DeepPavlov at SemEval-2024 Task 8: Leveraging Transfer Learning for Detecting Boundaries of Machine-Generated Texts
2405.10629
0
0
Abstract
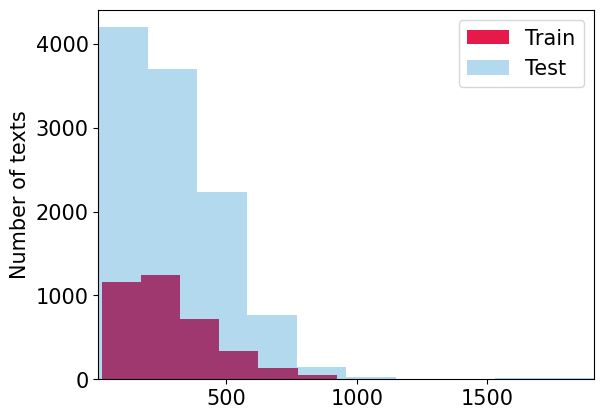
The Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection shared task in the SemEval-2024 competition aims to tackle the problem of misusing collaborative human-AI writing. Although there are a lot of existing detectors of AI content, they are often designed to give a binary answer and thus may not be suitable for more nuanced problem of finding the boundaries between human-written and machine-generated texts, while hybrid human-AI writing becomes more and more popular. In this paper, we address the boundary detection problem. Particularly, we present a pipeline for augmenting data for supervised fine-tuning of DeBERTaV3. We receive new best MAE score, according to the leaderboard of the competition, with this pipeline.
Create account to get full access
Overview
- This paper describes the DeepPavlov team's approach to the SemEval-2024 Task 8, which focuses on detecting the boundaries of machine-generated texts.
- The researchers leveraged transfer learning techniques to develop a model that can effectively distinguish between human-written and AI-generated text.
- The proposed solution was evaluated on a diverse dataset, showcasing its robustness and potential real-world applications.
Plain English Explanation
Technical Explanation
The researchers evaluated their model on the SemEval-2024 Task 8 dataset, which includes text samples from multiple domains and languages. This multi-domain, multi-model, and multilingual dataset was designed to test the generalization capabilities of text detection models. The DeepPavlov team's model achieved strong performance, demonstrating its ability to accurately identify the boundaries of machine-generated text across diverse contexts.
Critical Analysis
While the proposed approach shows promising results, the paper acknowledges some potential limitations. For example, the researchers note that the model's performance may be influenced by the quality and quantity of the training data. Additionally, further research is needed to explore the effectiveness of their model in more challenging or adversarial settings, where AI-generated text may be intentionally designed to evade detection.
Conclusion
The DeepPavlov team's work on the SemEval-2024 Task 8 demonstrates the potential of transfer learning techniques in developing robust and generalizable models for detecting machine-generated text. As the use of AI-generated content continues to grow, tools like the one proposed in this paper could play a crucial role in maintaining the integrity of online information and ensuring transparency around the origin of textual content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
PetKaz at SemEval-2024 Task 8: Can Linguistics Capture the Specifics of LLM-generated Text?
Kseniia Petukhova, Roman Kazakov, Ekaterina Kochmar
0
0
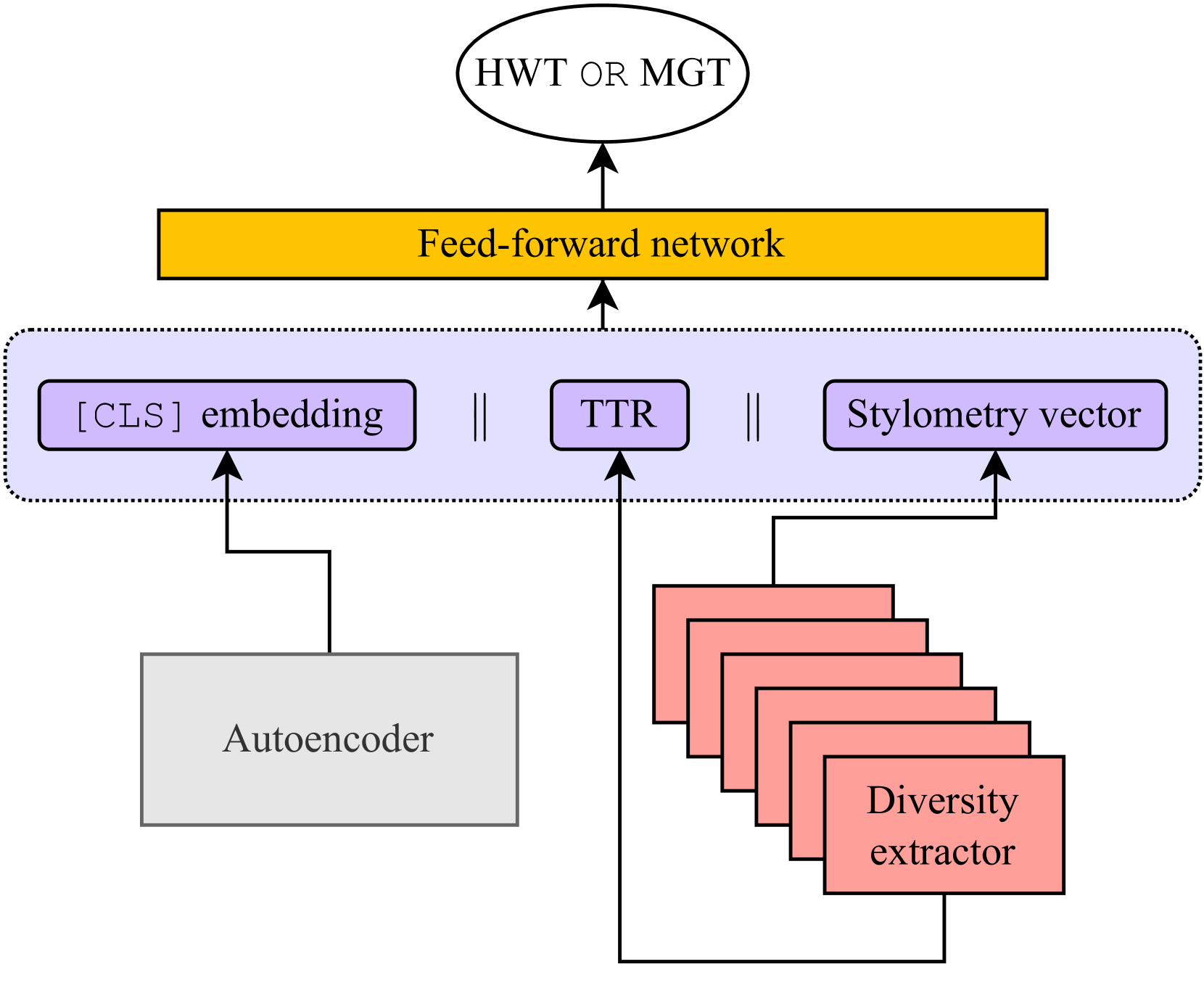
In this paper, we present our submission to the SemEval-2024 Task 8 Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection, focusing on the detection of machine-generated texts (MGTs) in English. Specifically, our approach relies on combining embeddings from the RoBERTa-base with diversity features and uses a resampled training set. We score 12th from 124 in the ranking for Subtask A (monolingual track), and our results show that our approach is generalizable across unseen models and domains, achieving an accuracy of 0.91.
