Deep Transformer Network for Monocular Pose Estimation of Ship-Based UAV

0

Sign in to get full access
Overview
- This paper presents a deep transformer network for monocular pose estimation of a ship-based unmanned aerial vehicle (UAV).
- The authors use synthetic data generated from virtual environments to train the network, which can accurately estimate the 6D pose of the UAV relative to the ship.
- The proposed approach aims to address the challenges of monocular pose estimation in real-world scenarios, such as variable lighting conditions and occlusions.
Plain English Explanation
The research paper describes a new Deep Transformer Network for Monocular Pose Estimation of Ship-Based UAV. The researchers developed a deep learning model that can accurately determine the 3D position and orientation (known as 6D pose) of a UAV relative to the ship it is launched from, using only a single camera on the UAV.
This is a challenging problem because the UAV's appearance can change dramatically depending on factors like the lighting, viewing angle, and whether parts of the UAV are obscured by the ship. To overcome these challenges, the researchers used computer-generated virtual environments to create a large dataset of realistic UAV images. They then trained a deep neural network, specifically a transformer model, to analyze these synthetic images and learn to estimate the UAV's pose.
The key advantage of this approach is that it allows the model to be trained on a diverse set of scenarios without needing to collect and label thousands of real-world images, which would be time-consuming and expensive. By using the virtual environments, the researchers were able to generate unlimited training data and optimize the model's performance.
The DeepKalPose and TransPose papers also explore similar deep learning approaches for 6D object pose estimation, though in different contexts.
Technical Explanation
The paper proposes a deep transformer network for monocular pose estimation of a ship-based UAV. The key components of the technical approach are:
-
Virtual Environment Generation: The authors created photorealistic virtual environments using computer graphics tools to simulate the appearance of the ship and UAV under various lighting conditions, viewing angles, and occlusion scenarios.
-
Synthetic Data Collection: They generated a large dataset of UAV images and corresponding 6D pose labels by rendering the virtual environments. This synthetic data was used to train the deep learning model.
-
Transformer-based Architecture: The core of the model is a transformer-based network that takes a monocular image of the UAV as input and outputs its 6D pose relative to the ship. The transformer architecture allows the model to effectively capture the complex spatial relationships between the UAV and its surrounding environment.
-
Training and Evaluation: The researchers trained and evaluated their model using standard machine learning techniques. They compared its performance to other state-of-the-art methods for 6D pose estimation, demonstrating that their approach achieves superior accuracy.
The Localization Through Particle Filter Powered Neural Network and Attention-Based Deep Learning Architecture for Real-Time papers explore related techniques for object localization and pose estimation using deep learning.
Critical Analysis
The paper presents a novel and promising approach for monocular pose estimation of ship-based UAVs. However, there are a few potential limitations and areas for further research:
-
Reliance on Synthetic Data: While the use of virtual environments enables the generation of large, diverse training datasets, it is unclear how well the model will generalize to real-world scenarios. The authors should consider ways to bridge the gap between synthetic and real-world data, such as using techniques like domain adaptation.
-
Evaluation on Real-World Data: The paper focuses primarily on evaluating the model's performance on synthetic test data. It would be valuable to see how the model performs on real-world UAV images captured in actual ship-based scenarios.
-
Temporal Aspects: The current model treats each frame independently, but incorporating temporal information (e.g., through the DeepKalPose approach) could potentially improve the pose estimation accuracy and robustness.
-
Environmental Factors: The paper does not extensively discuss the impact of environmental factors, such as wind, waves, and ship motion, on the UAV's pose. Incorporating these real-world considerations into the virtual environments and the model design could enhance the practical applicability of the approach.
Despite these potential areas for improvement, the paper presents a valuable contribution to the field of monocular pose estimation, particularly in the context of ship-based UAV applications. The use of synthetic data and transformer-based architecture shows promise and could inspire further research in this direction.
Conclusion
The research paper introduces a deep transformer network for monocular pose estimation of a ship-based UAV. By leveraging synthetic data generated from virtual environments, the authors have developed a model that can accurately estimate the 6D pose of the UAV relative to the ship, even in challenging real-world scenarios.
This work has the potential to significantly impact the development of autonomous ship-based UAV systems, where precise localization and pose estimation are critical for tasks like landing, docking, and coordinated operations. The use of deep learning and transformer-based architectures demonstrates the power of these techniques for solving complex computer vision problems in the maritime domain.
