An Attention-Based Deep Learning Architecture for Real-Time Monocular Visual Odometry: Applications to GPS-free Drone Navigation
2404.17745
0
0
🤿
Abstract
Drones are increasingly used in fields like industry, medicine, research, disaster relief, defense, and security. Technical challenges, such as navigation in GPS-denied environments, hinder further adoption. Research in visual odometry is advancing, potentially solving GPS-free navigation issues. Traditional visual odometry methods use geometry-based pipelines which, while popular, often suffer from error accumulation and high computational demands. Recent studies utilizing deep neural networks (DNNs) have shown improved performance, addressing these drawbacks. Deep visual odometry typically employs convolutional neural networks (CNNs) and sequence modeling networks like recurrent neural networks (RNNs) to interpret scenes and deduce visual odometry from video sequences. This paper presents a novel real-time monocular visual odometry model for drones, using a deep neural architecture with a self-attention module. It estimates the ego-motion of a camera on a drone, using consecutive video frames. An inference utility processes the live video feed, employing deep learning to estimate the drone's trajectory. The architecture combines a CNN for image feature extraction and a long short-term memory (LSTM) network with a multi-head attention module for video sequence modeling. Tested on two visual odometry datasets, this model converged 48% faster than a previous RNN model and showed a 22% reduction in mean translational drift and a 12% improvement in mean translational absolute trajectory error, demonstrating enhanced robustness to noise.
Create account to get full access
Overview
- Drones are increasingly used in various fields, but technical challenges like navigation in GPS-denied environments hinder further adoption.
- Research in visual odometry is advancing, potentially solving GPS-free navigation issues.
- Traditional visual odometry methods often suffer from error accumulation and high computational demands.
- Recent studies using deep neural networks (DNNs) have shown improved performance, addressing these drawbacks.
Plain English Explanation
Drones are becoming more and more common in industries like manufacturing, healthcare, and disaster response. However, there are still some technical problems that make it hard to use drones in certain situations. One big issue is that drones can't always rely on GPS to figure out where they are, which is a problem in places where GPS signals are blocked or unreliable.
Researchers have been working on a technique called visual odometry to help drones navigate without GPS. Visual odometry uses cameras on the drone to track its movement by analyzing the video footage. Traditional visual odometry methods have had some issues, like gradually building up errors over time and requiring a lot of computing power.
But recent studies have shown that using deep learning, a type of artificial intelligence, can help solve these problems. Deep learning models, which are inspired by the way the human brain works, are able to process the video footage more efficiently and accurately than traditional methods. This allows the drone to better estimate its own movement and position, even in GPS-denied environments.
Technical Explanation
This paper presents a new deep neural network architecture for real-time monocular visual odometry on drones. The model uses a convolutional neural network (CNN) to extract visual features from consecutive video frames, and a long short-term memory (LSTM) network with a multi-head attention module to model the temporal sequence and estimate the drone's ego-motion.
The CNN component learns to identify key visual landmarks in the video, while the LSTM and attention module analyze how those landmarks change over time to deduce the drone's movement. The attention mechanism allows the model to focus on the most relevant visual cues when estimating the pose.
Tested on two standard visual odometry datasets, this model was able to converge 48% faster than a previous recurrent neural network (RNN) approach, and showed a 22% reduction in mean translational drift and a 12% improvement in mean translational absolute trajectory error. This demonstrates the model's enhanced robustness to noise and other challenges compared to prior work.
Critical Analysis
While this model shows promising results, the authors acknowledge some limitations. The experiments were conducted in controlled lab settings, and further testing is needed to evaluate real-world performance in diverse environmental conditions. Additionally, the model only uses monocular video input, whereas incorporating inertial measurement unit (IMU) data could potentially improve accuracy and robustness.
Another area for future research is leveraging edge detection neural networks to enhance the visual feature extraction component of the model. This could lead to more reliable landmark detection and tracking, further improving the visual odometry estimates.
Overall, this work demonstrates the potential of deep learning techniques to advance drone navigation in GPS-denied environments. However, continued research and real-world testing will be necessary to fully realize the benefits of this approach.
Conclusion
This paper presents a novel deep neural network architecture for real-time monocular visual odometry on drones. By combining convolutional neural networks, long short-term memory, and attention mechanisms, the model is able to efficiently and accurately estimate a drone's ego-motion using only video input. Compared to prior techniques, this approach shows improved performance in terms of convergence speed and error reduction, indicating its potential to enhance drone navigation in GPS-denied scenarios.
