Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion Models
2406.08475
0
0

Abstract
Creating realistic avatars from a single RGB image is an attractive yet challenging problem. Due to its ill-posed nature, recent works leverage powerful prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot provide multi-view shape priors with guaranteed 3D consistency. We propose Human 3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion. Our key insight is that 2D multi-view diffusion and 3D reconstruction models provide complementary information for each other, and by coupling them in a tight manner, we can fully leverage the potential of both models. We introduce a novel image-conditioned generative 3D Gaussian Splats reconstruction model that leverages the priors from 2D multi-view diffusion models, and provides an explicit 3D representation, which further guides the 2D reverse sampling process to have better 3D consistency. Experiments show that our proposed framework outperforms state-of-the-art methods and enables the creation of realistic avatars from a single RGB image, achieving high-fidelity in both geometry and appearance. Extensive ablations also validate the efficacy of our design, (1) multi-view 2D priors conditioning in generative 3D reconstruction and (2) consistency refinement of sampling trajectory via the explicit 3D representation. Our code and models will be released on https://yuxuan-xue.com/human-3diffusion.
Create account to get full access
Overview
• This research paper introduces a novel approach called "Human 3Diffusion" for generating realistic 3D human avatars from a single input image.
• The key idea is to leverage diffusion models, a type of generative AI, to create 3D-consistent avatars that maintain the visual fidelity and proportions of the original image.
• The method enables the creation of high-quality 3D human avatars that can be used in various applications, such as virtual reality, gaming, and social media.
Plain English Explanation
The paper presents a new way to create realistic 3D digital versions, or avatars, of people from a single photograph. The researchers used a special kind of machine learning called "diffusion models" to achieve this.
Diffusion models work by starting with random noise and gradually transforming it into something more structured, like an image. In this case, the researchers trained the diffusion model to take a 2D photo and turn it into a 3D avatar that accurately captures the person's appearance and proportions.
This is a significant advancement because creating high-quality 3D avatars typically requires specialized 3D modeling skills or multiple input images. The "Human 3Diffusion" approach makes it much easier to generate realistic 3D avatars from just a single photograph.
The resulting avatars can be used in virtual reality, video games, social media, and other applications where realistic 3D representations of people are needed. This could make it simpler and more accessible to create personalized 3D characters and environments.
Technical Explanation
The researchers propose a novel method called "Human 3Diffusion" that leverages diffusion models to generate 3D-consistent human avatars from a single input image.
Diffusion models are a type of generative AI that can transform random noise into structured outputs, like images. The key innovation in this work is using diffusion models to explicitly model the 3D geometry and texture of a human face and body, while maintaining visual consistency with the original 2D input image.
The architecture includes separate diffusion models for 3D shape, appearance, and pose, which are trained jointly to ensure the generated avatars are coherent and visually realistic. This builds upon prior work on instant 3D avatar generation and robust 3D facial reconstruction.
To scale to diverse body shapes and poses, the researchers also introduce a multi-view diffusion approach that can generate 3D avatars from multiple views. This allows the model to capture the full 3D structure of the human form.
Critical Analysis
The paper presents a compelling approach for generating high-quality 3D human avatars from a single input image. The use of diffusion models is a novel and promising direction, as it allows for the explicit modeling of 3D shape, appearance, and pose in a coherent manner.
However, the authors acknowledge some limitations of the current work. For example, the avatars may not fully capture subtle details like facial expressions or complex clothing. There is also room for improving the realism and diversity of the generated 3D models.
Additionally, the ethical implications of such technology should be carefully considered. While the authors mention potential applications in virtual worlds and entertainment, there are valid concerns around the misuse of realistic avatar generation for deepfakes or other deceptive purposes.
Further research is needed to address these limitations and ensure the responsible development of this technology. Exploring ways to improve the fidelity, controllability, and safety of the generated avatars would be valuable next steps.
Conclusion
The "Human 3Diffusion" approach presented in this paper represents a significant advancement in the field of 3D avatar creation. By leveraging diffusion models, the researchers have demonstrated the ability to generate high-quality, 3D-consistent human avatars from a single input image.
This technology has the potential to revolutionize various applications, such as virtual reality, gaming, and social media, by making it easier and more accessible to create personalized 3D characters and environments.
