Deep low-latency joint speech transmission and enhancement over a gaussian channel
2404.19375
0
0
🤿
Abstract
Ensuring intelligible speech communication for hearing assistive devices in low-latency scenarios presents significant challenges in terms of speech enhancement, coding and transmission. In this paper, we propose novel solutions for low-latency joint speech transmission and enhancement, leveraging deep neural networks (DNNs). Our approach integrates two state-of-the-art DNN architectures for low-latency speech enhancement and low-latency analog joint source-channel-based transmission, creating a combined low-latency system and jointly training both systems in an end-to-end approach. Due to the computational demands of the enhancement system, this order is suitable when high computational power is unavailable in the decoder, like hearing assistive devices. The proposed system enables the configuration of total latency, achieving high performance even at latencies as low as 3 ms, which is typically challenging to attain. The simulation results provide compelling evidence that a joint enhancement and transmission system is superior to a simple concatenation system in diverse settings, encompassing various wireless channel conditions, latencies, and background noise scenarios.
Create account to get full access
Overview
- The paper presents a novel approach to enable low-latency speech communication for hearing assistive devices.
- The proposed system integrates deep neural networks for speech enhancement and analog joint source-channel coding to achieve low-latency performance.
- The system is designed to work well even in scenarios with high computational constraints, such as in hearing aids.
- Simulation results show the combined system outperforms a simple concatenation of the individual components in various wireless channel conditions, latencies, and background noise scenarios.
Plain English Explanation
The paper tackles the challenge of enabling clear, low-latency speech communication for hearing assistive devices like hearing aids. These devices need to quickly process and transmit speech signals while also enhancing the audio quality, which is a difficult technical problem.
The researchers developed a new system that combines two state-of-the-art deep learning models. One model is for low-latency speech enhancement, which improves the clarity of the speech signal. The other model is for low-latency analog transmission of the speech, ensuring the signal is encoded and sent efficiently.
By integrating these two models into a single, end-to-end system, the researchers were able to achieve very low latency - as little as 3 milliseconds - while still maintaining high speech quality. This is important for hearing aids and other devices where any delay in processing the audio can be disorienting for the user.
The key innovation is that the models are jointly trained to work together optimally, rather than just connecting them in a simple series. This allows the system to be highly efficient, even on the limited computing power typically available in hearing assistive devices.
Technical Explanation
The paper presents a novel low-latency system for joint speech enhancement and transmission, leveraging deep neural network (DNN) architectures. The system integrates two state-of-the-art DNN models: one for low-latency speech enhancement and one for low-latency analog joint source-channel coding.
The speech enhancement model uses a DNN architecture to quickly reduce noise and distortion in the input speech signal. The analog joint source-channel coding model encodes the enhanced speech signal for efficient wireless transmission with low latency.
The key innovation is that the researchers jointly train the two DNN models in an end-to-end fashion, allowing the system to be optimized as a whole. This is in contrast to a simple concatenation of the models, which would not leverage the synergies between the enhancement and transmission components.
The proposed system is designed to work well even in computational-constrained scenarios, like hearing assistive devices, where the enhancement processing needs to be done on the decoder side. Simulation results demonstrate the superiority of the joint system compared to a concatenated one, across a range of wireless channel conditions, latencies, and background noise levels.
Critical Analysis
The paper presents a compelling technical solution to a challenging real-world problem. By integrating speech enhancement and low-latency transmission in an end-to-end DNN-based system, the researchers have achieved impressive results in terms of latency and speech quality.
One potential limitation is that the system was only evaluated through simulations, and its performance in real-world deployments with actual hearing assistive devices remains to be seen. Additionally, the paper does not provide much detail on the specific DNN architectures used for the enhancement and transmission models, making it difficult to fully assess their novelty and complexity.
Further research could explore the generalization of the joint system to other types of audio signals beyond just speech, as well as its scalability to larger-scale deployments. Robustness to various environmental factors and the system's ability to adapt to changing conditions could also be investigated.
Overall, the paper presents a well-designed and promising approach to enabling low-latency, high-quality speech communication for hearing assistive devices, which could have significant real-world impact.
