PetKaz at SemEval-2024 Task 8: Can Linguistics Capture the Specifics of LLM-generated Text?
2404.05483
0
0
Abstract
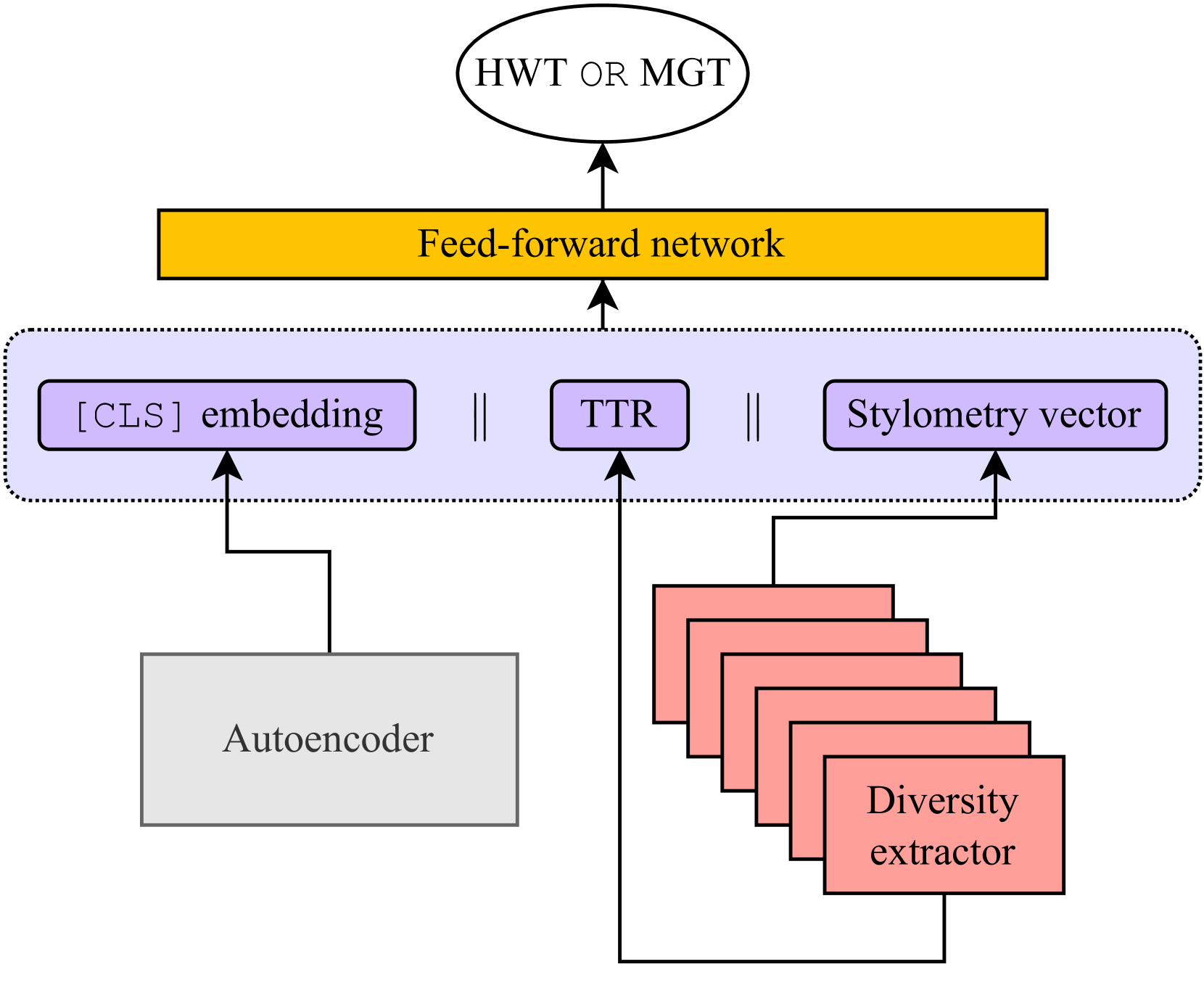
In this paper, we present our submission to the SemEval-2024 Task 8 Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection, focusing on the detection of machine-generated texts (MGTs) in English. Specifically, our approach relies on combining embeddings from the RoBERTa-base with diversity features and uses a resampled training set. We score 12th from 124 in the ranking for Subtask A (monolingual track), and our results show that our approach is generalizable across unseen models and domains, achieving an accuracy of 0.91.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores whether linguistic analysis can effectively capture the unique characteristics of text generated by large language models (LLMs).
