AI-generated text boundary detection with RoFT
2311.08349
0
0
🔎
Abstract
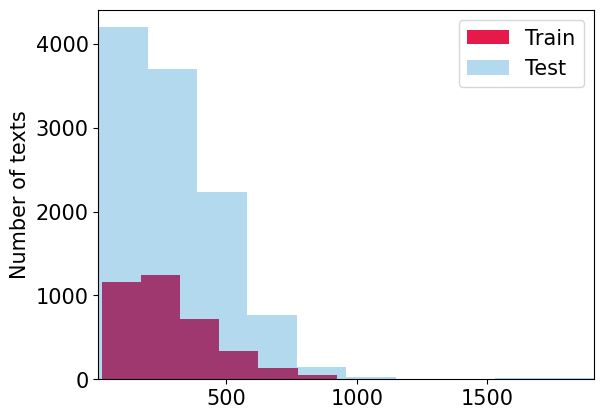
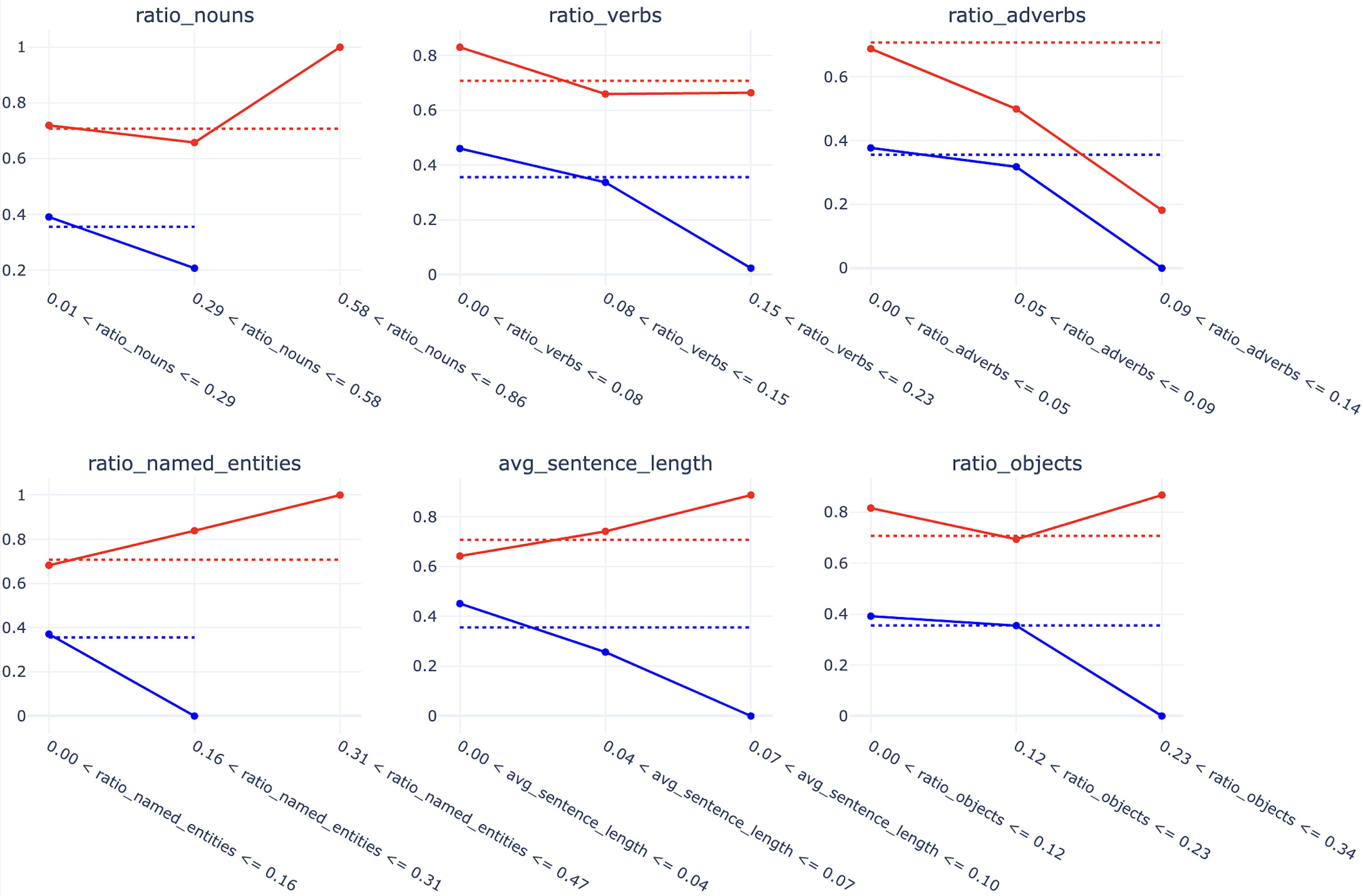
Due to the rapid development of large language models, people increasingly often encounter texts that may start as written by a human but continue as machine-generated. Detecting the boundary between human-written and machine-generated parts of such texts is a challenging problem that has not received much attention in literature. We attempt to bridge this gap and examine several ways to adapt state of the art artificial text detection classifiers to the boundary detection setting. We push all detectors to their limits, using the Real or Fake text benchmark that contains short texts on several topics and includes generations of various language models. We use this diversity to deeply examine the robustness of all detectors in cross-domain and cross-model settings to provide baselines and insights for future research. In particular, we find that perplexity-based approaches to boundary detection tend to be more robust to peculiarities of domain-specific data than supervised fine-tuning of the RoBERTa model; we also find which features of the text confuse boundary detection algorithms and negatively influence their performance in cross-domain settings.
Create account to get full access
Overview
- Rapid development of large language models has led to an increase in texts that mix human-written and machine-generated content.
- Detecting the boundary between these two parts of a text is a challenging problem that has not received much attention.
- The researchers attempt to address this gap by adapting state-of-the-art artificial text detection classifiers to the boundary detection setting.
- They use the Real or Fake text benchmark, which contains short texts on various topics generated by different language models, to deeply examine the robustness of all detectors.
Plain English Explanation
As language models like GPT-3 become more advanced, it's becoming easier for computers to generate human-like text. This means that people are increasingly encountering online content that starts off written by a person but then transitions into text generated by a machine. Identifying exactly where this transition happens, known as the "boundary" between human-written and machine-generated parts, is a difficult problem that hasn't been studied much.
