Skywork-MoE: A Deep Dive into Training Techniques for Mixture-of-Experts Language Models
2406.06563
0
0
Abstract
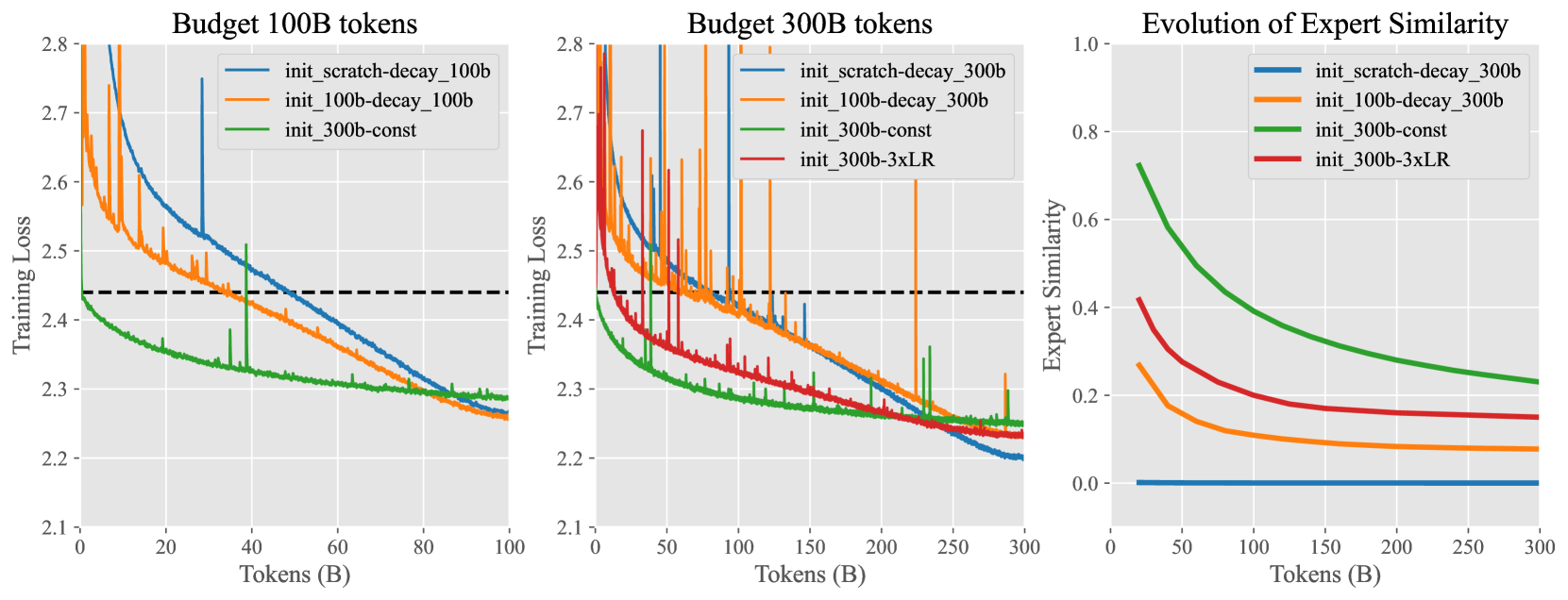
In this technical report, we introduce the training methodologies implemented in the development of Skywork-MoE, a high-performance mixture-of-experts (MoE) large language model (LLM) with 146 billion parameters and 16 experts. It is initialized from the pre-existing dense checkpoints of our Skywork-13B model. We explore the comparative effectiveness of upcycling versus training from scratch initializations. Our findings suggest that the choice between these two approaches should consider both the performance of the existing dense checkpoints and the MoE training budget. We highlight two innovative techniques: gating logit normalization, which improves expert diversification, and adaptive auxiliary loss coefficients, allowing for layer-specific adjustment of auxiliary loss coefficients. Our experimental results validate the effectiveness of these methods. Leveraging these techniques and insights, we trained our upcycled Skywork-MoE on a condensed subset of our SkyPile corpus. The evaluation results demonstrate that our model delivers strong performance across a wide range of benchmarks.
Create account to get full access
Overview
• This paper introduces Skywork-MoE, a novel training technique for Mixture-of-Experts (MoE) language models that aims to improve the efficiency and performance of these models.
• MoE models have shown promise in improving the capabilities of large language models by leveraging a divide-and-conquer approach, where different experts handle different types of tasks. However, effectively training these models can be challenging.
