Deep Learning Based Named Entity Recognition Models for Recipes
2402.17447
0
0
Abstract
Food touches our lives through various endeavors, including flavor, nourishment, health, and sustainability. Recipes are cultural capsules transmitted across generations via unstructured text. Automated protocols for recognizing named entities, the building blocks of recipe text, are of immense value for various applications ranging from information extraction to novel recipe generation. Named entity recognition is a technique for extracting information from unstructured or semi-structured data with known labels. Starting with manually-annotated data of 6,611 ingredient phrases, we created an augmented dataset of 26,445 phrases cumulatively. Simultaneously, we systematically cleaned and analyzed ingredient phrases from RecipeDB, the gold-standard recipe data repository, and annotated them using the Stanford NER. Based on the analysis, we sampled a subset of 88,526 phrases using a clustering-based approach while preserving the diversity to create the machine-annotated dataset. A thorough investigation of NER approaches on these three datasets involving statistical, fine-tuning of deep learning-based language models and few-shot prompting on large language models (LLMs) provides deep insights. We conclude that few-shot prompting on LLMs has abysmal performance, whereas the fine-tuned spaCy-transformer emerges as the best model with macro-F1 scores of 95.9%, 96.04%, and 95.71% for the manually-annotated, augmented, and machine-annotated datasets, respectively.
Create account to get full access
Overview
- This paper explores the use of deep learning models for named entity recognition (NER) in recipe text data.
- The researchers developed and evaluated several deep learning-based NER models, including Fine-Tuning Pre-Trained Named Entity Recognition, DistALaNER: Distantly Supervised Active Learning Augmented Named, Few-Shot Name Entity Recognition on StackOverflow, Unified Label-Aware Contrastive Learning Framework for Few, and MixExperts: A Language Model for Named Entity Recognition.
- The goal was to extract key information like ingredients, cooking methods, and equipment from recipe text data using these advanced NER techniques.
Plain English Explanation
This research paper looks at using modern deep learning models to automatically identify and extract important information from recipe text. Recipes often contain lots of specialized terms for ingredients, cooking techniques, tools, and other key details. The researchers developed and tested several different deep learning-based named entity recognition (NER) models to see how well they could pick out this kind of information from recipe text data.
NER is a natural language processing technique that can scan through text and identify specific types of entities, like people, locations, organizations, and in this case, ingredients, cooking methods, and kitchen equipment. The researchers tried out several state-of-the-art deep learning NER models, including some that use techniques like fine-tuning pre-trained models, distant supervision, and few-shot learning.
The goal was to see which of these advanced NER models could most accurately and efficiently extract the key information from recipe text. This could be useful for all kinds of recipe-related applications, like automatically organizing and indexing recipe data, improving recipe search and recommendation systems, and even generating new recipes by understanding the relationships between ingredients and preparation steps.
Technical Explanation
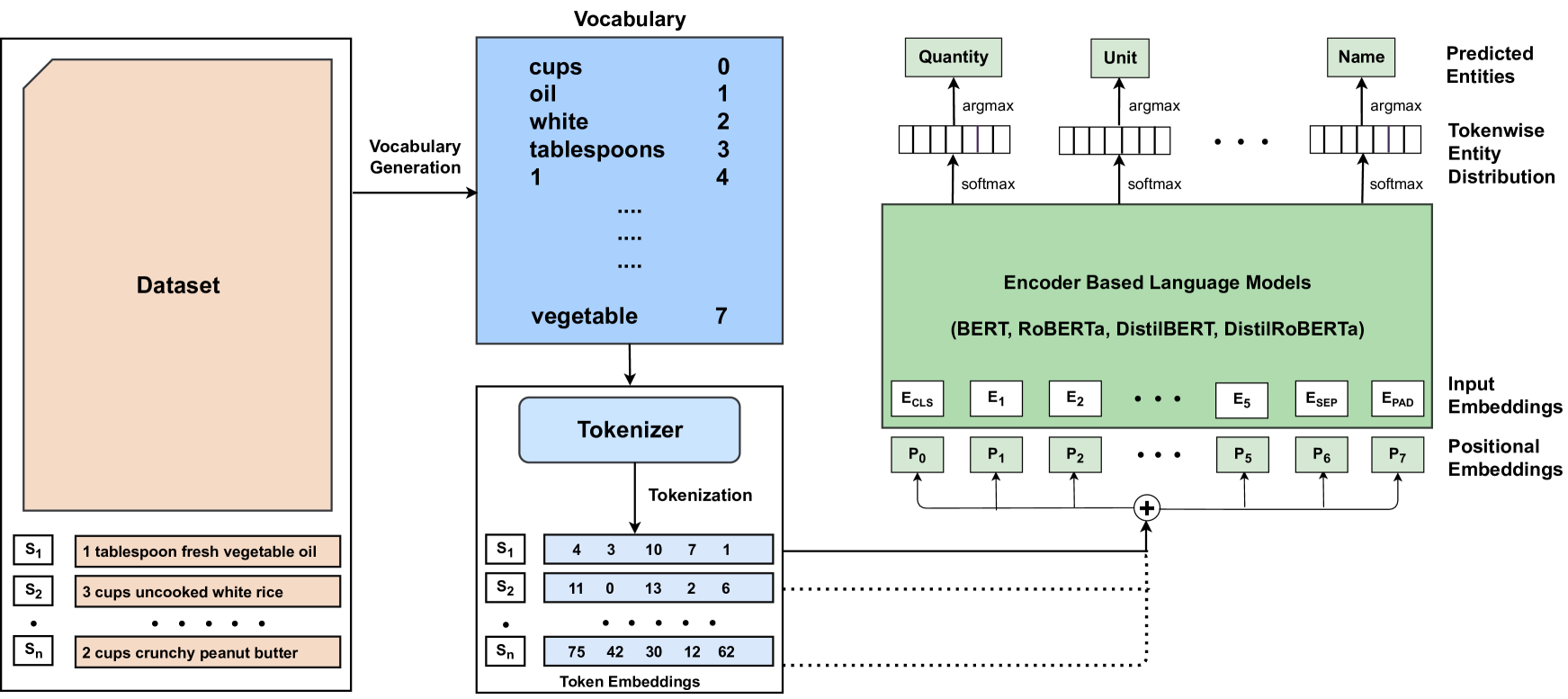
The researchers first built a dataset of recipe text data, which they preprocessed and annotated with named entity labels for ingredients, cooking methods, and kitchen equipment. They then evaluated the performance of several deep learning-based NER models on this recipe dataset:
- Fine-Tuning Pre-Trained Named Entity Recognition: This approach starts with a pre-trained NER model and fine-tunes it on the recipe dataset to adapt it to the specific domain.
- DistALaNER: Distantly Supervised Active Learning Augmented Named: This model uses distant supervision to automatically generate training labels, combined with active learning to efficiently annotate the most informative samples.
- Few-Shot Name Entity Recognition on StackOverflow: A few-shot learning approach that can recognize named entities with limited training data, applied to the recipe domain.
- Unified Label-Aware Contrastive Learning Framework for Few: A contrastive learning framework that leverages label information to improve few-shot NER performance.