While further research is needed to fully validate the model's real-world capabilities, this work represents an important step forward in addressing a key technical challenge hindering the broader adoption of drone technology across various industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Self-Supervised Geometry-Guided Initialization for Robust Monocular Visual Odometry
Takayuki Kanai, Igor Vasiljevic, Vitor Guizilini, Kazuhiro Shintani
0
0
Monocular visual odometry is a key technology in a wide variety of autonomous systems. Relative to traditional feature-based methods, that suffer from failures due to poor lighting, insufficient texture, large motions, etc., recent learning-based SLAM methods exploit iterative dense bundle adjustment to address such failure cases and achieve robust accurate localization in a wide variety of real environments, without depending on domain-specific training data. However, despite its potential, learning-based SLAM still struggles with scenarios involving large motion and object dynamics. In this paper, we diagnose key weaknesses in a popular learning-based SLAM model (DROID-SLAM) by analyzing major failure cases on outdoor benchmarks and exposing various shortcomings of its optimization process. We then propose the use of self-supervised priors leveraging a frozen large-scale pre-trained monocular depth estimation to initialize the dense bundle adjustment process, leading to robust visual odometry without the need to fine-tune the SLAM backbone. Despite its simplicity, our proposed method demonstrates significant improvements on KITTI odometry, as well as the challenging DDAD benchmark. Code and pre-trained models will be released upon publication.
6/4/2024

Vision Transformers for End-to-End Vision-Based Quadrotor Obstacle Avoidance
Anish Bhattacharya, Nishanth Rao, Dhruv Parikh, Pratik Kunapuli, Nikolai Matni, Vijay Kumar
0
0
We demonstrate the capabilities of an attention-based end-to-end approach for high-speed quadrotor obstacle avoidance in dense, cluttered environments, with comparison to various state-of-the-art architectures. Quadrotor unmanned aerial vehicles (UAVs) have tremendous maneuverability when flown fast; however, as flight speed increases, traditional vision-based navigation via independent mapping, planning, and control modules breaks down due to increased sensor noise, compounding errors, and increased processing latency. Thus, learning-based, end-to-end planning and control networks have shown to be effective for online control of these fast robots through cluttered environments. We train and compare convolutional, U-Net, and recurrent architectures against vision transformer models for depth-based end-to-end control, in a photorealistic, high-physics-fidelity simulator as well as in hardware, and observe that the attention-based models are more effective as quadrotor speeds increase, while recurrent models with many layers provide smoother commands at lower speeds. To the best of our knowledge, this is the first work to utilize vision transformers for end-to-end vision-based quadrotor control.
