Deformable 3D Shape Diffusion Model

0

Sign in to get full access
Overview
- Introduces a diffusion model for generating deformable 3D shapes
- Diffusion models have shown success in generating realistic 2D images, and this paper extends them to 3D shape modeling
- Proposed model can generate diverse and high-quality 3D shapes by learning from a dataset of 3D shapes
Plain English Explanation
The paper presents a diffusion model for generating deformable 3D shapes. Diffusion models are a type of machine learning technique that have been successful in generating realistic 2D images. This paper explores how to apply diffusion models to the task of 3D shape generation.
The key idea is to learn a diffusion process that can gradually transform a simple 3D shape, like a sphere, into more complex deformable 3D shapes by following a learned sequence of small transformations. By training the model on a dataset of 3D shapes, it can learn the patterns and structures that make up realistic 3D objects.
The advantage of this approach is that it can generate a diverse range of high-quality 3D shapes, going beyond the limitations of traditional 3D modeling techniques. The diffusion process allows for flexible and smooth deformations, enabling the model to capture the nuances of different 3D shapes.
Technical Explanation
The paper proposes a deformable 3D shape diffusion model that can generate diverse and high-quality 3D shapes by learning from a dataset of 3D shapes. The model follows a diffusion process, gradually transforming a simple 3D shape, like a sphere, into more complex deformable 3D shapes.
The key components of the model include:
-
Deformable 3D Shape Representation: The model represents 3D shapes using a set of control points that define the shape's surface. This allows for flexible and smooth deformations of the 3D shape.
-
Diffusion Process: The model learns a diffusion process that gradually transforms the initial 3D shape into more complex shapes. This involves a sequence of small, learned transformations that follow the patterns and structures observed in the training data.
-
Neural Network Architecture: The model uses a neural network architecture to parameterize the diffusion process. This allows the model to learn the necessary transformations from the 3D shape dataset.
Through extensive experiments, the authors demonstrate that the proposed diffusion model can generate diverse and high-quality 3D shapes that capture the complexity and nuances of real-world 3D objects. The model's ability to learn flexible deformations sets it apart from traditional 3D modeling techniques.
Critical Analysis
The paper presents a novel and promising approach to 3D shape generation using diffusion models. However, the authors acknowledge some limitations and areas for further research:
-
Dataset Dependence: The model's performance is highly dependent on the quality and diversity of the 3D shape dataset used for training. Expanding the dataset or using techniques to augment the data could further improve the model's capabilities.
-
Computational Complexity: The diffusion process can be computationally intensive, especially for generating high-resolution 3D shapes. Optimizing the model's efficiency or exploring alternative diffusion strategies could address this issue.
-
Evaluation Metrics: The paper primarily relies on qualitative assessments of the generated 3D shapes. Developing more robust quantitative metrics to evaluate the model's performance would strengthen the analysis.
-
Real-world Applications: While the paper demonstrates the model's potential in generating realistic 3D shapes, further research is needed to explore its practical applications, such as in 3D modeling, animation, or virtual reality.
Overall, the paper presents an exciting and innovative approach to 3D shape generation, with the potential to significantly impact various domains that rely on 3D modeling and synthesis.
Conclusion
The Deformable 3D Shape Diffusion Model introduces a novel technique for generating diverse and high-quality 3D shapes using a diffusion-based approach. By learning a flexible deformation process from a dataset of 3D shapes, the model can create realistic and diverse 3D objects, going beyond the limitations of traditional 3D modeling techniques.