4/9/2024

Transformer and Hybrid Deep Learning Based Models for Machine-Generated Text Detection
Teodor-George Marchitan, Claudiu Creanga, Liviu P. Dinu
0
0
This paper describes the approach of the UniBuc - NLP team in tackling the SemEval 2024 Task 8: Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection. We explored transformer-based and hybrid deep learning architectures. For subtask B, our transformer-based model achieved a strong textbf{second-place} out of $77$ teams with an accuracy of textbf{86.95%}, demonstrating the architecture's suitability for this task. However, our models showed overfitting in subtask A which could potentially be fixed with less fine-tunning and increasing maximum sequence length. For subtask C (token-level classification), our hybrid model overfit during training, hindering its ability to detect transitions between human and machine-generated text.
5/29/2024
🔎
AI-generated text boundary detection with RoFT
Laida Kushnareva, Tatiana Gaintseva, German Magai, Serguei Barannikov, Dmitry Abulkhanov, Kristian Kuznetsov, Eduard Tulchinskii, Irina Piontkovskaya, Sergey Nikolenko
0
0
Due to the rapid development of large language models, people increasingly often encounter texts that may start as written by a human but continue as machine-generated. Detecting the boundary between human-written and machine-generated parts of such texts is a challenging problem that has not received much attention in literature. We attempt to bridge this gap and examine several ways to adapt state of the art artificial text detection classifiers to the boundary detection setting. We push all detectors to their limits, using the Real or Fake text benchmark that contains short texts on several topics and includes generations of various language models. We use this diversity to deeply examine the robustness of all detectors in cross-domain and cross-model settings to provide baselines and insights for future research. In particular, we find that perplexity-based approaches to boundary detection tend to be more robust to peculiarities of domain-specific data than supervised fine-tuning of the RoBERTa model; we also find which features of the text confuse boundary detection algorithms and negatively influence their performance in cross-domain settings.
4/4/2024

KInIT at SemEval-2024 Task 8: Fine-tuned LLMs for Multilingual Machine-Generated Text Detection
Michal Spiegel, Dominik Macko
0
0
SemEval-2024 Task 8 is focused on multigenerator, multidomain, and multilingual black-box machine-generated text detection. Such a detection is important for preventing a potential misuse of large language models (LLMs), the newest of which are very capable in generating multilingual human-like texts. We have coped with this task in multiple ways, utilizing language identification and parameter-efficient fine-tuning of smaller LLMs for text classification. We have further used the per-language classification-threshold calibration to uniquely combine fine-tuned models predictions with statistical detection metrics to improve generalization of the system detection performance. Our submitted method achieved competitive results, ranking at the fourth place, just under 1 percentage point behind the winner.
6/18/2024