- The authors present their work on the SemEval-2024 Task 8, which focuses on distinguishing LLM-generated text from human-written text.
- The paper explores the potential of linguistic features, such as syntactic patterns and lexical choices, to serve as reliable indicators of LLM-generated text.
Plain English Explanation
In this paper, the researchers investigate whether analyzing the linguistic properties of text can help identify text that was generated by large language models (LLMs), as opposed to being written by humans. LLMs are advanced AI systems that can produce human-like text, and the researchers wanted to see if the unique patterns and characteristics of LLM-generated text could be detected using linguistic analysis.
The researchers presented their work on a specific task called SemEval-2024 Task 8, which focused on distinguishing LLM-generated text from human-written text. They explored the idea that certain linguistic features, such as the way sentences are structured or the specific words and phrases used, might serve as reliable indicators of whether the text was produced by an LLM or a human. By understanding these linguistic differences, the researchers hoped to develop more effective ways to identify and differentiate LLM-generated content.
Technical Explanation
The paper presents the authors' approach to the SemEval-2024 Task 8, which aimed to distinguish LLM-generated text from human-written text. The authors explored the use of linguistic features, including [internal link: https://aimodels.fyi/papers/arxiv/petkaz-at-semeval-2024-task-3-advancing]syntactic patterns and lexical choices[/internal link], as potential markers of LLM-generated text.
The authors developed a system called PetKaz, which leveraged a range of linguistic features to classify text as either LLM-generated or human-written. The system incorporated [internal link: https://aimodels.fyi/papers/arxiv/auditing-large-language-models-enhanced-text-based]text-based auditing techniques[/internal link] and [internal link: https://aimodels.fyi/papers/arxiv/deciphering-textual-authenticity-generalized-strategy-through-lens]strategies for deciphering textual authenticity[/internal link] to identify the unique characteristics of LLM-generated text.
The authors evaluated their system on the SemEval-2024 Task 8 dataset and compared its performance to [internal link: https://aimodels.fyi/papers/arxiv/masontigers-at-semeval-2024-task-8-performance]other approaches[/internal link]. The results of their analysis provide insights into the potential and limitations of using linguistic features to detect LLM-generated text, which have implications for [internal link: https://aimodels.fyi/papers/arxiv/aadam-at-semeval-2024-task-1-augmentation]text-based augmentation[/internal link] and the development of more robust approaches to identifying machine-generated content.
Critical Analysis
The paper presents a thoughtful and well-designed approach to the SemEval-2024 Task 8, which is a challenging problem at the intersection of linguistics and large language model research. The authors' exploration of linguistic features as potential markers of LLM-generated text is a promising avenue of investigation, as it could lead to more effective and interpretable detection methods compared to purely statistical approaches.
However, the paper also acknowledges several limitations and areas for further research. For instance, the authors note that the linguistic features they used may not fully capture the nuances and complexities of LLM-generated text, and that more advanced techniques or combinations of features may be required to achieve higher levels of accuracy.
Additionally, the paper does not address the potential ethical implications of this research, such as the risks of developing overly effective detection systems that could be used to censor or limit the use of LLM-generated content. It is important for researchers in this field to consider the broader societal implications of their work and to engage in responsible, transparent, and inclusive dialogue with stakeholders.
