DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
2405.04434
0
0
💬
Abstract
We present DeepSeek-V2, a strong Mixture-of-Experts (MoE) language model characterized by economical training and efficient inference. It comprises 236B total parameters, of which 21B are activated for each token, and supports a context length of 128K tokens. DeepSeek-V2 adopts innovative architectures including Multi-head Latent Attention (MLA) and DeepSeekMoE. MLA guarantees efficient inference through significantly compressing the Key-Value (KV) cache into a latent vector, while DeepSeekMoE enables training strong models at an economical cost through sparse computation. Compared with DeepSeek 67B, DeepSeek-V2 achieves significantly stronger performance, and meanwhile saves 42.5% of training costs, reduces the KV cache by 93.3%, and boosts the maximum generation throughput to 5.76 times. We pretrain DeepSeek-V2 on a high-quality and multi-source corpus consisting of 8.1T tokens, and further perform Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to fully unlock its potential. Evaluation results show that, even with only 21B activated parameters, DeepSeek-V2 and its chat versions still achieve top-tier performance among open-source models.
Create account to get full access
Overview
- DeepSeek-V2 is a powerful Mixture-of-Experts (MoE) language model with efficient training and inference
- It has 236 billion total parameters, with 21 billion activated per token, and supports 128,000 token contexts
- Key innovations include Multi-head Latent Attention (MLA) and the DeepSeekMoE architecture
Plain English Explanation
DeepSeek-V2 is a new type of large language model that aims to be both powerful and efficient. It has a massive number of total parameters - 236 billion - but it uses a clever technique called Mixture-of-Experts (MoE) to only activate 21 billion of those parameters for each input token. This allows it to maintain strong performance while being more economical to train and run.
The model also includes two innovative architectural components. Multi-head Latent Attention (MLA) compresses the model's memory cache, making inference faster. And the DeepSeekMoE design enables training powerful models at lower cost through sparse computation.
Compared to the previous DeepSeek 67B model, DeepSeek-V2 achieves significantly better performance while reducing training costs by 42.5%, shrinking the memory cache by 93.3%, and boosting generation speed by over 5 times. This makes it an attractive option for applications that demand both capability and efficiency.
Technical Explanation
DeepSeek-V2 is a large-scale Mixture-of-Experts (MoE) language model with several novel architectural components. It has a total of 236 billion parameters, but only activates 21 billion of those for each input token, allowing it to maintain strong performance with more economical training and inference.
The key innovations in DeepSeek-V2 are the Multi-head Latent Attention (MLA) module and the DeepSeekMoE architecture. MLA compresses the model's key-value cache into a low-dimensional latent representation, significantly reducing memory usage and boosting inference speed. DeepSeekMoE enables efficient training of powerful MoE models through sparse computation.
The researchers pretrain DeepSeek-V2 on a large 8.1 trillion token corpus, and then further fine-tune it through Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to unlock its full potential. Evaluation shows that even with just 21 billion active parameters, DeepSeek-V2 and its chat-oriented versions achieve top-tier performance among open-source language models.
Critical Analysis
The researchers provide a thorough technical explanation of the DeepSeek-V2 model and its innovations. However, the paper does not delve deeply into the potential limitations or challenges of the approach.
For example, while the MLA and DeepSeekMoE components seem promising, more analysis could be done on their effectiveness and any trade-offs involved. The researchers also do not explore potential biases or safety issues that may arise from training such a large language model on a diverse web-crawled corpus.
Additionally, the performance gains are impressive, but it would be valuable to see more detailed comparisons to other state-of-the-art models, including benchmarks on a wider range of tasks beyond just the model's own internal evaluations.
Overall, the paper presents an interesting advance in language model architecture and efficiency, but could benefit from a more critical and comprehensive discussion of the approach's strengths, weaknesses, and areas for further research.
Conclusion
DeepSeek-V2 is a powerful new language model that combines innovations in Mixture-of-Experts architectures, attention mechanisms, and training techniques to achieve strong performance with greater efficiency compared to previous models.
The DeepSeekMoE design and Multi-head Latent Attention module enable DeepSeek-V2 to be both capable and cost-effective to train and run. This makes it a promising candidate for real-world applications that demand high-quality language understanding and generation.
While the technical details are impressive, the paper could be strengthened by a more thorough critical analysis of the model's potential limitations and areas for future research. Overall, DeepSeek-V2 represents an important advance in the field of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
DeepSeek-AI, Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y. Wu, Yukun Li, Huazuo Gao, Shirong Ma, Wangding Zeng, Xiao Bi, Zihui Gu, Hanwei Xu, Damai Dai, Kai Dong, Liyue Zhang, Yishi Piao, Zhibin Gou, Zhenda Xie, Zhewen Hao, Bingxuan Wang, Junxiao Song, Deli Chen, Xin Xie, Kang Guan, Yuxiang You, Aixin Liu, Qiushi Du, Wenjun Gao, Xuan Lu, Qinyu Chen, Yaohui Wang, Chengqi Deng, Jiashi Li, Chenggang Zhao, Chong Ruan, Fuli Luo, Wenfeng Liang
0
0
We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K. In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks.