- MixExperts: A Language Model for Named Entity Recognition: A modular language model that combines multiple expert sub-models to handle different types of named entities.
The researchers evaluated these models on standard NER metrics like F1 score and examined their tradeoffs in terms of performance, training data efficiency, and computational cost. The results showed that the various deep learning approaches could achieve strong NER performance on the recipe dataset, with some models offering advantages in specific areas.
Critical Analysis
The paper provides a comprehensive evaluation of several state-of-the-art deep learning NER models on recipe text data. The researchers clearly outline the strengths and weaknesses of each approach, which is helpful for understanding the tradeoffs involved in applying these techniques to real-world recipe processing tasks.
One potential limitation is the relatively small size of the recipe dataset used in the experiments. While the dataset was carefully annotated, expanding the corpus of labeled recipe text could further validate the models' performance and generalization capabilities. Additionally, the paper does not explore the impact of recipe text structure and formatting on NER accuracy, which could be an important factor in practical applications.
The researchers also do not delve deeply into the interpretability and explainability of the NER models. Understanding why certain entities are recognized or missed could provide valuable insights for improving the models and tailoring them to specific user needs. Incorporating more qualitative analysis and error case studies could strengthen the critical assessment of the research.
Overall, this paper makes a valuable contribution by demonstrating the feasibility and potential of advanced deep learning techniques for named entity recognition in recipe text. The findings could inform the development of more intelligent recipe processing and understanding systems, which could have wide-ranging applications in the food and cooking domain.
Conclusion
This research paper explores the use of state-of-the-art deep learning models for named entity recognition (NER) in recipe text data. The researchers evaluated several advanced NER techniques, including fine-tuning pre-trained models, distant supervision, few-shot learning, contrastive learning, and modular language models.
The results show that these deep learning-based NER approaches can effectively extract key information like ingredients, cooking methods, and kitchen equipment from recipe text, with some models offering advantages in terms of performance, training data efficiency, and computational cost. This work lays the groundwork for developing more intelligent recipe processing and understanding systems, which could have significant applications in the food and cooking domain, such as improving recipe search, recommendation, and generation.
While the research provides a comprehensive technical evaluation, future work could further explore the interpretability and robustness of the NER models, as well as expand the recipe text dataset to validate the models' performance and generalization capabilities. Overall, this paper represents an important step forward in applying cutting-edge natural language processing techniques to the rich and complex world of recipes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Fine-tuning Pre-trained Named Entity Recognition Models For Indian Languages
Sankalp Bahad, Pruthwik Mishra, Karunesh Arora, Rakesh Chandra Balabantaray, Dipti Misra Sharma, Parameswari Krishnamurthy
0
0
Named Entity Recognition (NER) is a useful component in Natural Language Processing (NLP) applications. It is used in various tasks such as Machine Translation, Summarization, Information Retrieval, and Question-Answering systems. The research on NER is centered around English and some other major languages, whereas limited attention has been given to Indian languages. We analyze the challenges and propose techniques that can be tailored for Multilingual Named Entity Recognition for Indian Languages. We present a human annotated named entity corpora of 40K sentences for 4 Indian languages from two of the major Indian language families. Additionally,we present a multilingual model fine-tuned on our dataset, which achieves an F1 score of 0.80 on our dataset on average. We achieve comparable performance on completely unseen benchmark datasets for Indian languages which affirms the usability of our model.