• The Skywork-MoE approach introduces several key innovations, including a specialized routing function, a more efficient expert selection mechanism, and techniques to encourage expert specialization. These advancements help address some of the limitations of previous MoE models, such as LocMoE, Not All Experts Are Equal, and Toward Inference-Optimal Mixture of Experts.
Plain English Explanation
The paper introduces a new way to train Mixture-of-Experts (MoE) language models, which are a type of AI model that divides the work among different "expert" components, each specializing in a different task. This can help make large language models more efficient and capable.
However, training MoE models can be challenging, so the researchers developed Skywork-MoE, which includes several key improvements. First, they created a specialized routing function to decide which expert should handle each input. They also found a more efficient way to select the experts, and used techniques to encourage the experts to specialize in different tasks.
These advancements help address some of the limitations of previous MoE models, making them more practical and effective. The goal is to unlock the full potential of MoE models and further improve the capabilities of large language AI systems.
Technical Explanation
The paper proposes the Skywork-MoE training technique for Mixture-of-Experts (MoE) language models. MoE models work by dividing the work among different "expert" components, each specializing in a different type of task. This allows the model to leverage the strengths of multiple experts to improve its overall performance and efficiency.
However, effectively training MoE models can be challenging. The Skywork-MoE approach introduces several key innovations to address this:
-
Specialized Routing Function: The paper introduces a specialized routing function that aims to more effectively match inputs to the appropriate experts. This helps improve the model's ability to leverage the specialized knowledge of each expert.
-
Efficient Expert Selection: Skywork-MoE uses a more efficient mechanism for selecting the experts to use for a given input. This helps reduce the computational overhead associated with expert selection.
-
Expert Specialization Techniques: The paper also introduces techniques to encourage the experts to specialize in different tasks. This helps ensure that each expert develops unique capabilities, rather than all experts trying to handle the same types of inputs.
These advancements build on previous MoE models, such as LocMoE, Not All Experts Are Equal, and Toward Inference-Optimal Mixture of Experts, aiming to make MoE models more practical and effective for real-world applications.
Critical Analysis
The paper presents a well-designed and carefully executed study on improving MoE training techniques. The Skywork-MoE approach addresses several key limitations of previous MoE models, and the experimental results demonstrate significant improvements in both efficiency and performance.
However, the paper does acknowledge some limitations and areas for further research. For example, the routing function and expert selection mechanisms, while more efficient than previous approaches, may still impose non-trivial computational overhead. Additionally, the paper does not explore the impacts of Skywork-MoE on the interpretability or explainability of the resulting models.
Further research could investigate ways to reduce the routing and expert selection overhead even further, as well as explore techniques to enhance the interpretability of Skywork-MoE models. Exploring the performance and robustness of Skywork-MoE on a wider range of language tasks and datasets would also be valuable.
Overall, the Skywork-MoE approach represents a significant advancement in MoE training techniques and has the potential to unlock new levels of efficiency and capability in large language models. The paper's insights and innovations provide a solid foundation for future research in this important area of AI.
Conclusion
The Skywork-MoE paper introduces a novel training technique for Mixture-of-Experts (MoE) language models that aims to improve their efficiency and performance. By developing a specialized routing function, a more efficient expert selection mechanism, and techniques to encourage expert specialization, the Skywork-MoE approach addresses several key limitations of previous MoE models.
