Deep Learning-based Depth Estimation Methods from Monocular Image and Videos: A Comprehensive Survey
2406.19675
0
0
🤿
Abstract
Estimating depth from single RGB images and videos is of widespread interest due to its applications in many areas, including autonomous driving, 3D reconstruction, digital entertainment, and robotics. More than 500 deep learning-based papers have been published in the past 10 years, which indicates the growing interest in the task. This paper presents a comprehensive survey of the existing deep learning-based methods, the challenges they address, and how they have evolved in their architecture and supervision methods. It provides a taxonomy for classifying the current work based on their input and output modalities, network architectures, and learning methods. It also discusses the major milestones in the history of monocular depth estimation, and different pipelines, datasets, and evaluation metrics used in existing methods.
Create account to get full access
Overview
- This paper presents a comprehensive survey of deep learning-based methods for estimating depth from single RGB images and videos.
- The task of monocular depth estimation has widespread applications in areas like autonomous driving, 3D reconstruction, digital entertainment, and robotics.
- The paper discusses the challenges addressed by these methods, as well as how the architectures and supervision techniques have evolved over the past 10 years.
- It provides a taxonomy for classifying the current work based on input/output modalities, network architectures, and learning methods.
- The paper also covers the major milestones in the history of monocular depth estimation, as well as the different pipelines, datasets, and evaluation metrics used in existing methods.
Plain English Explanation
Estimating the depth of objects in a scene from a single camera (also known as monocular depth estimation) is an important problem with many real-world applications. For example, self-driving cars need to understand the 3D structure of their surroundings to navigate safely, and augmented reality apps need depth information to overlay digital content realistically.
Over the past 10 years, researchers have developed hundreds of deep learning-based models to tackle this challenge. This survey paper provides an overview of these methods, explaining the key ideas and how they have evolved.
The paper starts by categorizing the different types of depth estimation models based on factors like their input (e.g. a single image, a video) and the way they are trained (e.g. using self-supervision, leveraging correspondence priors). It then highlights some of the major breakthroughs, like the development of real-time depth estimation models and techniques for repurposing image generation models for depth prediction.
Overall, this survey provides a helpful overview of the state-of-the-art in monocular depth estimation, making it easier for researchers and practitioners to navigate this rapidly evolving field.
Technical Explanation
This paper presents a comprehensive survey of deep learning-based methods for monocular depth estimation - the task of predicting the 3D structure of a scene from a single 2D image or video. The authors first provide a high-level taxonomy to categorize existing approaches based on their input and output modalities, network architectures, and training techniques.
They then dive deeper into the key milestones in the history of monocular depth estimation. This includes the development of real-time models suitable for embedded systems, as well as methods that repurpose diffusion-based image generators to predict depth. The survey also covers techniques that leverage self-supervision and correspondence priors to improve depth prediction without requiring expensive ground truth depth data.
Throughout the paper, the authors discuss the various datasets, evaluation metrics, and processing pipelines used by the community. They provide a comprehensive overview of the field, making it easier for researchers to understand the current state-of-the-art and identify promising directions for future work.
Critical Analysis
The survey provides a thorough and well-structured overview of the monocular depth estimation landscape. By categorizing the different approaches, the authors give readers a clear mental model of the key dimensions along which these methods vary.
That said, the paper does not delve deeply into the specific trade-offs and limitations of each technique. For example, while it mentions the development of real-time depth estimation models, it does not discuss the potential accuracy or efficiency trade-offs compared to more computationally-intensive approaches.
Additionally, the survey focuses primarily on technical advances, with less emphasis on the real-world implications and societal impacts of this technology. As monocular depth estimation becomes more widespread, it will be important to consider issues around privacy, bias, and the ethical use of these systems.
Overall, this paper serves as a valuable reference for researchers in the field, but could be enhanced by a more critical examination of the current state-of-the-art and a deeper exploration of the broader considerations around the deployment of these models.
Conclusion
This comprehensive survey paper provides a detailed overview of the rapid progress in deep learning-based monocular depth estimation over the past decade. By categorizing the various approaches and highlighting key milestones, the authors give readers a clear understanding of the current landscape and the major technical advances in this important computer vision task.