5/13/2024

DistALANER: Distantly Supervised Active Learning Augmented Named Entity Recognition in the Open Source Software Ecosystem
Somnath Banerjee, Avik Dutta, Aaditya Agrawal, Rima Hazra, Animesh Mukherjee
0
0
With the AI revolution in place, the trend for building automated systems to support professionals in different domains such as the open source software systems, healthcare systems, banking systems, transportation systems and many others have become increasingly prominent. A crucial requirement in the automation of support tools for such systems is the early identification of named entities, which serves as a foundation for developing specialized functionalities. However, due to the specific nature of each domain, different technical terminologies and specialized languages, expert annotation of available data becomes expensive and challenging. In light of these challenges, this paper proposes a novel named entity recognition (NER) technique specifically tailored for the open-source software systems. Our approach aims to address the scarcity of annotated software data by employing a comprehensive two-step distantly supervised annotation process. This process strategically leverages language heuristics, unique lookup tables, external knowledge sources, and an active learning approach. By harnessing these powerful techniques, we not only enhance model performance but also effectively mitigate the limitations associated with cost and the scarcity of expert annotators. It is noteworthy that our model significantly outperforms the state-of-the-art LLMs by a substantial margin. We also show the effectiveness of NER in the downstream task of relation extraction.
6/21/2024

Fighting Against the Repetitive Training and Sample Dependency Problem in Few-shot Named Entity Recognition
Chang Tian, Wenpeng Yin, Dan Li, Marie-Francine Moens
0
0
Few-shot named entity recognition (NER) systems recognize entities using a few labeled training examples. The general pipeline consists of a span detector to identify entity spans in text and an entity-type classifier to assign types to entities. Current span detectors rely on extensive manual labeling to guide training. Almost every span detector requires initial training on basic span features followed by adaptation to task-specific features. This process leads to repetitive training of the basic span features among span detectors. Additionally, metric-based entity-type classifiers, such as prototypical networks, typically employ a specific metric that gauges the distance between the query sample and entity-type referents, ultimately assigning the most probable entity type to the query sample. However, these classifiers encounter the sample dependency problem, primarily stemming from the limited samples available for each entity-type referent. To address these challenges, we proposed an improved few-shot NER pipeline. First, we introduce a steppingstone span detector that is pre-trained on open-domain Wikipedia data. It can be used to initialize the pipeline span detector to reduce the repetitive training of basic features. Second, we leverage a large language model (LLM) to set reliable entity-type referents, eliminating reliance on few-shot samples of each type. Our model exhibits superior performance with fewer training steps and human-labeled data compared with baselines, as demonstrated through extensive experiments on various datasets. Particularly in fine-grained few-shot NER settings, our model outperforms strong baselines, including ChatGPT. We will publicly release the code, datasets, LLM outputs, and model checkpoints.
6/21/2024
New!Deep Image-to-Recipe Translation
Jiangqin Ma, Bilal Mawji, Franz Williams
0
0
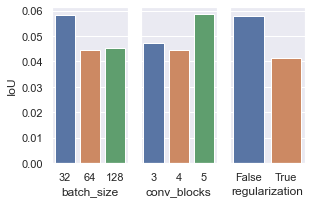
The modern saying, You Are What You Eat resonates on a profound level, reflecting the intricate connection between our identities and the food we consume. Our project, Deep Image-to-Recipe Translation, is an intersection of computer vision and natural language generation that aims to bridge the gap between cherished food memories and the art of culinary creation. Our primary objective involves predicting ingredients from a given food image. For this task, we first develop a custom convolutional network and then compare its performance to a model that leverages transfer learning. We pursue an additional goal of generating a comprehensive set of recipe steps from a list of ingredients. We frame this process as a sequence-to-sequence task and develop a recurrent neural network that utilizes pre-trained word embeddings. We address several challenges of deep learning including imbalanced datasets, data cleaning, overfitting, and hyperparameter selection. Our approach emphasizes the importance of metrics such as Intersection over Union (IoU) and F1 score in scenarios where accuracy alone might be misleading. For our recipe prediction model, we employ perplexity, a commonly used and important metric for language models. We find that transfer learning via pre-trained ResNet-50 weights and GloVe embeddings provide an exceptional boost to model performance, especially when considering training resource constraints. Although we have made progress on the image-to-recipe translation, there is an opportunity for future exploration with advancements in model architectures, dataset scalability, and enhanced user interaction.
7/2/2024