However, it is crucial that the development of such technologies is accompanied by careful consideration of the ethical implications and potential misuse. Ongoing research and responsible deployment will be key to ensuring that the benefits of this technology are realized while mitigating potential harms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Morphable Diffusion: 3D-Consistent Diffusion for Single-image Avatar Creation
Xiyi Chen, Marko Mihajlovic, Shaofei Wang, Sergey Prokudin, Siyu Tang
0
0
Recent advances in generative diffusion models have enabled the previously unfeasible capability of generating 3D assets from a single input image or a text prompt. In this work, we aim to enhance the quality and functionality of these models for the task of creating controllable, photorealistic human avatars. We achieve this by integrating a 3D morphable model into the state-of-the-art multi-view-consistent diffusion approach. We demonstrate that accurate conditioning of a generative pipeline on the articulated 3D model enhances the baseline model performance on the task of novel view synthesis from a single image. More importantly, this integration facilitates a seamless and accurate incorporation of facial expression and body pose control into the generation process. To the best of our knowledge, our proposed framework is the first diffusion model to enable the creation of fully 3D-consistent, animatable, and photorealistic human avatars from a single image of an unseen subject; extensive quantitative and qualitative evaluations demonstrate the advantages of our approach over existing state-of-the-art avatar creation models on both novel view and novel expression synthesis tasks. The code for our project is publicly available.
4/3/2024

Instant 3D Human Avatar Generation using Image Diffusion Models
Nikos Kolotouros, Thiemo Alldieck, Enric Corona, Eduard Gabriel Bazavan, Cristian Sminchisescu
0
0
We present AvatarPopUp, a method for fast, high quality 3D human avatar generation from different input modalities, such as images and text prompts and with control over the generated pose and shape. The common theme is the use of diffusion-based image generation networks that are specialized for each particular task, followed by a 3D lifting network. We purposefully decouple the generation from the 3D modeling which allow us to leverage powerful image synthesis priors, trained on billions of text-image pairs. We fine-tune latent diffusion networks with additional image conditioning to solve tasks such as image generation and back-view prediction, and to support qualitatively different multiple 3D hypotheses. Our partial fine-tuning approach allows to adapt the networks for each task without inducing catastrophic forgetting. In our experiments, we demonstrate that our method produces accurate, high-quality 3D avatars with diverse appearance that respect the multimodal text, image, and body control signals. Our approach can produce a 3D model in as few as 2 seconds, a four orders of magnitude speedup w.r.t. the vast majority of existing methods, most of which solve only a subset of our tasks, and with fewer controls, thus enabling applications that require the controlled 3D generation of human avatars at scale. The project website can be found at https://www.nikoskolot.com/avatarpopup/.
6/12/2024
✨
FitDiff: Robust monocular 3D facial shape and reflectance estimation using Diffusion Models
Stathis Galanakis, Alexandros Lattas, Stylianos Moschoglou, Stefanos Zafeiriou
0
0
The remarkable progress in 3D face reconstruction has resulted in high-detail and photorealistic facial representations. Recently, Diffusion Models have revolutionized the capabilities of generative methods by surpassing the performance of GANs. In this work, we present FitDiff, a diffusion-based 3D facial avatar generative model. Leveraging diffusion principles, our model accurately generates relightable facial avatars, utilizing an identity embedding extracted from an in-the-wild 2D facial image. The introduced multi-modal diffusion model is the first to concurrently output facial reflectance maps (diffuse and specular albedo and normals) and shapes, showcasing great generalization capabilities. It is solely trained on an annotated subset of a public facial dataset, paired with 3D reconstructions. We revisit the typical 3D facial fitting approach by guiding a reverse diffusion process using perceptual and face recognition losses. Being the first 3D LDM conditioned on face recognition embeddings, FitDiff reconstructs relightable human avatars, that can be used as-is in common rendering engines, starting only from an unconstrained facial image, and achieving state-of-the-art performance.
