask decoder. To address this issue, we propose two simple yet effective deep instruction tuning (DIT) methods for SAM, one is end-to-end and the other is layer-wise. With minimal modifications, DITs can directly transform the image encoder of SAM as a stand-alone vision-language learner in contrast to building another deep fusion branch, maximizing the benefit of its superior segmentation capability. Extensive experiments on three highly competitive benchmark datasets of RIS show that a simple end-to-end DIT can improve SAM by a large margin, while the layer-wise DIT can further boost the performance to state-of-the-art with much less data and training expenditures. Our code is released at: https://github.com/wysnzzzz/DIT.
Read more4/30/2024
0
S-SAM: SVD-based Fine-Tuning of Segment Anything Model for Medical Image Segmentation
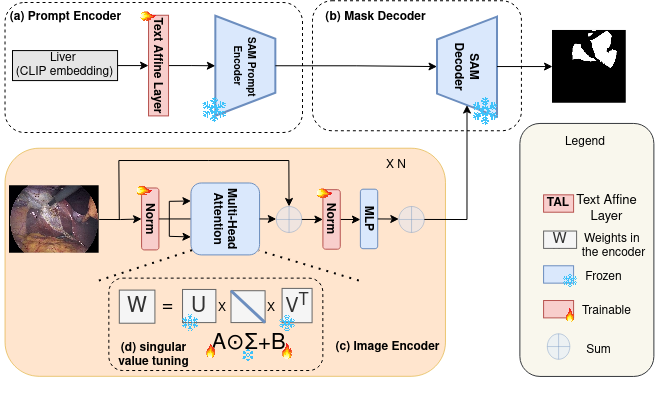
Jay N. Paranjape, Shameema Sikder, S. Swaroop Vedula, Vishal M. Patel
Medical image segmentation has been traditionally approached by training or fine-tuning the entire model to cater to any new modality or dataset. However, this approach often requires tuning a large number of parameters during training. With the introduction of the Segment Anything Model (SAM) for prompted segmentation of natural images, many efforts have been made towards adapting it efficiently for medical imaging, thus reducing the training time and resources. However, these methods still require expert annotations for every image in the form of point prompts or bounding box prompts during training and inference, making it tedious to employ them in practice. In this paper, we propose an adaptation technique, called S-SAM, that only trains parameters equal to 0.4% of SAM's parameters and at the same time uses simply the label names as prompts for producing precise masks. This not only makes tuning SAM more efficient than the existing adaptation methods but also removes the burden of providing expert prompts. We call this modified version S-SAM and evaluate it on five different modalities including endoscopic images, x-ray, ultrasound, CT, and histology images. Our experiments show that S-SAM outperforms state-of-the-art methods as well as existing SAM adaptation methods while tuning a significantly less number of parameters. We release the code for S-SAM at https://github.com/JayParanjape/SVDSAM.
Read more8/14/2024

0
Performance Evaluation of Segment Anything Model with Variational Prompting for Application to Non-Visible Spectrum Imagery
Yona Falinie A. Gaus, Neelanjan Bhowmik, Brian K. S. Isaac-Medina, Toby P. Breckon
The Segment Anything Model (SAM) is a deep neural network foundational model designed to perform instance segmentation which has gained significant popularity given its zero-shot segmentation ability. SAM operates by generating masks based on various input prompts such as text, bounding boxes, points, or masks, introducing a novel methodology to overcome the constraints posed by dataset-specific scarcity. While SAM is trained on an extensive dataset, comprising ~11M images, it mostly consists of natural photographic images with only very limited images from other modalities. Whilst the rapid progress in visual infrared surveillance and X-ray security screening imaging technologies, driven forward by advances in deep learning, has significantly enhanced the ability to detect, classify and segment objects with high accuracy, it is not evident if the SAM zero-shot capabilities can be transferred to such modalities. This work assesses SAM capabilities in segmenting objects of interest in the X-ray/infrared modalities. Our approach reuses the pre-trained SAM with three different prompts: bounding box, centroid and random points. We present quantitative/qualitative results to showcase the performance on selected datasets. Our results show that SAM can segment objects in the X-ray modality when given a box prompt, but its performance varies for point prompts. Specifically, SAM performs poorly in segmenting slender objects and organic materials, such as plastic bottles. We find that infrared objects are also challenging to segment with point prompts given the low-contrast nature of this modality. This study shows that while SAM demonstrates outstanding zero-shot capabilities with box prompts, its performance ranges from moderate to poor for point prompts, indicating that special consideration on the cross-modal generalisation of SAM is needed when considering use on X-ray/infrared imagery.
Read more4/19/2024

0
CAT-SAM: Conditional Tuning for Few-Shot Adaptation of Segment Anything Model
Aoran Xiao, Weihao Xuan, Heli Qi, Yun Xing, Ruijie Ren, Xiaoqin Zhang, Ling Shao, Shijian Lu
The recent Segment Anything Model (SAM) has demonstrated remarkable zero-shot capability and flexible geometric prompting in general image segmentation. However, SAM often struggles when handling various unconventional images, such as aerial, medical, and non-RGB images. This paper presents CAT-SAM, a ConditionAl Tuning network that adapts SAM toward various unconventional target tasks with just few-shot target samples. CAT-SAM freezes the entire SAM and adapts its mask decoder and image encoder simultaneously with a small number of learnable parameters. The core design is a prompt bridge structure that enables decoder-conditioned joint tuning of the heavyweight image encoder and the lightweight mask decoder. The bridging maps the prompt token of the mask decoder to the image encoder, fostering synergic adaptation of the encoder and the decoder with mutual benefits. We develop two representative tuning strategies for the image encoder which leads to two CAT-SAM variants: one injecting learnable prompt tokens in the input space and the other inserting lightweight adapter networks. Extensive experiments over 11 unconventional tasks show that both CAT-SAM variants achieve superior target segmentation performance consistently even under the very challenging one-shot adaptation setup. Project page: https://xiaoaoran.github.io/projects/CAT-SAM
Read more7/17/2024