While the paper highlights some limitations and areas for further research, it represents an important step forward in the field of monocular pose estimation and can inspire future work in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deep Transformer Network for Monocular Pose Estimation of Ship-Based UAV
Maneesha Wickramasuriya, Taeyoung Lee, Murray Snyder
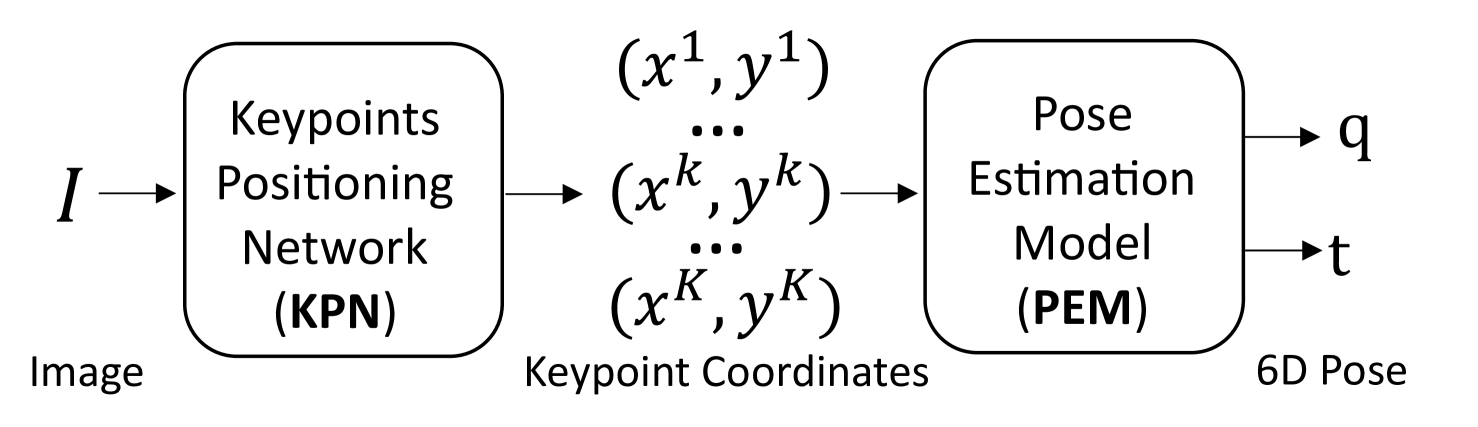
This paper introduces a deep transformer network for estimating the relative 6D pose of a Unmanned Aerial Vehicle (UAV) with respect to a ship using monocular images. A synthetic dataset of ship images is created and annotated with 2D keypoints of multiple ship parts. A Transformer Neural Network model is trained to detect these keypoints and estimate the 6D pose of each part. The estimates are integrated using Bayesian fusion. The model is tested on synthetic data and in-situ flight experiments, demonstrating robustness and accuracy in various lighting conditions. The position estimation error is approximately 0.8% and 1.0% of the distance to the ship for the synthetic data and the flight experiments, respectively. The method has potential applications for ship-based autonomous UAV landing and navigation.
Read more6/14/2024
0
Deep Learning Powered Estimate of The Extrinsic Parameters on Unmanned Surface Vehicles
Yi Shen, Hao Liu, Chang Zhou, Wentao Wang, Zijun Gao, Qi Wang
Unmanned Surface Vehicles (USVs) are pivotal in marine exploration, but their sensors' accuracy is compromised by the dynamic marine environment. Traditional calibration methods fall short in these conditions. This paper introduces a deep learning architecture that predicts changes in the USV's dynamic metacenter and refines sensors' extrinsic parameters in real time using a Time-Sequence General Regression Neural Network (GRNN) with Euler angles as input. Simulation data from Unity3D ensures robust training and testing. Experimental results show that the Time-Sequence GRNN achieves the lowest mean squared error (MSE) loss, outperforming traditional neural networks. This method significantly enhances sensor calibration for USVs, promising improved data accuracy in challenging maritime conditions. Future work will refine the network and validate results with real-world data.
Read more6/10/2024
📈
0
UMono: Physical Model Informed Hybrid CNN-Transformer Framework for Underwater Monocular Depth Estimation
Jian Wang, Jing Wang, Shenghui Rong, Bo He
Underwater monocular depth estimation serves as the foundation for tasks such as 3D reconstruction of underwater scenes. However, due to the influence of light and medium, the underwater environment undergoes a distinctive imaging process, which presents challenges in accurately estimating depth from a single image. The existing methods fail to consider the unique characteristics of underwater environments, leading to inadequate estimation results and limited generalization performance. Furthermore, underwater depth estimation requires extracting and fusing both local and global features, which is not fully explored in existing methods. In this paper, an end-to-end learning framework for underwater monocular depth estimation called UMono is presented, which incorporates underwater image formation model characteristics into network architecture, and effectively utilize both local and global features of underwater image. Experimental results demonstrate that the proposed method is effective for underwater monocular depth estimation and outperforms the existing methods in both quantitative and qualitative analyses.
Read more7/26/2024
0
Domain Generalization for In-Orbit 6D Pose Estimation
Antoine Legrand, Renaud Detry, Christophe De Vleeschouwer
We address the problem of estimating the relative 6D pose, i.e., position and orientation, of a target spacecraft, from a monocular image, a key capability for future autonomous Rendezvous and Proximity Operations. Due to the difficulty of acquiring large sets of real images, spacecraft pose estimation networks are exclusively trained on synthetic ones. However, because those images do not capture the illumination conditions encountered in orbit, pose estimation networks face a domain gap problem, i.e., they do not generalize to real images. Our work introduces a method that bridges this domain gap. It relies on a novel, end-to-end, neural-based architecture as well as a novel learning strategy. This strategy improves the domain generalization abilities of the network through multi-task learning and aggressive data augmentation policies, thereby enforcing the network to learn domain-invariant features. We demonstrate that our method effectively closes the domain gap, achieving state-of-the-art accuracy on the widespread SPEED+ dataset. Finally, ablation studies assess the impact of key components of our method on its generalization abilities.
Read more6/18/2024