The researchers in this paper tried to find ways to adapt existing AI systems that can detect whether text is real or fake (generated by a computer) to also be able to pinpoint the boundary between the human and machine-written sections. They used a special dataset called "Real or Fake" that contains short pieces of text on many different topics, some written by people and some generated by various language models. This allowed them to thoroughly test the boundary detection capabilities of their approaches across a wide range of content.
Technical Explanation
The researchers examined several techniques for adapting state-of-the-art artificial text detection classifiers, like the RoBERTa model, to perform boundary detection. They used the Real or Fake dataset, which contains short texts on topics like politics, science, and entertainment, some written by humans and others generated by different language models.
By testing the detectors on this diverse dataset, the researchers were able to deeply analyze their robustness in cross-domain and cross-model settings. They found that perplexity-based approaches, which look at how "surprised" a language model is by different parts of the text, tended to be more versatile than fine-tuning RoBERTa for the boundary detection task. The researchers also identified specific textual features that confuse the boundary detection algorithms and reduce their performance when applied to new domains.
Critical Analysis
The paper provides a thorough exploration of boundary detection techniques, but it acknowledges that more research is needed to improve performance, especially in challenging cross-domain scenarios. The authors mention that their findings are limited to the specific dataset and language models used, and that further testing on other benchmarks would be valuable.
One potential issue not discussed is the difficulty of obtaining high-quality datasets for training and evaluating boundary detection systems. Generating realistic mixed human-machine text at scale is a significant challenge. The researchers also do not delve into the societal implications of such technology, such as how it could be used to identify and mitigate the spread of "deepfakes" or other deceptive online content.
Conclusion
This paper takes an important step in advancing the field of boundary detection between human-written and machine-generated text. By rigorously testing several approaches on a diverse benchmark dataset, the researchers provide valuable insights into the strengths and weaknesses of different techniques. Their findings suggest that perplexity-based methods may be more robust than fine-tuned classifiers, and highlight specific textual features that confuse current boundary detection algorithms.
