A Unified Label-Aware Contrastive Learning Framework for Few-Shot Named Entity Recognition
2404.17178
0
0
👁️
Abstract
Few-shot Named Entity Recognition (NER) aims to extract named entities using only a limited number of labeled examples. Existing contrastive learning methods often suffer from insufficient distinguishability in context vector representation because they either solely rely on label semantics or completely disregard them. To tackle this issue, we propose a unified label-aware token-level contrastive learning framework. Our approach enriches the context by utilizing label semantics as suffix prompts. Additionally, it simultaneously optimizes context-context and context-label contrastive learning objectives to enhance generalized discriminative contextual representations.Extensive experiments on various traditional test domains (OntoNotes, CoNLL'03, WNUT'17, GUM, I2B2) and the large-scale few-shot NER dataset (FEWNERD) demonstrate the effectiveness of our approach. It outperforms prior state-of-the-art models by a significant margin, achieving an average absolute gain of 7% in micro F1 scores across most scenarios. Further analysis reveals that our model benefits from its powerful transfer capability and improved contextual representations.
Create account to get full access
Overview
- Few-shot Named Entity Recognition (NER) aims to extract named entities using only a limited number of labeled examples
- Existing contrastive learning methods often struggle to create distinct context vector representations, either relying too heavily on label semantics or completely ignoring them
- This paper proposes a unified label-aware token-level contrastive learning framework to address this issue
Plain English Explanation
Named Entity Recognition (NER) is the process of identifying and classifying important words or phrases in text, such as people, organizations, locations, and dates. Few-shot NER refers to performing this task with only a small number of labeled examples to work with.
Existing techniques that use "contrastive learning" - a method of training models to distinguish between related concepts - often have trouble creating context vector representations (mathematical representations of the meaning of words in context) that are sufficiently distinct. This is because they either rely too much on the meanings of the labels themselves, or they ignore the label information entirely.
To overcome this limitation, the researchers propose a new approach that combines the benefits of using label semantics and contrastive learning. Their "unified label-aware token-level contrastive learning framework" enriches the context by using the label meanings as "suffix prompts" (additional information appended to the text). It also simultaneously optimizes two contrastive learning objectives - one for improving the distinctness of the context representations, and one for aligning the context representations with the label semantics.
Through extensive testing on a variety of NER datasets, the researchers show that this approach outperforms previous state-of-the-art models by a significant margin, achieving an average gain of 7% in the key performance metric of micro F1 score. Further analysis indicates that their model benefits from improved transfer capability and better contextual representations.
Technical Explanation
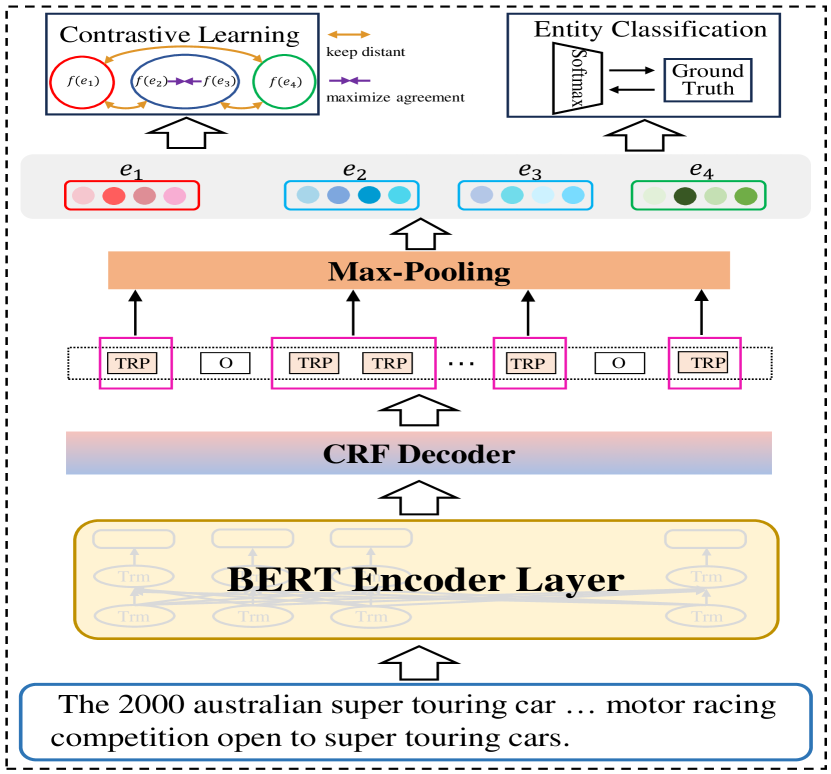
The paper introduces a novel "unified label-aware token-level contrastive learning framework" for few-shot Named Entity Recognition (NER). Existing contrastive learning approaches for few-shot NER [1],[2],[3] often struggle to create sufficiently distinct context vector representations, either relying too heavily on label semantics or completely disregarding them.
To address this issue, the proposed method enriches the context by utilizing label semantics as suffix prompts. Additionally, it simultaneously optimizes two contrastive learning objectives: one to enhance the generalized discriminative ability of the contextual representations, and another to better align the context representations with the label semantics.