5/20/2024
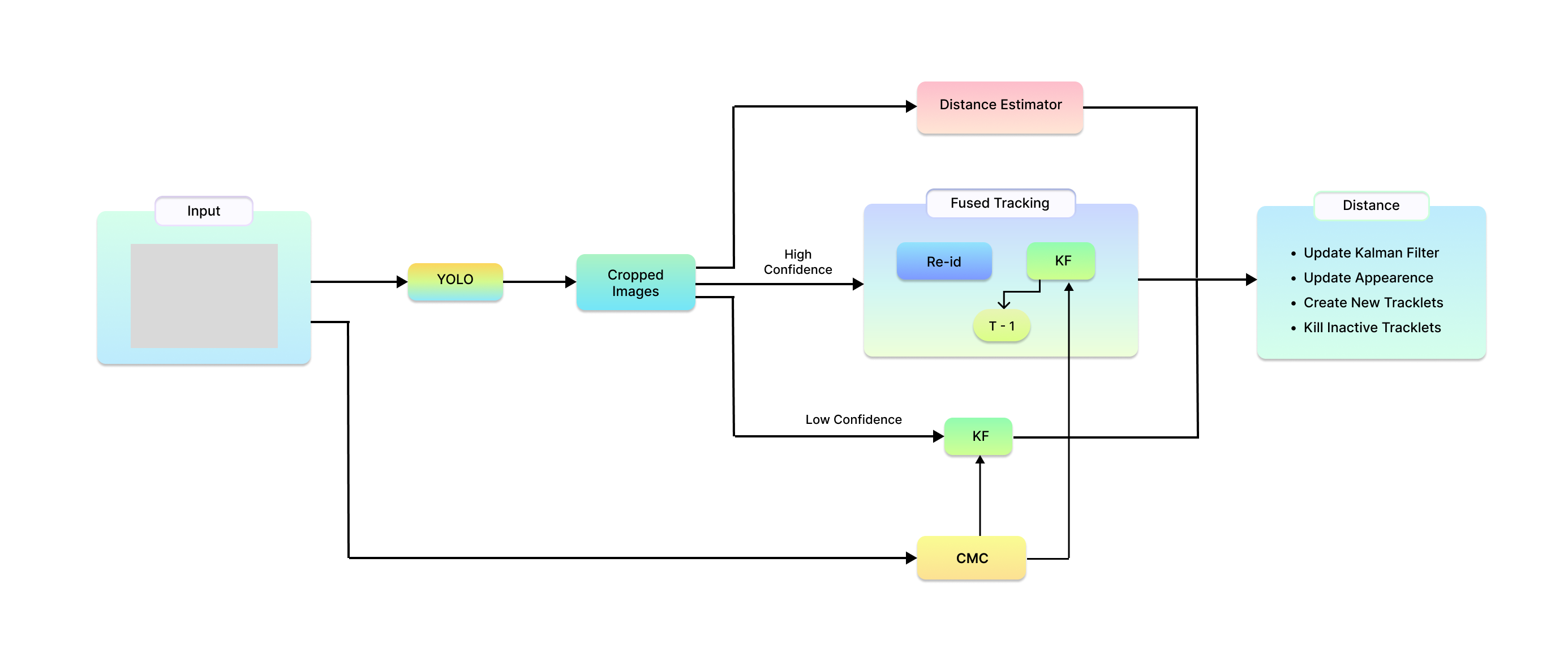
Ensuring UAV Safety: A Vision-only and Real-time Framework for Collision Avoidance Through Object Detection, Tracking, and Distance Estimation
Vasileios Karampinis, Anastasios Arsenos, Orfeas Filippopoulos, Evangelos Petrongonas, Christos Skliros, Dimitrios Kollias, Stefanos Kollias, Athanasios Voulodimos
0
0
In the last twenty years, unmanned aerial vehicles (UAVs) have garnered growing interest due to their expanding applications in both military and civilian domains. Detecting non-cooperative aerial vehicles with efficiency and estimating collisions accurately are pivotal for achieving fully autonomous aircraft and facilitating Advanced Air Mobility (AAM). This paper presents a deep-learning framework that utilizes optical sensors for the detection, tracking, and distance estimation of non-cooperative aerial vehicles. In implementing this comprehensive sensing framework, the availability of depth information is essential for enabling autonomous aerial vehicles to perceive and navigate around obstacles. In this work, we propose a method for estimating the distance information of a detected aerial object in real time using only the input of a monocular camera. In order to train our deep learning components for the object detection, tracking and depth estimation tasks we utilize the Amazon Airborne Object Tracking (AOT) Dataset. In contrast to previous approaches that integrate the depth estimation module into the object detector, our method formulates the problem as image-to-image translation. We employ a separate lightweight encoder-decoder network for efficient and robust depth estimation. In a nutshell, the object detection module identifies and localizes obstacles, conveying this information to both the tracking module for monitoring obstacle movement and the depth estimation module for calculating distances. Our approach is evaluated on the Airborne Object Tracking (AOT) dataset which is the largest (to the best of our knowledge) air-to-air airborne object dataset.
5/17/2024

Self-supervised Pretraining and Finetuning for Monocular Depth and Visual Odometry
Boris Chidlovskii, Leonid Antsfeld
0
0
For the task of simultaneous monocular depth and visual odometry estimation, we propose learning self-supervised transformer-based models in two steps. Our first step consists in a generic pretraining to learn 3D geometry, using cross-view completion objective (CroCo), followed by self-supervised finetuning on non-annotated videos. We show that our self-supervised models can reach state-of-the-art performance 'without bells and whistles' using standard components such as visual transformers, dense prediction transformers and adapters. We demonstrate the effectiveness of our proposed method by running evaluations on six benchmark datasets, both static and dynamic, indoor and outdoor, with synthetic and real images. For all datasets, our method outperforms state-of-the-art methods, in particular for depth prediction task.
6/18/2024