6/19/2024
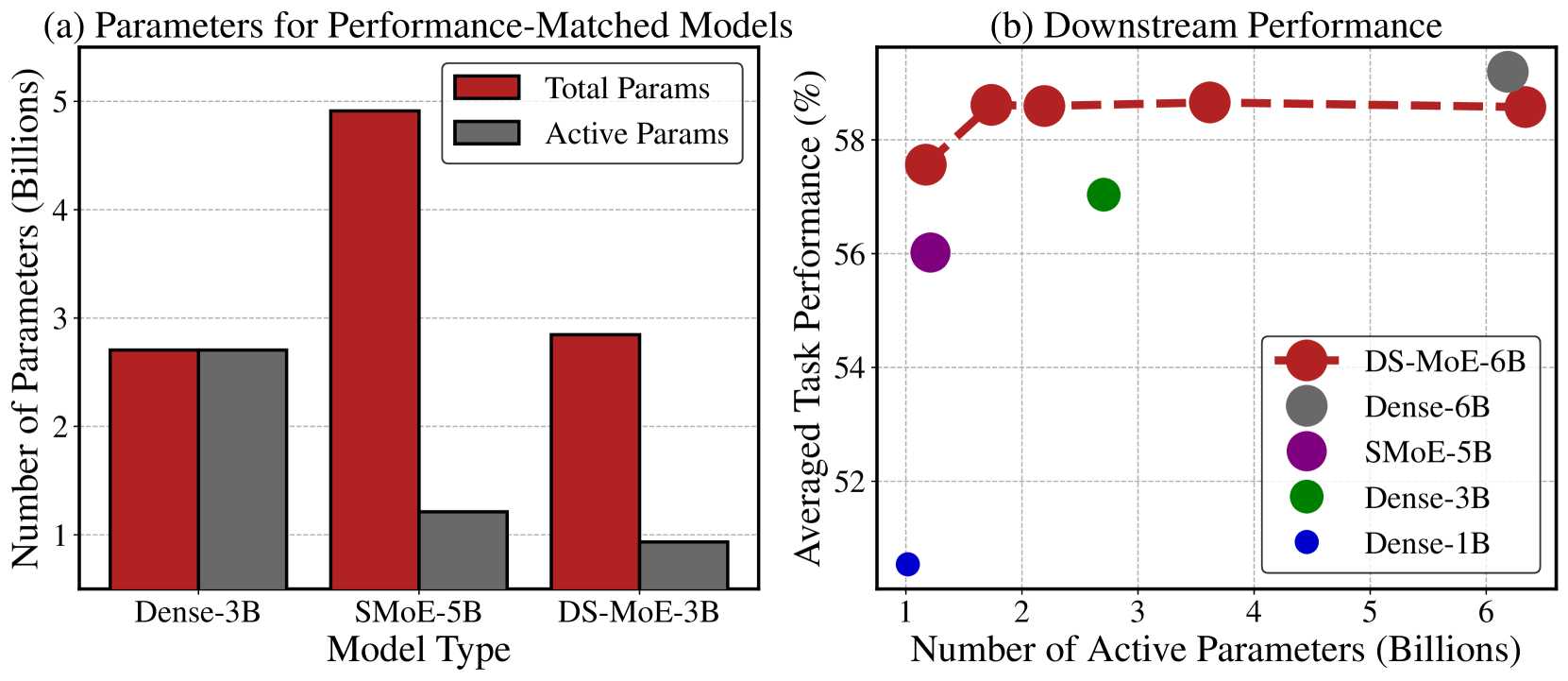
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, Rameswar Panda
0
0
Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86times$ faster than similar dense models like Mistral-7B, and between $1.50times$ and $1.71times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
4/9/2024
💬
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, Daya Guo
0
0
Mathematical reasoning poses a significant challenge for language models due to its complex and structured nature. In this paper, we introduce DeepSeekMath 7B, which continues pre-training DeepSeek-Coder-Base-v1.5 7B with 120B math-related tokens sourced from Common Crawl, together with natural language and code data. DeepSeekMath 7B has achieved an impressive score of 51.7% on the competition-level MATH benchmark without relying on external toolkits and voting techniques, approaching the performance level of Gemini-Ultra and GPT-4. Self-consistency over 64 samples from DeepSeekMath 7B achieves 60.9% on MATH. The mathematical reasoning capability of DeepSeekMath is attributed to two key factors: First, we harness the significant potential of publicly available web data through a meticulously engineered data selection pipeline. Second, we introduce Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO), that enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO.