Conclusion
Overall, this paper makes a valuable contribution to the growing body of research on distinguishing LLM-generated text from human-written text. The authors' exploration of linguistic features as potential markers of LLM-generated content represents an important step forward in understanding the unique characteristics of machine-generated language. While the results are promising, the paper also highlights the need for continued research and the consideration of ethical implications as this field of study progresses.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
SemEval-2024 Task 8: Multidomain, Multimodel and Multilingual Machine-Generated Text Detection
Yuxia Wang, Jonibek Mansurov, Petar Ivanov, Jinyan Su, Artem Shelmanov, Akim Tsvigun, Osama Mohammed Afzal, Tarek Mahmoud, Giovanni Puccetti, Thomas Arnold, Chenxi Whitehouse, Alham Fikri Aji, Nizar Habash, Iryna Gurevych, Preslav Nakov
0
0
We present the results and the main findings of SemEval-2024 Task 8: Multigenerator, Multidomain, and Multilingual Machine-Generated Text Detection. The task featured three subtasks. Subtask A is a binary classification task determining whether a text is written by a human or generated by a machine. This subtask has two tracks: a monolingual track focused solely on English texts and a multilingual track. Subtask B is to detect the exact source of a text, discerning whether it is written by a human or generated by a specific LLM. Subtask C aims to identify the changing point within a text, at which the authorship transitions from human to machine. The task attracted a large number of participants: subtask A monolingual (126), subtask A multilingual (59), subtask B (70), and subtask C (30). In this paper, we present the task, analyze the results, and discuss the system submissions and the methods they used. For all subtasks, the best systems used LLMs.
4/23/2024
New!DeepPavlov at SemEval-2024 Task 8: Leveraging Transfer Learning for Detecting Boundaries of Machine-Generated Texts
Anastasia Voznyuk, Vasily Konovalov
0
0
The Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection shared task in the SemEval-2024 competition aims to tackle the problem of misusing collaborative human-AI writing. Although there are a lot of existing detectors of AI content, they are often designed to give a binary answer and thus may not be suitable for more nuanced problem of finding the boundaries between human-written and machine-generated texts, while hybrid human-AI writing becomes more and more popular. In this paper, we address the boundary detection problem. Particularly, we present a pipeline for augmenting data for supervised fine-tuning of DeBERTaV3. We receive new best MAE score, according to the leaderboard of the competition, with this pipeline.
5/20/2024
MasonTigers at SemEval-2024 Task 8: Performance Analysis of Transformer-based Models on Machine-Generated Text Detection
Sadiya Sayara Chowdhury Puspo, Md Nishat Raihan, Dhiman Goswami, Al Nahian Bin Emran, Amrita Ganguly, Ozlem Uzuner
0
0
This paper presents the MasonTigers entry to the SemEval-2024 Task 8 - Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection. The task encompasses Binary Human-Written vs. Machine-Generated Text Classification (Track A), Multi-Way Machine-Generated Text Classification (Track B), and Human-Machine Mixed Text Detection (Track C). Our best performing approaches utilize mainly the ensemble of discriminator transformer models along with sentence transformer and statistical machine learning approaches in specific cases. Moreover, zero-shot prompting and fine-tuning of FLAN-T5 are used for Track A and B.
4/8/2024

Deciphering Textual Authenticity: A Generalized Strategy through the Lens of Large Language Semantics for Detecting Human vs. Machine-Generated Text
Mazal Bethany, Brandon Wherry, Emet Bethany, Nishant Vishwamitra, Anthony Rios, Peyman Najafirad
0
0
With the recent proliferation of Large Language Models (LLMs), there has been an increasing demand for tools to detect machine-generated text. The effective detection of machine-generated text face two pertinent problems: First, they are severely limited in generalizing against real-world scenarios, where machine-generated text is produced by a variety of generators, including but not limited to GPT-4 and Dolly, and spans diverse domains, ranging from academic manuscripts to social media posts. Second, existing detection methodologies treat texts produced by LLMs through a restrictive binary classification lens, neglecting the nuanced diversity of artifacts generated by different LLMs. In this work, we undertake a systematic study on the detection of machine-generated text in real-world scenarios. We first study the effectiveness of state-of-the-art approaches and find that they are severely limited against text produced by diverse generators and domains in the real world. Furthermore, t-SNE visualizations of the embeddings from a pretrained LLM's encoder show that they cannot reliably distinguish between human and machine-generated text. Based on our findings, we introduce a novel system, T5LLMCipher, for detecting machine-generated text using a pretrained T5 encoder combined with LLM embedding sub-clustering to address the text produced by diverse generators and domains in the real world. We evaluate our approach across 9 machine-generated text systems and 9 domains and find that our approach provides state-of-the-art generalization ability, with an average increase in F1 score on machine-generated text of 19.6% on unseen generators and domains compared to the top performing existing approaches and correctly attributes the generator of text with an accuracy of 93.6%.
4/4/2024