The survey's insights can help researchers and practitioners navigate this fast-moving field, identify promising directions for future work, and better understand the tradeoffs and limitations of existing methods. As monocular depth estimation becomes more widely adopted, this paper serves as a valuable resource for understanding the state-of-the-art and considering the broader implications of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
Real-time Monocular Depth Estimation on Embedded Systems
Cheng Feng, Congxuan Zhang, Zhen Chen, Weiming Hu, Liyue Ge
0
0
Depth sensing is of paramount importance for unmanned aerial and autonomous vehicles. Nonetheless, contemporary monocular depth estimation methods employing complex deep neural networks within Convolutional Neural Networks are inadequately expedient for real-time inference on embedded platforms. This paper endeavors to surmount this challenge by proposing two efficient and lightweight architectures, RT-MonoDepth and RT-MonoDepth-S, thereby mitigating computational complexity and latency. Our methodologies not only attain accuracy comparable to prior depth estimation methods but also yield faster inference speeds. Specifically, RT-MonoDepth and RT-MonoDepth-S achieve frame rates of 18.4&30.5 FPS on NVIDIA Jetson Nano and 253.0&364.1 FPS on Jetson AGX Orin, utilizing a single RGB image of resolution 640x192. The experimental results underscore the superior accuracy and faster inference speed of our methods in comparison to existing fast monocular depth estimation methodologies on the KITTI dataset.
6/10/2024
🖼️
Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, Konrad Schindler
0
0
Monocular depth estimation is a fundamental computer vision task. Recovering 3D depth from a single image is geometrically ill-posed and requires scene understanding, so it is not surprising that the rise of deep learning has led to a breakthrough. The impressive progress of monocular depth estimators has mirrored the growth in model capacity, from relatively modest CNNs to large Transformer architectures. Still, monocular depth estimators tend to struggle when presented with images with unfamiliar content and layout, since their knowledge of the visual world is restricted by the data seen during training, and challenged by zero-shot generalization to new domains. This motivates us to explore whether the extensive priors captured in recent generative diffusion models can enable better, more generalizable depth estimation. We introduce Marigold, a method for affine-invariant monocular depth estimation that is derived from Stable Diffusion and retains its rich prior knowledge. The estimator can be fine-tuned in a couple of days on a single GPU using only synthetic training data. It delivers state-of-the-art performance across a wide range of datasets, including over 20% performance gains in specific cases. Project page: https://marigoldmonodepth.github.io.
4/4/2024

Uncertainty and Self-Supervision in Single-View Depth
Javier Rodriguez-Puigvert
0
0
Single-view depth estimation refers to the ability to derive three-dimensional information per pixel from a single two-dimensional image. Single-view depth estimation is an ill-posed problem because there are multiple depth solutions that explain 3D geometry from a single view. While deep neural networks have been shown to be effective at capturing depth from a single view, the majority of current methodologies are deterministic in nature. Accounting for uncertainty in the predictions can avoid disastrous consequences when applied to fields such as autonomous driving or medical robotics. We have addressed this problem by quantifying the uncertainty of supervised single-view depth for Bayesian deep neural networks. There are scenarios, especially in medicine in the case of endoscopic images, where such annotated data is not available. To alleviate the lack of data, we present a method that improves the transition from synthetic to real domain methods. We introduce an uncertainty-aware teacher-student architecture that is trained in a self-supervised manner, taking into account the teacher uncertainty. Given the vast amount of unannotated data and the challenges associated with capturing annotated depth in medical minimally invasive procedures, we advocate a fully self-supervised approach that only requires RGB images and the geometric and photometric calibration of the endoscope. In endoscopic imaging, the camera and light sources are co-located at a small distance from the target surfaces. This setup indicates that brighter areas of the image are nearer to the camera, while darker areas are further away. Building on this observation, we exploit the fact that for any given albedo and surface orientation, pixel brightness is inversely proportional to the square of the distance. We propose the use of illumination as a strong single-view self-supervisory signal for deep neural networks.