The experimental results demonstrate the effectiveness of the Skywork-MoE approach, suggesting that it could be a valuable tool for building more capable and efficient large language models. Although the paper acknowledges some remaining challenges, such as the computational overhead of the routing and selection mechanisms, the insights and innovations presented in this work provide a solid foundation for future research in this important area of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
0
0
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
6/27/2024
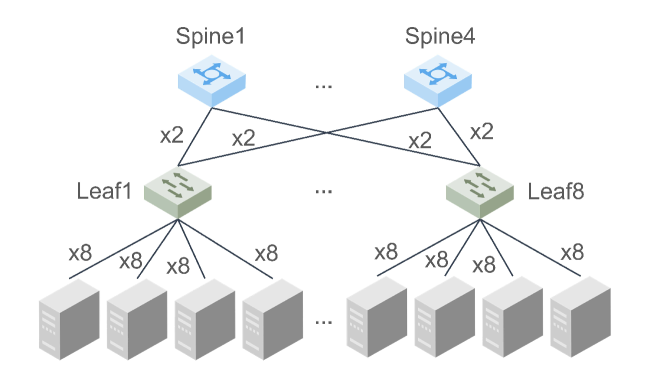
LocMoE: A Low-Overhead MoE for Large Language Model Training
Jing Li, Zhijie Sun, Xuan He, Li Zeng, Yi Lin, Entong Li, Binfan Zheng, Rongqian Zhao, Xin Chen
0
0
The Mixtures-of-Experts (MoE) model is a widespread distributed and integrated learning method for large language models (LLM), which is favored due to its ability to sparsify and expand models efficiently. However, the performance of MoE is limited by load imbalance and high latency of All-to-All communication, along with relatively redundant computation owing to large expert capacity. Load imbalance may result from existing routing policies that consistently tend to select certain experts. The frequent inter-node communication in the All-to-All procedure also significantly prolongs the training time. To alleviate the above performance problems, we propose a novel routing strategy that combines load balance and locality by converting partial inter-node communication to that of intra-node. Notably, we elucidate that there is a minimum threshold for expert capacity, calculated through the maximal angular deviation between the gating weights of the experts and the assigned tokens. We port these modifications on the PanGu-Sigma model based on the MindSpore framework with multi-level routing and conduct experiments on Ascend clusters. The experiment results demonstrate that the proposed LocMoE reduces training time per epoch by 12.68% to 22.24% compared to classical routers, such as hash router and switch router, without impacting the model accuracy.
5/24/2024

Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models
Xudong Lu, Qi Liu, Yuhui Xu, Aojun Zhou, Siyuan Huang, Bo Zhang, Junchi Yan, Hongsheng Li
0
0
A pivotal advancement in the progress of large language models (LLMs) is the emergence of the Mixture-of-Experts (MoE) LLMs. Compared to traditional LLMs, MoE LLMs can achieve higher performance with fewer parameters, but it is still hard to deploy them due to their immense parameter sizes. Different from previous weight pruning methods that rely on specifically designed hardware, this paper mainly aims to enhance the deployment efficiency of MoE LLMs by introducing plug-and-play expert-level sparsification techniques. Specifically, we propose, for the first time to our best knowledge, post-training approaches for task-agnostic and task-specific expert pruning and skipping of MoE LLMs, tailored to improve deployment efficiency while maintaining model performance across a wide range of tasks. Extensive experiments show that our proposed methods can simultaneously reduce model sizes and increase the inference speed, while maintaining satisfactory performance. Data and code will be available at https://github.com/Lucky-Lance/Expert_Sparsity.
5/31/2024
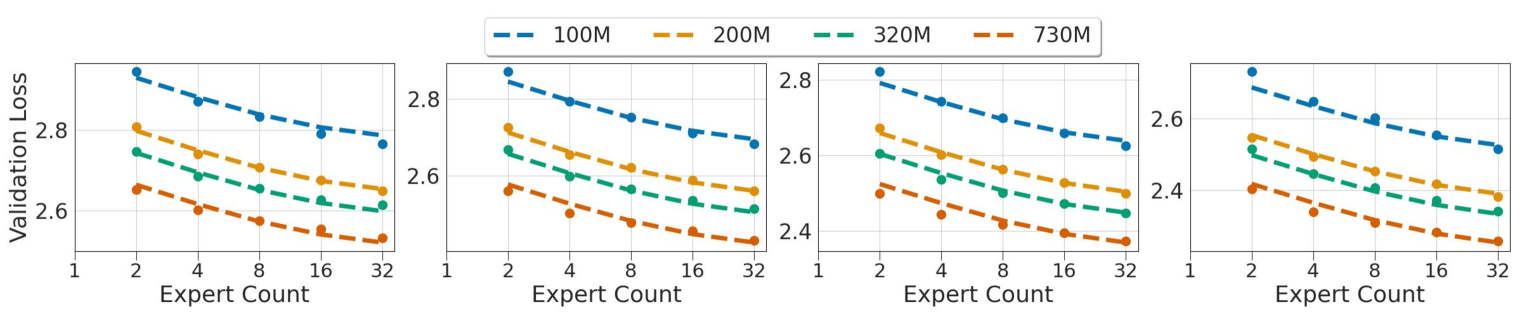
Toward Inference-optimal Mixture-of-Expert Large Language Models
Longfei Yun, Yonghao Zhuang, Yao Fu, Eric P Xing, Hao Zhang
0
0
Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
4/4/2024