4/30/2024
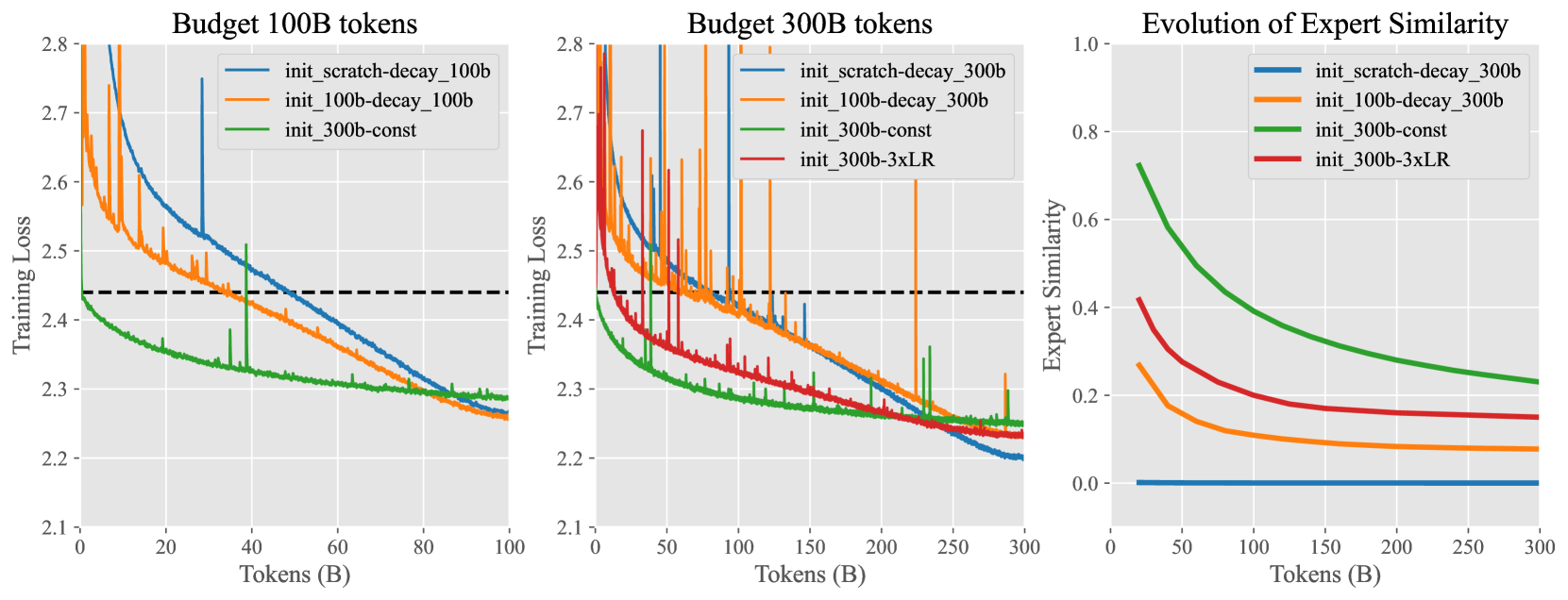
Skywork-MoE: A Deep Dive into Training Techniques for Mixture-of-Experts Language Models
Tianwen Wei, Bo Zhu, Liang Zhao, Cheng Cheng, Biye Li, Weiwei Lu, Peng Cheng, Jianhao Zhang, Xiaoyu Zhang, Liang Zeng, Xiaokun Wang, Yutuan Ma, Rui Hu, Shuicheng Yan, Han Fang, Yahui Zhou
0
0
In this technical report, we introduce the training methodologies implemented in the development of Skywork-MoE, a high-performance mixture-of-experts (MoE) large language model (LLM) with 146 billion parameters and 16 experts. It is initialized from the pre-existing dense checkpoints of our Skywork-13B model. We explore the comparative effectiveness of upcycling versus training from scratch initializations. Our findings suggest that the choice between these two approaches should consider both the performance of the existing dense checkpoints and the MoE training budget. We highlight two innovative techniques: gating logit normalization, which improves expert diversification, and adaptive auxiliary loss coefficients, allowing for layer-specific adjustment of auxiliary loss coefficients. Our experimental results validate the effectiveness of these methods. Leveraging these techniques and insights, we trained our upcycled Skywork-MoE on a condensed subset of our SkyPile corpus. The evaluation results demonstrate that our model delivers strong performance across a wide range of benchmarks.
6/12/2024