The paper's contributions pave the way for further advancements in 3D shape generation, with potential applications in areas such as 3D modeling, animation, and virtual reality. While the model has some limitations, the authors' exploration of diffusion-based 3D shape generation represents an exciting step forward in the field of 3D shape synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deformable 3D Shape Diffusion Model
Dengsheng Chen, Jie Hu, Xiaoming Wei, Enhua Wu
The Gaussian diffusion model, initially designed for image generation, has recently been adapted for 3D point cloud generation. However, these adaptations have not fully considered the intrinsic geometric characteristics of 3D shapes, thereby constraining the diffusion model's potential for 3D shape manipulation. To address this limitation, we introduce a novel deformable 3D shape diffusion model that facilitates comprehensive 3D shape manipulation, including point cloud generation, mesh deformation, and facial animation. Our approach innovatively incorporates a differential deformation kernel, which deconstructs the generation of geometric structures into successive non-rigid deformation stages. By leveraging a probabilistic diffusion model to simulate this step-by-step process, our method provides a versatile and efficient solution for a wide range of applications, spanning from graphics rendering to facial expression animation. Empirical evidence highlights the effectiveness of our approach, demonstrating state-of-the-art performance in point cloud generation and competitive results in mesh deformation. Additionally, extensive visual demonstrations reveal the significant potential of our approach for practical applications. Our method presents a unique pathway for advancing 3D shape manipulation and unlocking new opportunities in the realm of virtual reality.
Read more8/1/2024
0
Neural Point Cloud Diffusion for Disentangled 3D Shape and Appearance Generation
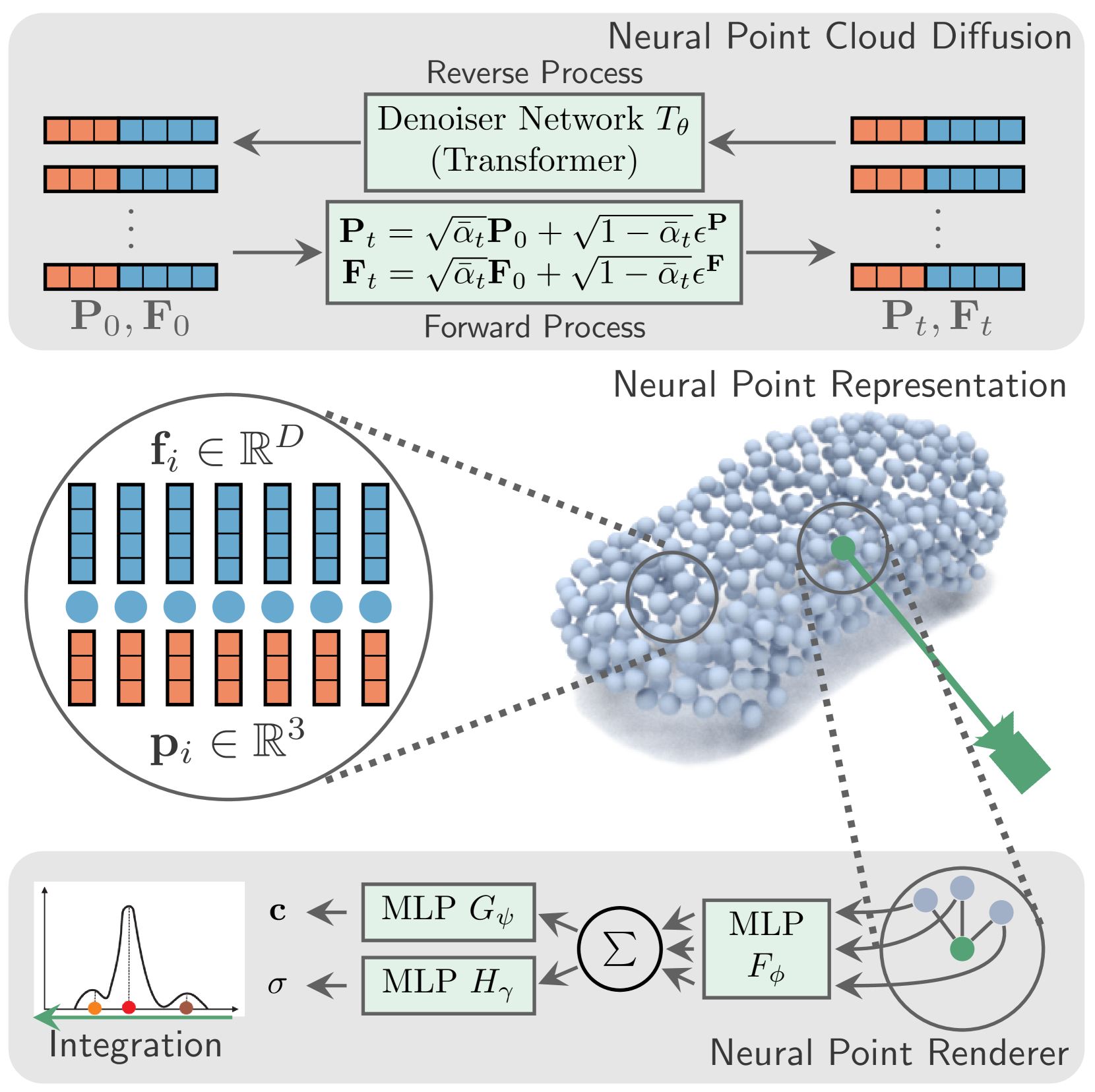
Philipp Schroppel, Christopher Wewer, Jan Eric Lenssen, Eddy Ilg, Thomas Brox
Controllable generation of 3D assets is important for many practical applications like content creation in movies, games and engineering, as well as in AR/VR. Recently, diffusion models have shown remarkable results in generation quality of 3D objects. However, none of the existing models enable disentangled generation to control the shape and appearance separately. For the first time, we present a suitable representation for 3D diffusion models to enable such disentanglement by introducing a hybrid point cloud and neural radiance field approach. We model a diffusion process over point positions jointly with a high-dimensional feature space for a local density and radiance decoder. While the point positions represent the coarse shape of the object, the point features allow modeling the geometry and appearance details. This disentanglement enables us to sample both independently and therefore to control both separately. Our approach sets a new state of the art in generation compared to previous disentanglement-capable methods by reduced FID scores of 30-90% and is on-par with other non disentanglement-capable state-of-the art methods.