6/5/2024
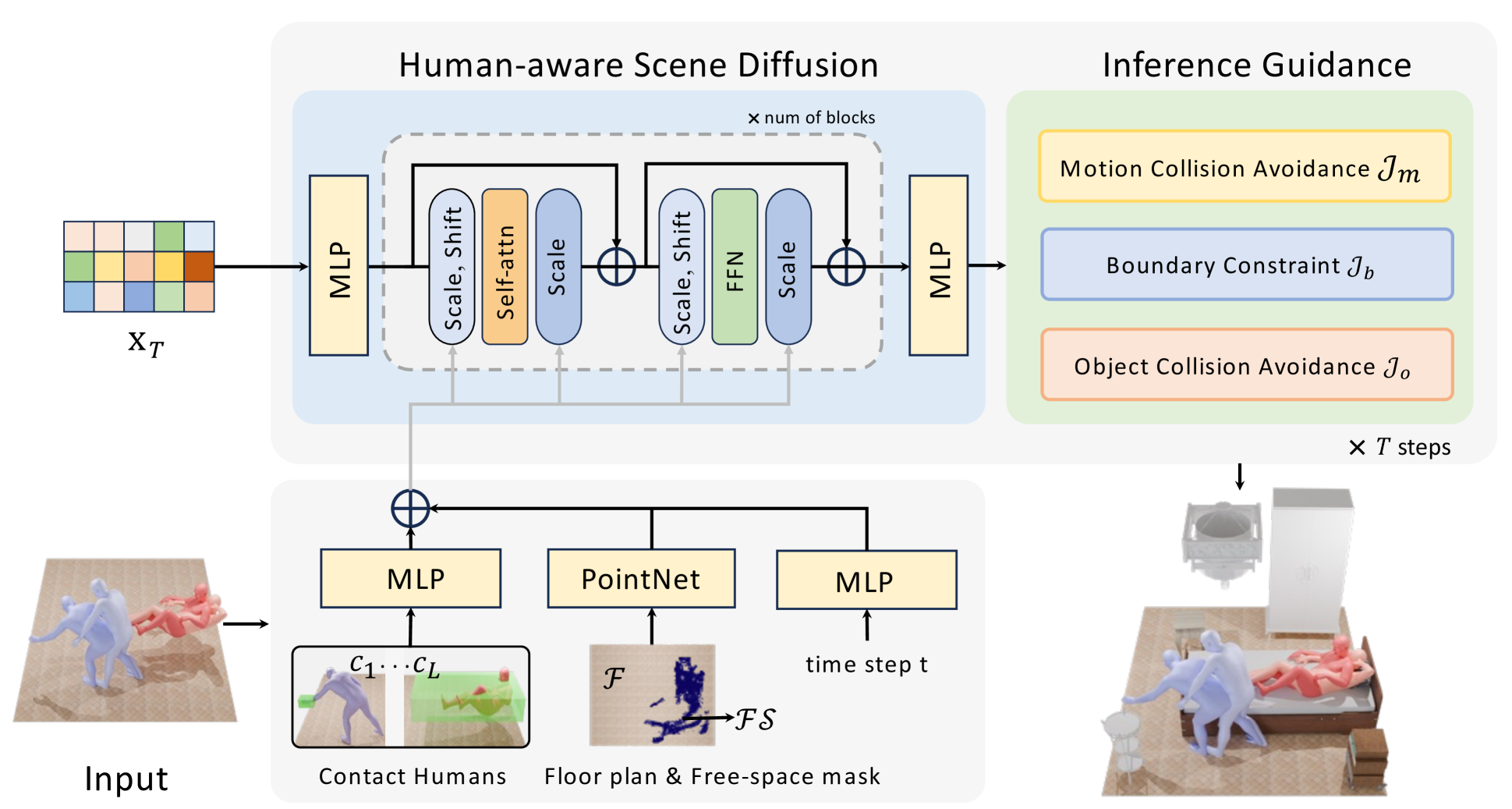
Human-Aware 3D Scene Generation with Spatially-constrained Diffusion Models
Xiaolin Hong, Hongwei Yi, Fazhi He, Qiong Cao
0
0
Generating 3D scenes from human motion sequences supports numerous applications, including virtual reality and architectural design. However, previous auto-regression-based human-aware 3D scene generation methods have struggled to accurately capture the joint distribution of multiple objects and input humans, often resulting in overlapping object generation in the same space. To address this limitation, we explore the potential of diffusion models that simultaneously consider all input humans and the floor plan to generate plausible 3D scenes. Our approach not only satisfies all input human interactions but also adheres to spatial constraints with the floor plan. Furthermore, we introduce two spatial collision guidance mechanisms: human-object collision avoidance and object-room boundary constraints. These mechanisms help avoid generating scenes that conflict with human motions while respecting layout constraints. To enhance the diversity and accuracy of human-guided scene generation, we have developed an automated pipeline that improves the variety and plausibility of human-object interactions in the existing 3D FRONT HUMAN dataset. Extensive experiments on both synthetic and real-world datasets demonstrate that our framework can generate more natural and plausible 3D scenes with precise human-scene interactions, while significantly reducing human-object collisions compared to previous state-of-the-art methods. Our code and data will be made publicly available upon publication of this work.
6/27/2024