Conclusion
This paper introduces a novel deep learning-based system that integrates speech enhancement and low-latency wireless transmission, enabling intelligible and low-latency speech communication for hearing assistive devices. By jointly training the enhancement and transmission models, the researchers have created a highly efficient and effective solution that outperforms a simple concatenation of the individual components.
The key contribution of this work is the development of a practical, low-latency system that can be deployed on the limited computing resources of hearing aids and similar devices. The simulation results demonstrate the system's robust performance across a variety of challenging scenarios, highlighting its potential to significantly improve the user experience for those relying on hearing assistive technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
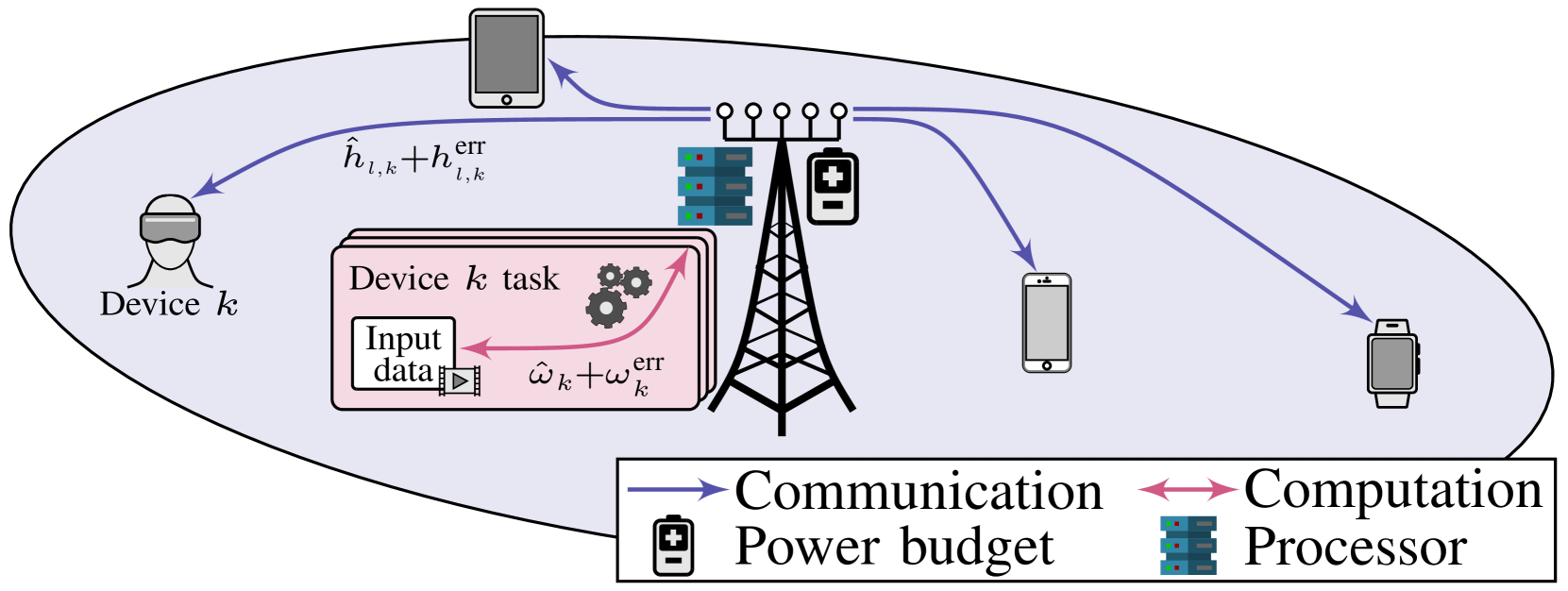
Robust Communication and Computation using Deep Learning via Joint Uncertainty Injection
Robert-Jeron Reifert, Hayssam Dahrouj, Alaa Alameer Ahmad, Haris Gacanin, Aydin Sezgin
0
0
The convergence of communication and computation, along with the integration of machine learning and artificial intelligence, stand as key empowering pillars for the sixth-generation of communication systems (6G). This paper considers a network of one base station serving a number of devices simultaneously using spatial multiplexing. The paper then presents an innovative deep learning-based approach to simultaneously manage the transmit and computing powers, alongside computation allocation, amidst uncertainties in both channel and computing states information. More specifically, the paper aims at proposing a robust solution that minimizes the worst-case delay across the served devices subject to computation and power constraints. The paper uses a deep neural network (DNN)-based solution that maps estimated channels and computation requirements to optimized resource allocations. During training, uncertainty samples are injected after the DNN output to jointly account for both communication and computation estimation errors. The DNN is then trained via backpropagation using the robust utility, thus implicitly learning the uncertainty distributions. Our results validate the enhanced robust delay performance of the joint uncertainty injection versus the classical DNN approach, especially in high channel and computational uncertainty regimes.