Extensive experiments were conducted on a variety of traditional NER test domains (OntoNotes, CoNLL'03, WNUT'17, GUM, I2B2) as well as the large-scale few-shot NER dataset FEWNERD. The results demonstrate that the unified label-aware approach outperforms prior state-of-the-art models by a significant margin, achieving an average absolute gain of 7% in micro F1 scores across most scenarios. [4],[5]
Further analysis reveals that the model benefits from its powerful transfer capability and improved contextual representations, indicating the effectiveness of the proposed framework.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed few-shot NER approach, testing it on a diverse set of datasets. The authors acknowledge that their method relies on the availability of label semantics, which may not always be the case in real-world scenarios.
Additionally, the paper does not delve into potential fairness or bias issues that could arise from the use of this technique, such as the model favoring certain types of entities over others. Further research may be needed to better understand the limitations and potential pitfalls of the proposed framework.
That said, the significant performance gains demonstrated by the unified label-aware contrastive learning approach are promising and suggest that it could be a valuable tool in the field of few-shot NER. The insights on the model's transfer capability and improved contextual representations also offer avenues for future exploration and refinement of the technique.
Conclusion
This paper introduces a novel unified label-aware token-level contrastive learning framework for few-shot Named Entity Recognition. By leveraging label semantics as suffix prompts and simultaneously optimizing context-context and context-label contrastive learning objectives, the proposed approach is able to create more distinct and semantically-aligned contextual representations, leading to significant performance improvements over previous state-of-the-art models.
The demonstrated effectiveness of this technique across a wide range of NER datasets suggests that it could be a valuable contribution to the field of few-shot learning, with potential applications in other natural language processing tasks as well. Further research may be needed to address potential limitations and explore opportunities for refinement, but this work represents an important step forward in the development of robust and efficient few-shot NER systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Hybrid Multi-stage Decoding for Few-shot NER with Entity-aware Contrastive Learning
Peipei Liu, Gaosheng Wang, Ying Tong, Jian Liang, Zhenquan Ding, Hongsong Zhu
0
0
Few-shot named entity recognition can identify new types of named entities based on a few labeled examples. Previous methods employing token-level or span-level metric learning suffer from the computational burden and a large number of negative sample spans. In this paper, we propose the Hybrid Multi-stage Decoding for Few-shot NER with Entity-aware Contrastive Learning (MsFNER), which splits the general NER into two stages: entity-span detection and entity classification. There are 3 processes for introducing MsFNER: training, finetuning, and inference. In the training process, we train and get the best entity-span detection model and the entity classification model separately on the source domain using meta-learning, where we create a contrastive learning module to enhance entity representations for entity classification. During finetuning, we finetune the both models on the support dataset of target domain. In the inference process, for the unlabeled data, we first detect the entity-spans, then the entity-spans are jointly determined by the entity classification model and the KNN. We conduct experiments on the open FewNERD dataset and the results demonstrate the advance of MsFNER.
4/11/2024

Fighting Against the Repetitive Training and Sample Dependency Problem in Few-shot Named Entity Recognition
Chang Tian, Wenpeng Yin, Dan Li, Marie-Francine Moens
0
0
Few-shot named entity recognition (NER) systems recognize entities using a few labeled training examples. The general pipeline consists of a span detector to identify entity spans in text and an entity-type classifier to assign types to entities. Current span detectors rely on extensive manual labeling to guide training. Almost every span detector requires initial training on basic span features followed by adaptation to task-specific features. This process leads to repetitive training of the basic span features among span detectors. Additionally, metric-based entity-type classifiers, such as prototypical networks, typically employ a specific metric that gauges the distance between the query sample and entity-type referents, ultimately assigning the most probable entity type to the query sample. However, these classifiers encounter the sample dependency problem, primarily stemming from the limited samples available for each entity-type referent. To address these challenges, we proposed an improved few-shot NER pipeline. First, we introduce a steppingstone span detector that is pre-trained on open-domain Wikipedia data. It can be used to initialize the pipeline span detector to reduce the repetitive training of basic features. Second, we leverage a large language model (LLM) to set reliable entity-type referents, eliminating reliance on few-shot samples of each type. Our model exhibits superior performance with fewer training steps and human-labeled data compared with baselines, as demonstrated through extensive experiments on various datasets. Particularly in fine-grained few-shot NER settings, our model outperforms strong baselines, including ChatGPT. We will publicly release the code, datasets, LLM outputs, and model checkpoints.
6/21/2024
Few-shot Name Entity Recognition on StackOverflow
Xinwei Chen, Kun Li, Tianyou Song, Jiangjian Guo
0
0
StackOverflow, with its vast question repository and limited labeled examples, raise an annotation challenge for us. We address this gap by proposing RoBERTa+MAML, a few-shot named entity recognition (NER) method leveraging meta-learning. Our approach, evaluated on the StackOverflow NER corpus (27 entity types), achieves a 5% F1 score improvement over the baseline. We improved the results further domain-specific phrase processing enhance results.
4/30/2024

llmNER: (Zero|Few)-Shot Named Entity Recognition, Exploiting the Power of Large Language Models
Fabi'an Villena, Luis Miranda, Claudio Aracena
0
0
Large language models (LLMs) allow us to generate high-quality human-like text. One interesting task in natural language processing (NLP) is named entity recognition (NER), which seeks to detect mentions of relevant information in documents. This paper presents llmNER, a Python library for implementing zero-shot and few-shot NER with LLMs; by providing an easy-to-use interface, llmNER can compose prompts, query the model, and parse the completion returned by the LLM. Also, the library enables the user to perform prompt engineering efficiently by providing a simple interface to test multiple variables. We validated our software on two NER tasks to show the library's flexibility. llmNER aims to push the boundaries of in-context learning research by removing the barrier of the prompting and parsing steps.
6/10/2024