6/21/2024
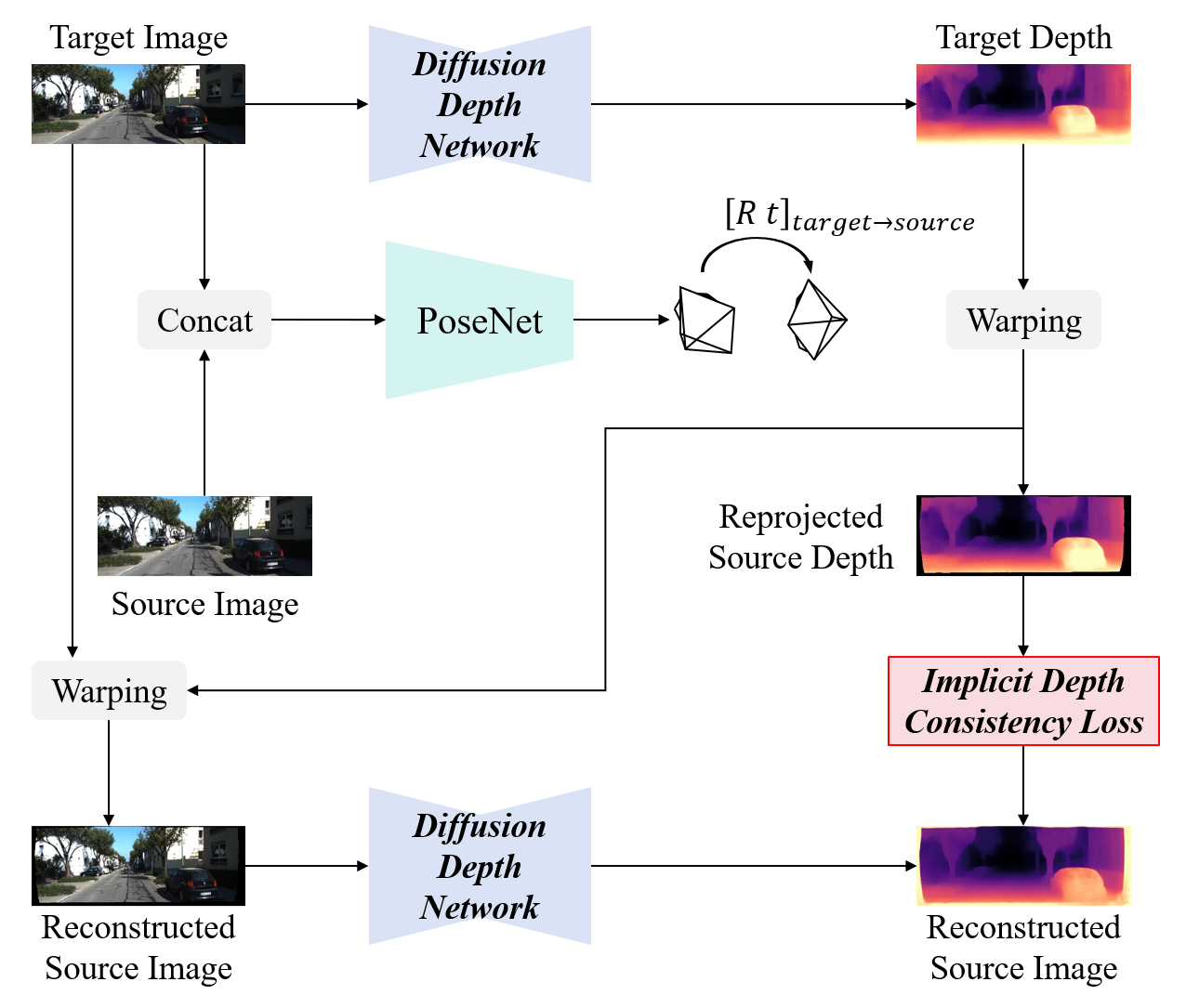
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Runze Liu, Dongchen Zhu, Guanghui Zhang, Yue Xu, Wenjun Shi, Xiaolin Zhang, Lei Wang, Jiamao Li
0
0
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
6/17/2024