As large language models become more capable, the need for reliable boundary detection will only grow. This research lays the groundwork for further advancements that could help ensure the integrity of online information and protect against the spread of deceptive content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
DeepPavlov at SemEval-2024 Task 8: Leveraging Transfer Learning for Detecting Boundaries of Machine-Generated Texts
Anastasia Voznyuk, Vasily Konovalov
0
0
The Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection shared task in the SemEval-2024 competition aims to tackle the problem of misusing collaborative human-AI writing. Although there are a lot of existing detectors of AI content, they are often designed to give a binary answer and thus may not be suitable for more nuanced problem of finding the boundaries between human-written and machine-generated texts, while hybrid human-AI writing becomes more and more popular. In this paper, we address the boundary detection problem. Particularly, we present a pipeline for augmenting data for supervised fine-tuning of DeBERTaV3. We receive new best MAE score, according to the leaderboard of the competition, with this pipeline.
5/20/2024
🔎
Deepfake Text Detection in the Wild
Yafu Li, Qintong Li, Leyang Cui, Wei Bi, Zhilin Wang, Longyue Wang, Linyi Yang, Shuming Shi, Yue Zhang
0
0
Large language models (LLMs) have achieved human-level text generation, emphasizing the need for effective AI-generated text detection to mitigate risks like the spread of fake news and plagiarism. Existing research has been constrained by evaluating detection methods on specific domains or particular language models. In practical scenarios, however, the detector faces texts from various domains or LLMs without knowing their sources. To this end, we build a comprehensive testbed by gathering texts from diverse human writings and texts generated by different LLMs. Empirical results show challenges in distinguishing machine-generated texts from human-authored ones across various scenarios, especially out-of-distribution. These challenges are due to the decreasing linguistic distinctions between the two sources. Despite challenges, the top-performing detector can identify 86.54% out-of-domain texts generated by a new LLM, indicating the feasibility for application scenarios. We release our resources at https://github.com/yafuly/MAGE.
5/22/2024
Exploring the Limitations of Detecting Machine-Generated Text
Jad Doughman, Osama Mohammed Afzal, Hawau Olamide Toyin, Shady Shehata, Preslav Nakov, Zeerak Talat
0
0
Recent improvements in the quality of the generations by large language models have spurred research into identifying machine-generated text. Systems proposed for the task often achieve high performance. However, humans and machines can produce text in different styles and in different domains, and it remains unclear whether machine generated-text detection models favour particular styles or domains. In this paper, we critically examine the classification performance for detecting machine-generated text by evaluating on texts with varying writing styles. We find that classifiers are highly sensitive to stylistic changes and differences in text complexity, and in some cases degrade entirely to random classifiers. We further find that detection systems are particularly susceptible to misclassify easy-to-read texts while they have high performance for complex texts.
6/18/2024

CUDRT: Benchmarking the Detection of Human vs. Large Language Models Generated Texts
Zhen Tao, Zhiyu Li, Dinghao Xi, Wei Xu
0
0
The proliferation of large language models (LLMs) has significantly enhanced text generation capabilities across various industries. However, these models' ability to generate human-like text poses substantial challenges in discerning between human and AI authorship. Despite the effectiveness of existing AI-generated text detectors, their development is hindered by the lack of comprehensive, publicly available benchmarks. Current benchmarks are limited to specific scenarios, such as question answering and text polishing, and predominantly focus on English texts, failing to capture the diverse applications and linguistic nuances of LLMs. To address these limitations, this paper constructs a comprehensive bilingual benchmark in both Chinese and English to evaluate mainstream AI-generated text detectors. We categorize LLM text generation into five distinct operations: Create, Update, Delete, Rewrite, and Translate (CUDRT), encompassing all current LLMs activities. We also establish a robust benchmark evaluation framework to support scalable and reproducible experiments. For each CUDRT category, we have developed extensive datasets to thoroughly assess detector performance. By employing the latest mainstream LLMs specific to each language, our datasets provide a thorough evaluation environment. Extensive experimental results offer critical insights for optimizing AI-generated text detectors and suggest future research directions to improve detection accuracy and generalizability across various scenarios.
6/14/2024