6/7/2024

Minimizing End-to-End Latency for Joint Source-Channel Coding Systems
Kaiyi Chi, Qianqian Yang, Yuanchao Shu, Zhaohui Yang, Zhiguo Shi
0
0
While existing studies have highlighted the advantages of deep learning (DL)-based joint source-channel coding (JSCC) schemes in enhancing transmission efficiency, they often overlook the crucial aspect of resource management during the deployment phase. In this paper, we propose an approach to minimize the transmission latency in an uplink JSCC-based system. We first analyze the correlation between end-to-end latency and task performance, based on which the end-to-end delay model for each device is established. Then, we formulate a non-convex optimization problem aiming at minimizing the maximum end-to-end latency across all devices, which is proved to be NP-hard. We then transform the original problem into a more tractable one, from which we derive the closed form solution on the optimal compression ratio, truncation threshold selection policy, and resource allocation strategy. We further introduce a heuristic algorithm with low complexity, leveraging insights from the structure of the optimal solution. Simulation results demonstrate that both the proposed optimal algorithm and the heuristic algorithm significantly reduce end-to-end latency. Notably, the proposed heuristic algorithm achieves nearly the same performance to the optimal solution but with considerably lower computational complexity.
4/1/2024

Joint Speaker Features Learning for Audio-visual Multichannel Speech Separation and Recognition
Guinan Li, Jiajun Deng, Youjun Chen, Mengzhe Geng, Shujie Hu, Zhe Li, Zengrui Jin, Tianzi Wang, Xurong Xie, Helen Meng, Xunying Liu
0
0
This paper proposes joint speaker feature learning methods for zero-shot adaptation of audio-visual multichannel speech separation and recognition systems. xVector and ECAPA-TDNN speaker encoders are connected using purpose-built fusion blocks and tightly integrated with the complete system training. Experiments conducted on LRS3-TED data simulated multichannel overlapped speech suggest that joint speaker feature learning consistently improves speech separation and recognition performance over the baselines without joint speaker feature estimation. Further analyses reveal performance improvements are strongly correlated with increased inter-speaker discrimination measured using cosine similarity. The best-performing joint speaker feature learning adapted system outperformed the baseline fine-tuned WavLM model by statistically significant WER reductions of 21.6% and 25.3% absolute (67.5% and 83.5% relative) on Dev and Test sets after incorporating WavLM features and video modality.
6/17/2024
🗣️
Semantic Communications for Speech Recognition
Zhenzi Weng, Zhijin Qin, Geoffrey Ye Li
0
0
The traditional communications transmit all the source data represented by bits, regardless of the content of source and the semantic information required by the receiver. However, in some applications, the receiver only needs part of the source data that represents critical semantic information, which prompts to transmit the application-related information, especially when bandwidth resources are limited. In this paper, we consider a semantic communication system for speech recognition by designing the transceiver as an end-to-end (E2E) system. Particularly, a deep learning (DL)-enabled semantic communication system, named DeepSC-SR, is developed to learn and extract text-related semantic features at the transmitter, which motivates the system to transmit much less than the source speech data without performance degradation. Moreover, in order to facilitate the proposed DeepSC-SR for dynamic channel environments, we investigate a robust model to cope with various channel environments without requiring retraining. The simulation results demonstrate that our proposed DeepSC-SR outperforms the traditional communication systems in terms of the speech recognition metrics, such as character-error-rate and word-error-rate, and is more robust to channel variations, especially in the low signal-to-noise (SNR) regime.
4/30/2024