Read more8/1/2024
🛸
0
TetraDiffusion: Tetrahedral Diffusion Models for 3D Shape Generation
Nikolai Kalischek, Torben Peters, Jan D. Wegner, Konrad Schindler
Probabilistic denoising diffusion models (DDMs) have set a new standard for 2D image generation. Extending DDMs for 3D content creation is an active field of research. Here, we propose TetraDiffusion, a diffusion model that operates on a tetrahedral partitioning of 3D space to enable efficient, high-resolution 3D shape generation. Our model introduces operators for convolution and transpose convolution that act directly on the tetrahedral partition, and seamlessly includes additional attributes such as color. Remarkably, TetraDiffusion enables rapid sampling of detailed 3D objects in nearly real-time with unprecedented resolution. It's also adaptable for generating 3D shapes conditioned on 2D images. Compared to existing 3D mesh diffusion techniques, our method is up to 200 times faster in inference speed, works on standard consumer hardware, and delivers superior results.
Read more8/12/2024
📈
0
4D Facial Expression Diffusion Model
Kaifeng Zou, Sylvain Faisan, Boyang Yu, S'ebastien Valette, Hyewon Seo
Facial expression generation is one of the most challenging and long-sought aspects of character animation, with many interesting applications. The challenging task, traditionally having relied heavily on digital craftspersons, remains yet to be explored. In this paper, we introduce a generative framework for generating 3D facial expression sequences (i.e. 4D faces) that can be conditioned on different inputs to animate an arbitrary 3D face mesh. It is composed of two tasks: (1) Learning the generative model that is trained over a set of 3D landmark sequences, and (2) Generating 3D mesh sequences of an input facial mesh driven by the generated landmark sequences. The generative model is based on a Denoising Diffusion Probabilistic Model (DDPM), which has achieved remarkable success in generative tasks of other domains. While it can be trained unconditionally, its reverse process can still be conditioned by various condition signals. This allows us to efficiently develop several downstream tasks involving various conditional generation, by using expression labels, text, partial sequences, or simply a facial geometry. To obtain the full mesh deformation, we then develop a landmark-guided encoder-decoder to apply the geometrical deformation embedded in landmarks on a given facial mesh. Experiments show that our model has learned to generate realistic, quality expressions solely from the dataset of relatively small size, improving over the state-of-the-art methods. Videos and qualitative comparisons with other methods can be found at url{https://github.com/ZOUKaifeng/4DFM}.
Read more4/16/2024